Paper:
Analyzing the Seven Critical Elements of Life Recovery Using News: A Case Study of the 2024 Noto Peninsula Earthquake
Yen-Ching Liu*
 and Shosuke Sato**,†
and Shosuke Sato**,†
*COLABS Program, Tohoku University
41 Kawauchi, Aoba-ku, Sendai, Miyagi 980-8576, Japan
**International Research Institute of Disaster Science, Tohoku University
Sendai, Japan
†Corresponding author

A significant earthquake impacted the Noto Peninsula on January 1, 2024, and recovery efforts have been ongoing since then. News media articles offer valuable perspectives on the recovery process. To better understand the recovery situation and its evolution from a news media perspective, this study analyzes Yahoo! Japan News articles on the Noto Peninsula earthquake posted between August 2024 and July 2025. Using natural language processing (NLP) by keyword-based and Generative Pre-trained Transformer-based approaches with statistical analysis, the Seven Critical Elements of Life Recovery, as well as sentiments and city names, are identified in the articles. Further studies, including one-way analysis of variance with Tukey’s honestly significant difference test and ordinary least squares regression, are conducted to identify differences and changes in volume and sentiment toward recovery elements and locations. Results reveal that both the volume and sentiment vary across recovery elements and differ between cities. However, most cases do not demonstrate a significant trend in either volume or sentiment over time. This suggests that there may be diversity in recovery-related news coverage within the affected region, while most exhibit no changes or linear trends. Overall, this study develops a process to extract structured disaster recovery data from news texts using NLP, providing a comprehensive understanding of disaster recovery in the Noto Peninsula from a news perspective.
1. Introduction
Natural disasters have a profound impact on Japanese society. Each year, disasters such as heavy rainfall and earthquakes trigger flooding, landslides, tsunamis, and other destructive hazards that damage infrastructure, disrupt housing, and cause casualties. When facing a disaster, disaster management, which encompasses preparedness, response, recovery, and mitigation, is crucial for minimizing loss and damage 1. Recovery is a vital phase after a disaster and is defined as the restoration or improvement of livelihoods, health, and socioeconomic, cultural, and environmental systems of communities affected by the disaster 2. It focuses on sustainable development and the principle of building back better to minimize future risks 2. Moreover, recovery efforts directly impact the lives of those affected, making them an essential aspect of post-disaster responses.
To understand recovery situations, social surveys such as questionnaires, interviews, and demographic surveys are commonly used to actively collect data. These surveys feature first-hand data gathered directly from residents. However, such surveys require time, personnel, and resources. Passive data collection, including information from news and social media, is crucial because it can provide diverse viewpoints and valuable insights for analyzing disaster recovery situations. In particular, news media can provide disaster information from a social perspective 3. Additionally, such data offer textual material that helps us understand disaster information as a social phenomenon 4. Such data can capture diverse perspectives, reflect spontaneous public discourse, and serve as a significant resource for analyzing the evolving situation of disaster recovery.
Using textual materials from media sources to track recovery progress is a common approach in disaster studies. For example, the restoration of infrastructure such as water supply, shelter, electricity, communication, and transportation is often assessed by classifying content using predefined keywords and machine learning methods 5,6. The need for goods and donations can be identified 7. Furthermore, insights into the recovery of economic activities such as tourism can be found 8. Sentiment analysis has also been used to capture people’s feelings toward recovery, typically through machine learning approaches 5,8,9,10. However, these methods tend to focus primarily on material aspects and people’s opinions about them. Recognition of the non-material aspects of recovery, such as mental states and social relations with others, remains insufficient. Moreover, in previous studies, the analysis period often spanned approximately one week, overlapping the disaster response period and time after the disaster 5,6, and therefore only covered the short-term recovery period 11. This short span may be insufficient to capture the entire recovery process, as long-term recovery involves strengthening resilience and reducing vulnerability of the community, which may continue for many years 11.
The Seven Critical Elements of Life Recovery model includes both material and social aspects: housing, social ties, townscape, physical and mental health, preparedness, relation to government, and economic and financial situation 12. This framework offers a more comprehensive basis for addressing the diverse aspects of recovery. Previous studies applied this model to identify factors influencing life recovery scores, primarily using quantitative data and statistical analysis 12,13,14. However, no study has applied the Seven Critical Elements of Life Recovery framework to analyze textual materials, such as news articles, to examine recovery conditions.
In addition to identifying recovery elements, identifying locations in disaster-related texts is essential, as the extent of disaster impact often varies by geographic area and is influenced by differences in local government policies. By extracting place names from texts, previous studies could identify locations with rescue needs or greater disruption, receive the most attention during disasters, and determine which aspects of the disaster situation are emphasized in different places 6,15,16. Nevertheless, there is a lack of in-depth analysis and practical application of location-based information in long-term recovery analysis, leaving a gap in understanding the spatial dimension of post-disaster recovery discourse.
On January 1, 2024, a powerful earthquake with a magnitude of 7.6 struck the Noto Peninsula, resulting in 672 casualties, extensive damage, and significant economic losses 17. Even months later, substantial damage remains, highlighting the importance of understanding and monitoring the recovery processes. To understand the recovery conditions in the Noto Peninsula and address the research gap, this study aims to analyze how the recovery process of the 2024 Noto Peninsula earthquake was represented in news media over a one-year period. Applying the Seven Critical Elements of Life Recovery framework with place-name analysis over a relatively long period, this study aims to provide a more comprehensive understanding of recovery-related discourse from a media perspective, capturing both the thematic focus and geographic distribution of reporting on the Noto Peninsula earthquake.
2. Methods
This study proposes a procedure for extracting representative structured information from texts and understanding the disclosure of recovery situations in the Noto Peninsula through news. The procedure comprises four steps:
-
(1)
Data collection, in which textual news articles are collected from the Yahoo! News website using a web crawler.
-
(2)
Text preprocessing, in which text cleaning and paragraph splitting are included to make the text more suitable for analysis.
-
(3)
Natural language processing (NLP), in which four NLP tasks, including related paragraph detection, recovery element identification, location recognition, and sentiment analysis, are used to convert textual information into structured data.
-
(4)
Analysis, in which the data obtained by NLP are used to calculate and analyze variables using statistical methods to understand recovery situations.
The details of each component are presented in Sections 2.1–2.4.
2.1. Data Collection
This study uses Yahoo! Japan News 18, a major web news platform in Japan that provides various news media sources. As material for understanding the recovery situation in the Noto Peninsula, the news articles are retrieved automatically through a self-developed web crawler using the keyword “Noto Peninsula earthquake (能登半島地震) + Recovery (復興)” in Japanese.
2.2. Text Preprocessing
Text preprocessing in this study involves two chief steps: text cleaning and paragraph splitting. Text cleaning focuses on removing unnecessary or noisy elements from the text, such as repeated spaces, redundant punctuation marks, and other irrelevant characters that may interfere with the analysis. Paragraph splitting then divides the cleaned text into smaller units, called paragraphs in this study, based on “end-of-line” symbols and the period, as found in the collected articles. This step ensures that the text is segmented into appropriate lengths, making it more suitable for subsequent NLP tasks and improving the accuracy and efficiency of further analyses.
2.3. Natural Language Processing
Textual data must be converted into numerical data for further quantitative analysis. A five-component expression for describing opinions in a document has been proposed: related entity, aspect, sentiment, opinion holder, and time 19. This framework is applied and revised to assist in capturing the recovery situations. Using paragraphs as processing units, the keywords related to the recovery elements (as an entity in 19), types of recovery elements (as an aspect in 19), sentiment, time, and place names mentioned in the paragraph are identified. Here, time indicates when a paragraph was posted. A place name component is added to link location to opinion. The opinion holder is assumed to be the same, namely the news media, for all the paragraphs.
To identify these components in all paragraphs, four NLP tasks are employed: related paragraph detection, recovery element identification, location recognition, and sentiment analysis. For each task, both keyword-based and Generative Pre-trained Transformer (GPT)-based approaches are applied, and the model with better performance is selected for use. In the keyword-based method, the task is performed according to a predefined dictionary of related keywords. The GPT-based method is employed as an exploratory tool to identify potential patterns rather than to establish causal relationships using the GPT-4o model via the OpenAI application programming interface 20. The prompt includes instructions for the NLP task, input structure, expected output format, and examples of few-shot learning. Appendix A provides the full text of the prompts.
2.3.1. Related Paragraph Detection
Related paragraphs should be first filtered. For the keyword-based approach, paragraphs containing the keywords Noto (能登) and recovery (復興) are identified and extracted as related paragraphs. Prompts for the GPT-based approach are presented in Appendix A.1. Only the related paragraphs are included in the dataset for further analysis.
2.3.2. Recovery Elements Identification
This task involves identifying the seven recovery elements in the text by finding the related keywords and types of recovery elements in the paragraphs using a keyword-based method. Identification is performed by comparing the content with a pre-constructed dictionary built from relevant news articles and previous recovery studies. Appendix B lists the keywords used for the seven recovery elements. The prompts for the GPT-based approach are presented in Appendix A.2.
2.3.3. Location Recognition
The goal of this task is to identify 12 cities in Ishikawa Prefecture on the Noto Peninsula by matching place names. Only the keyword-based method is applied, as there is no need to use the GPT-based method. The cities include Suzu-shi (珠洲市), Wajima-shi (輪島市), Noto-cho (能登町), Anamizu-machi (穴水町), Shika-machi (志賀町), Nanao-shi (七尾市), Nakanoto-machi (中能登町), Hakui-shi (羽咋市), Hodatsushimizu-cho (宝達志水町), Kahoku-shi (かほく市), Uchinada-machi (内灘町), and Tsubata-machi (津幡町), as illustrated in Fig. 1.
Fig. 1. Research area: the 12 cities for analysis.
Table 1. Formulas and meaning of variables.

2.3.4. Sentiment Analysis
To capture the sentiment in the paragraphs, sentiment analysis is applied to classify them into three categories: positive, negative, and neutral. As the GPT-based method achieves excellent performance and the keyword-based method is time-consuming, only the GPT-based method is used. The prompt is presented in Appendix A.3.
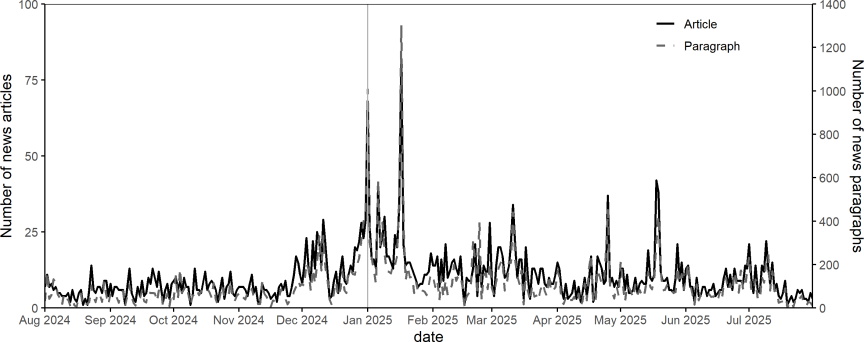
Fig. 2. Time series of the number of news articles and paragraphs.
2.4. Analysis
Three variables are calculated by month: recovery element ratio, positive sentiment ratio, and negative sentiment ratio, which represent the level of attention to an element, the level of positive sentiment expressed toward an element, and the level of negative sentiment expressed toward an element, respectively. The formulas and meanings of each variable are listed in Table 1.
After obtaining the variables, one-way analysis of variance (ANOVA) is conducted, followed by Tukey’s honestly significant difference (HSD) test. This analysis helps clarify the overall situation during the study period and determine whether there are any significant differences among recovery elements and among cities. Furthermore, ordinary least squares (OLS) regression is used to examine how volume and sentiment change over time for different recovery elements and cities, thereby identifying temporal patterns and trends in media attention and sentiment.
3. Results and Discussion
This section presents the results of this study, including dataset description, model performance on NLP tasks, and volume and sentiment analyses.
A total of 39,175 paragraphs (from 3,741 posts) were collected from August 1, 2024, to July 31, 2025. Fig. 2 presents the time series of the number of articles and paragraphs. Two prominent peaks are observed. The second-highest peak, indicated by the vertical gray dotted line, occurs on January 1, 2025, marking the first anniversary of the Noto Peninsula earthquake. The highest peak corresponds to January 17, 2025, 30 years after the Great Hanshin-Awaji Earthquake on January 17, 1995, which was associated with increased discussion of Noto and recovery.
The detailed dataset counts under various conditions are presented below. The number of related paragraphs is 11,149 (28.5%). The number of paragraphs including recovery elements is 6,261 (16.0%). The number of paragraphs including city names is 2,282 (5.8%). Notably, only 1,361 paragraphs (3.5%) include both recovery elements and city names, representing a relatively small proportion of the overall dataset.
Regarding the number of related paragraphs by month presented in Fig. 3, January 2025 has the most paragraphs (\(n=\textrm{2,100}\)), primarily because of the high level of discussion following the first anniversary of the earthquake. Regarding the number of related paragraphs counted by recovery elements, the economic and financial situation (\(n=\textrm{3,042}\)) and relation to government (\(n=\textrm{2,735}\)) have the two highest counts, as presented in Fig. 4. Regarding the number of related paragraphs by city, Wajima-shi, Nanao-shi, Suzu-shi, and Noto-cho clearly have higher counts than the other eight cities (Fig. 5). Therefore, the following analysis includes only the top four cities because of the small sample sizes for the other eight cities.
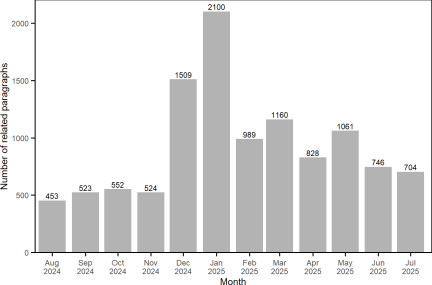
Fig. 3. Number of related paragraphs by month.
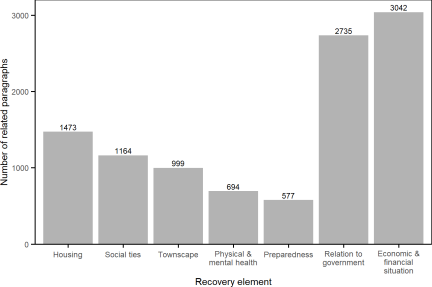
Fig. 4. Number of related paragraphs by recovery element.
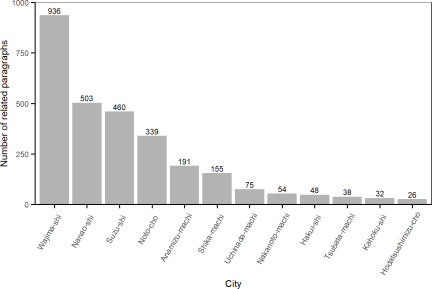
Fig. 5. Number of related paragraphs by city.
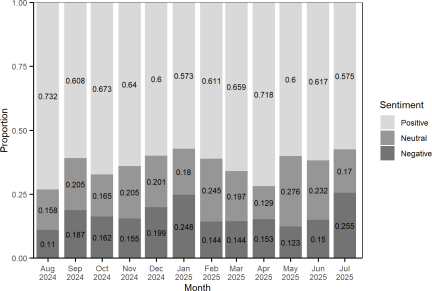
Fig. 6. Proportion of sentiment categories for related paragraphs by month.
Figure 6 illustrates the monthly proportions of related paragraphs with positive, neutral, and negative sentiments, irrespective of the recovery elements. Overall, the proportions of sentiment categories remained relatively stable throughout the study period, with an average ratio of approximately \(6.2:2.0:1.8\) for positive, neutral, and negative counts, respectively. This indicates that positive sentiment paragraphs are the most prevalent in news coverage, followed by neutral and negative sentiment paragraphs. This pattern suggests that news media tend to report recovery-related topics with an optimistic attitude compared with the other two sentiment types.
3.1. Model Performance
Four NLP tasks are used in this study, as described in Section 2.3. A partial dataset with 416 records (332 training records and 84 testing records) is randomly selected and applied to two methods, keyword-based and GPT-based, to determine which performed better.
Table 2. Performance comparison of keyword-based and GPT-based methods for NLP tasks. (– means that the method is not used; P represents precision; R represents recall; and F1 represents f1-score.)

Table 3. Validation of the GPT-based method.

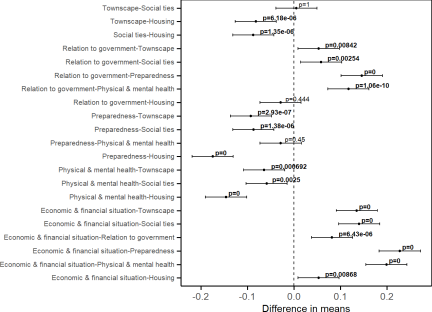
Fig. 7. Tukey’s HSD test results for volume.
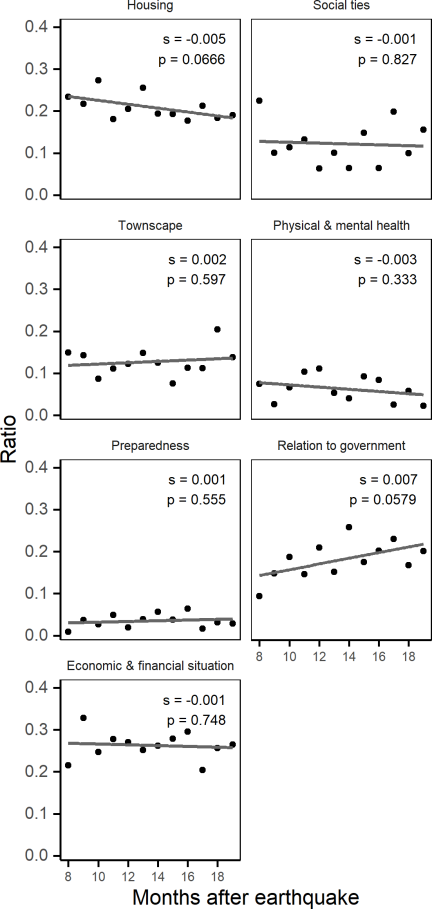
Fig. 8. Changes in recovery-element volume over time.
The performance of the two methods is listed in Table 2. The keyword-based method performs better on the first and second tasks, which may be because these two tasks are too domain-specific and relatively complex for GPT. To validate the reliability of the GPT-based method, Cohen’s \(\kappa\) is applied. Table 3 presents the validation of the GPT-4o model by calculating Cohen’s \(\kappa\) between GPT-4o predictions and human annotations on a sampled subset of 50 paragraphs. Only sentiment analysis yields high \(\kappa\), demonstrating that the GPT-based method is reliable for this task.
3.2. Analysis of Volume
The ANOVA results reveal that recovery volume varies significantly across recovery elements (\(p\)-value of \(2.0 \times 10^{-16}\)), indicating differing levels of media attention. Results from Tukey’s HSD test confirm that the economic and financial situation, housing, and relation to government are consistently higher than other recovery elements (Fig. 7). This may indicate that news is generally more concerned with issues such as the economic impact of the disaster, reconstruction and availability of housing, and the actions and responsibilities of government authorities.
Figure 8 illustrates the results of the OLS analysis for each recovery element over the 12-month period. No significant cases are observed, indicating no apparent linear increase or decrease in the recovery elements.
Overall, there is no significant trend in volume by recovery element and city in most cases, as presented in Fig. 9. However, some trends are observed.
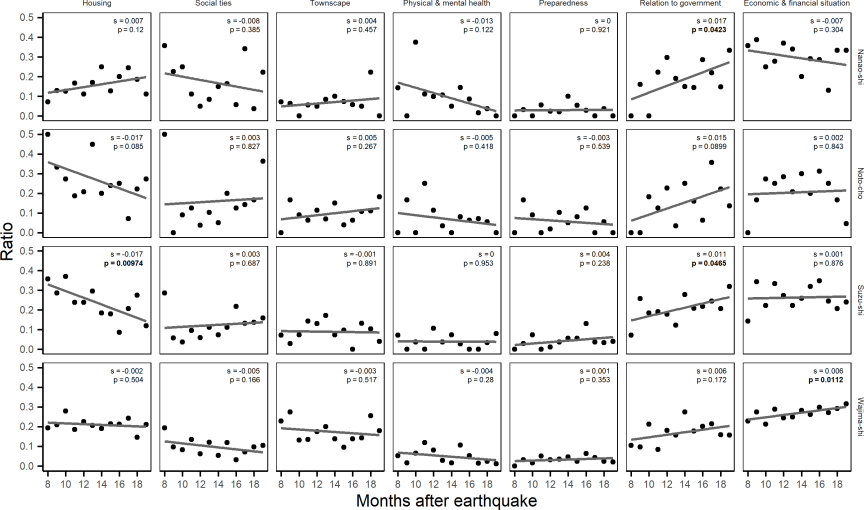
Fig. 9. Changes in recovery-element by cities over time.
3.3. Analysis of Sentiment
Regarding the sentiment level among different recovery elements, the positive and negative sentiment ratios are both significant for the ANOVA test, with \(p\)-values of \(2.7 \times 10^{-10}\) and \(3.5 \times 10^{-8}\), indicating that the sentiment toward the elements is not the same. Furthermore, according to Tukey’s HSD test results (Fig. 10), the recovery elements of housing and townscape exhibit lower positive and higher negative sentiment levels than the other recovery elements, suggesting a more negative attitude toward these two elements of the recovery situation.
Regarding the level of sentiment regarding places, there are significant differences among cities, both for positive and negative sentiments, with \(p\)-values of \(1.4 \times 10^{-2}\) and \(6.9 \times 10^{-5}\) for the ANOVA test, respectively. In particular, Nanao-shi has a significantly lower negative sentiment level than other cities, suggesting relatively less negative media coverage of the recovery process in Nanao-shi, as presented in Fig. 11.
Figure 12 illustrates the results of the OLS analysis for positive and negative sentiments for each recovery element. All recovery elements yield non-significant coefficients, indicating no clear trend in sentiment over the study period. Thus, the sentiments expressed toward each recovery element demonstrate no significant linear trend and remain generally stable.
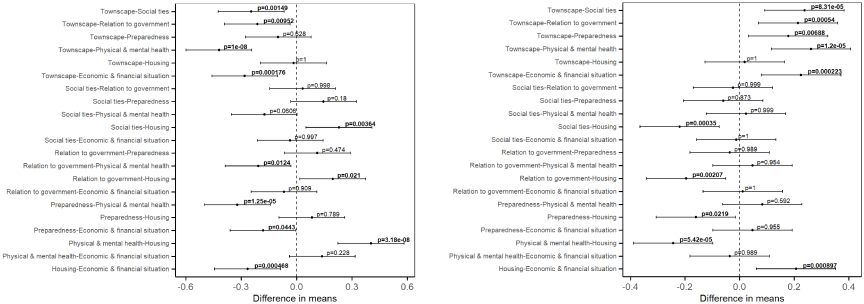
Fig. 10. Tukey’s HSD test results for sentiments among recovery elements. The left presents the result for positive sentiment ratio, and the right presents the result for negative sentiment ratio.

Fig. 11. Tukey’s HSD test results for sentiments among cities. The left presents the result for positive sentiment ratio, and the right presents the result for negative sentiment ratio.
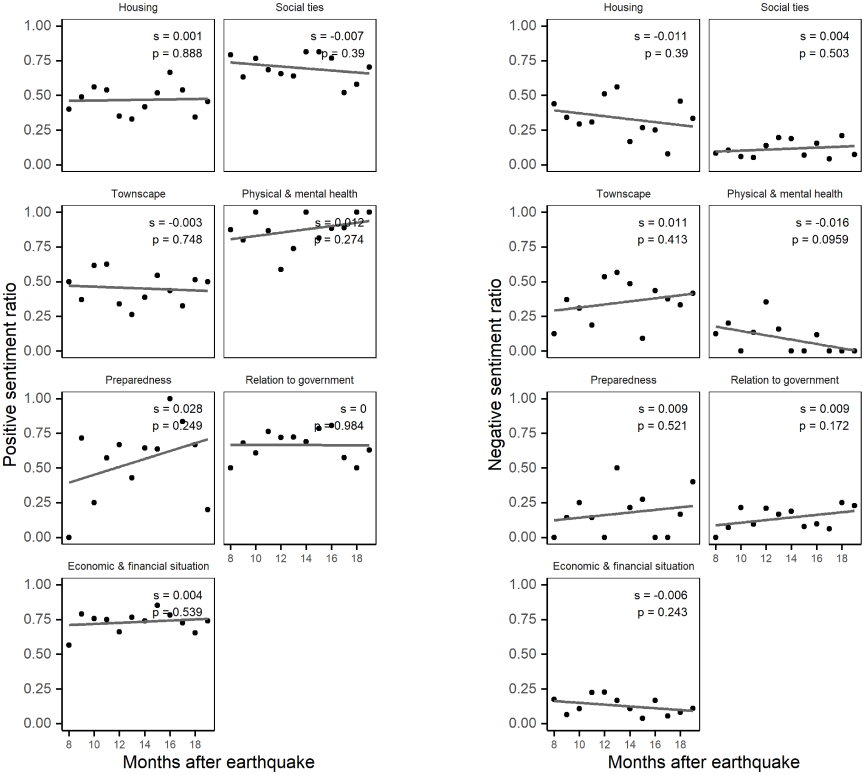
Fig. 12. Changes in sentiments of recovery elements over time.
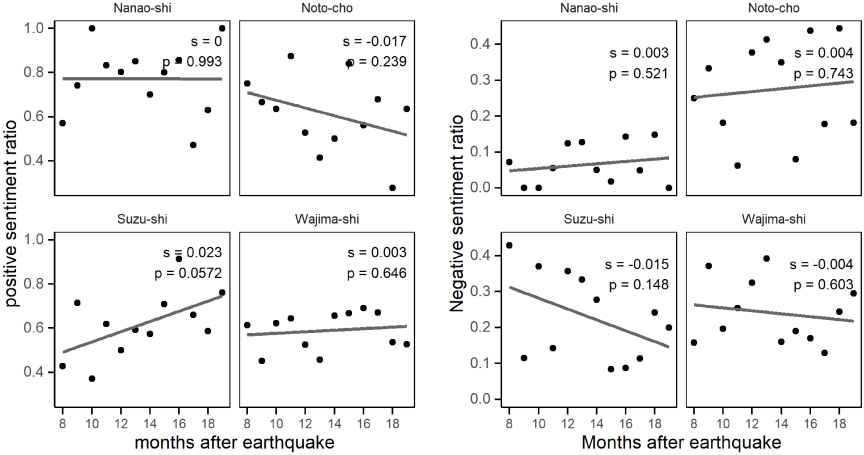
Fig. 13. Changes in sentiments of cities over time.
Figure 13 presents the results of the OLS analysis of positive and negative sentiment in the four cities. No statistically significant trends are observed for any city in either sentiment category. However, Suzu-shi and Wajima-shi display the same pattern, with increasing positive sentiment and decreasing negative sentiment. This similarity between Suzu-shi and Wajima-shi may be linked to their experiences of significant damage during the earthquake, which could have resulted in comparable recovery processes and shifts in sentiment.
4. Discussion
This section analyzes the errors associated with the GPT-based method, potential explanations for significant volume trends, and limitations in the interpretation of the results.
4.1. Errors for GPT-Based Methods
Some typical errors of the GPT-based method in the NLP tasks were identified, as presented in Appendix C. Although the GPT-based method can assist with classification, these findings emphasize its limitations in classifying recovery-related texts.
The first type of error stems from the limited inference ability of the GPT-4o model. In Case No.1, human annotators can recognize that the content is related to recovery from the Noto Peninsula earthquake, although the word “Noto” is not explicitly mentioned. In contrast, GPT-4o fails to make this implicit connection. Case No.4 presents another example of this limitation. Based on contextual information, it can be inferred that infrastructure damage caused by the earthquake negatively impacted farming activities and the local economy. However, GPT-4o does not capture the recovery-related aspect of the economic and financial situation in this case.
The second type of error may arise from excessive reliance on keywords, which can result in misunderstanding the meaning of a paragraph. For instance, GPT-4o categorizes Case No.2 as a recovery-related paragraph, which may be due to the mention of the Noto Peninsula earthquake. However, this paragraph does not discuss recovery efforts in Noto.
The third type of error involves misunderstanding the category definitions. Case No.3 serves as a representative example. GPT-4o identifies elements related to physical and mental health based on information about casualties. However, in this study, physical health refers to the extent of injury suffered by individuals. Therefore, the casualties should not be classified in this category.
The fourth type of error is specific to sentiment analysis and involves the model’s inability to assess mixed sentiments accurately. For example, in Case No.5, some paragraphs express both positive and negative sentiments. When human annotators evaluate these paragraphs, they usually select the dominant or stronger sentiment. In contrast, GPT-4o often classifies mixed-sentiment cases as neutral, resulting in incorrect sentiment labeling.
4.2. Discussion of Significant Volume Trends
In Fig. 9, the four cases exhibit significant trends. The following discussion provides exploratory interpretations of these trends in relation to relevant events, suggests potential explanations, and develops hypotheses for further research.
-
Increase in coverage of economic and financial situation of Wajima-shi: In August and September 2024, the news highlighted the recovery of the morning market and local tourism, while from October to November, local products and Wajima-nuri were brought across Japan, causing more exposure. From December 2024 to March 2025, charity events related to Wajima-shi received media attention, which may have contributed to its increased focus. From April 2025, the coverage of the Wajima-nuri globe at the World Expo and the reopening of tourist sites and shopping streets coincided with increased attention on Wajima-shi’s economic recovery.
-
Decrease in coverage of housing for Suzu-shi: In August and September 2024, attention was paid to destroyed housing. From October, discussions shifted to temporary housing, including planning and move-in status. After April 2025, housing-related content primarily focused on politicians’ inspections of temporary housing. This shift in coverage is consistent with a decline in the level of attention paid to this element, which may reflect the perceived stabilization of housing conditions.
-
Increase in coverage in relation to government for Suzu-shi: From September to December 2024, politicians visited Suzu-shi and support events and tours were held. From February to March 2025, support and rescue efforts were focused on isolated areas and areas that were destroyed in Suzu-shi. Since April, the government’s support for various aspects has been reported. In this case, these events coincided with a slight increase in the volume of coverage.
-
Increase in coverage in relation to the government for Nanao-shi: From August 2024 to January 2025, the relation to the government element in Nanao-shi primarily focused on primary support for temporary houses and the Wakura hot spring area. Since February 2025, celebrities have visited Nanao-shi to discuss planned travel tours, which have drawn increased media attention. In May, when Princess Aiko visited Nanao-shi, official support for the Wakura area was widely discussed. This event aligns with a significant increase in the volume of coverage.
4.3. Limitations of Coverage for Recovery Elements
The Seven Critical Elements of Life Recovery were proposed based on individual-level experiences. However, the data analyzed in this study come from news media reports, which primarily reflect objective, public, and general information, rather than personal experiences. This focus may have resulted in only certain aspects of life recovery being effectively extracted from news reports. For example, elements such as economic and financial situation and relation to government are discussed much more frequently than elements that are more private, such as physical and mental health, and social ties. Consequently, the absence of some elements in the analysis should be interpreted as limited observability rather than lower significance.
5. Conclusion
This study developed a process for extracting structured disaster-recovery data from news sources, capturing sentiments related to recovery efforts, and linking them to locations. By using keyword-based and GPT-based methods, the approach allows researchers to identify relevant paragraphs, recognize recovery elements, extract location information, and classify sentiment. The processed dataset provides detailed information on how different recovery elements are discussed over time and across affected locations, highlighting the patterns of news media attention and sentiment responses.
The findings reveal that certain recovery elements, such as the economic and financial situation, housing, and relation to government, receive greater news media coverage. For sentiment analysis, a more negative attitude toward housing and townscape elements and a less negative attitude toward Nanao-shi are indicated. No significant trends in volume or sentiment changes are observed in most cases, indicating that they remain generally stable or demonstrate no significant linear trend.
Overall, this study demonstrates the feasibility of using NLP methods on news data to gain insight into news media perceptions and assess news coverage of disaster recovery. These findings highlight the importance of integrating thematic, temporal, and spatial variations into news-based disaster recovery analyses. Notably, however, the proposed approach is limited to identifying patterns in news media coverage and does not assess actual recovery outcomes.
Appendix A. Full Text of Prompts for GPT-Based Method
A.1. Prompt for Related Paragraph Detection
The prompt is provided below. Lines 6–9 present one example provided to GPT-4o. In practice, the training dataset is used as input for few-shot training.
-
文章段落を読んで、能登半島地震と災害復興の関係があるかどうか分析してください。 Please read the paragraph and analyze whether it is related to the Noto Peninsula earthquake and disaster recovery.
-
あるは1、ないは 0。 Mark related as 1, and non-related as 0.
-
段落のIDと内容を入力して、IDと結果だけ教えてください。 The input would be the paragraph’s ID and content. Please only return the ID and result of the related paragraph detection.
-
“ID, 結果(1 or 0)” というフォーマット Thus, as format “IDs, result (1 or 0).”
-
例: Example:
-
XXXXXX-XX (ID)
-
能登半島地震で被災した輪島塗の工房を支援しようと東日本大震災の被災地で仮設商店として使われていたトレーラーハウス2台が、9日、輪島市の団体「輪島塗若手ネットワーク」に寄贈されました。(内容) To support Wajima-nuri workshops that were affected by the Noto Peninsula earthquake, two trailer houses that had been used as temporary shops in the Great East Japan Earthquake-affected areas were donated to the Wajima-nuri Young Network, an organization in Wajima-shi, on the 9th. (content)
-
能登半島地震と災害復興との関係があります。 In this content, it only presents the postponement time of the event. No emotion was mentioned.
-
“XXXXXX-XX, 1” 返事してください。 Please return “XXXXXX-XX, 1”.
-
[The input data for detection (ids and paragraphs) is provided here.]
A.2. Prompt for Recovery Elements Identification
The prompt is provided below. Lines 6 to 9 present one example provided to GPT-4o. In practice, the training dataset is used as input for few-shot training.
-
災害復興に関する文章段落を読んで、復興生活再建7要素のカテゴリを付けてください。複数のカテゴリを付けても構いません。 Please read the disaster-recovery-related paragraphs and perform the recovery elements identification. It is possible to label multiple categories.
-
復興生活再建7要素は 1. すまい:災害後の住宅事情、避難所、公営住宅に関すること 2. つながり:災害後の人と人とのつながり(の変化)3. まち:災害後のインフラ、都市のコモンズ、景観の変化 4. こころとからだ:災害に関する精神的ストレス、うつ病、身体的損傷 5. そなえ:個人的および社会的な備え、備え情報の共有、災害経験に基づく備え 6. 行政とのかかわり: 政府からのサービスと支援、政府の取り組みに対する満足/不満/コメント 7. くらしむき:災害後の個人の経済状況、収入、全体的な経済状況。 The seven elements of recovery include: 1. Housing: housing conditions, shelters, and public housing after the disaster; 2. Social ties: (changes in) human connections after the disaster; 3. Townscape: infrastructure, urban commons, and changes in landscape after the disaster; 4. Physical and mental health: disaster-related mental stress, depression, and physical injuries; 5. Preparedness: individual and societal preparation, sharing of preparedness information, and preparation based on disaster experiences; 6. Relation to government: services and support from the government, and satisfaction/dissatisfaction/comments about government efforts; 7. Economic and financial situation: personal economic situation, income, and overall economic situation after the disaster.
-
段落のIDと内容を入力して、IDとカテゴリの結果だけ教えてください。 The input would be the paragraphs’ ID and content. Please only return the ID and the result of the recovery elements identification.
-
“ID, 7要素のカテゴリ” というフォーマット Thus, as format “ID, types of recovery elements.”
-
例: Example:
-
XXXXXX-XX (ID)
-
12月16日、災害ボランティア十数人が同市上戸町の永禅寺周辺に向かった。崩土と浸水で堆積した土砂が、3カ月たってやっと取り除かれた。(内容) On December 16, some volunteers went to the area around Eizenji Temple in Kamito-machi. The debris that had accumulated owing to landslides and flooding had finally been removed after three months. (content)
-
2. つながり、3. まちがあります。 It includes element 2. social ties and 3. townscape.
-
“XXXXXX-XX, [0,1,1,0,0,0,0]” 返事してください。 Please return “XXXXXX-XX, [0,1,1,0,0,0,0].”
-
[The input data for identification (ids and paragraphs) is provided here.]
A.3. Prompt for Sentiment Analysis
The prompt is provided below. Lines 6 to 9 present one example provided to GPT-4o. In practice, the training dataset is used as input for few-shot training.
-
災害復興に関する文章段落を読んで、感情分析してください。 Please read the disaster-recovery-related paragraphs, then perform the sentiment analysis.
-
ポジは1、なしは0、ネガは\(-1\) Mark positive sentiment as 1, neutral as 0, and negative as \(-1\).
-
段落のIDと内容を入力して、IDと感情分析の結果だけ教えてください。 The input would be the paragraphs’ ID and content. Please only return the ID and the result of the sentiment analysis.
-
“ID, 感情分析の結果(1 or \(-1\) or 0)” というフォーマット Thus, as format “ID, result (1 or \(-1\) or 0).”
-
例: Example:
-
XXXXXX-XX (ID)
-
イベントは令和6年能登半島地震の影響により開催を延期し、10月5日の5日間で開催される。(内容) The event was postponed owing to the Noto Peninsula earthquake in 2024 and will be held for five days from October 5th. (content)
-
感情分析の結果はなし。 The result of the sentiment analysis is neutral.
-
“XXXXXX-XX, 0” 返事してください。 Please return “XXXXXX-XX, 0.”
-
[The input data for analysis (ids and paragraphs) is provided here.]
Appendix B. Keywords for Recovery Element Identification
-
すまい (Housing): 仮設住宅 (temporary housing), 半壊 (partially destroyed), 全壊 (completely destroyed), 住宅被害 (housing damage), 家屋 (house), 住まい (housing), 再建 (reconstruction), 住宅 (housing), 住民 (residents), 建物 (building), 家は (house is), 家で (at home)
-
つながり (Social ties): 祭り (festival), まつり (festival), 協力 (cooperation), ボランティア (volunteer), 絆 (bond), 祈願 (pray), 祈り (pray)
-
まち (Townscape): 土砂崩落 (landslide), 人口 (population), 開通 (opening), 解体 (demolition), 朝市 (morning market), 交通 (traffic), インフラ (infrastructure), 鉄道 (railway), 通行 (passage)
-
こころとからだ (Physical and mental health): 不安 (anxiety), 沈む (feel down), 絶望 (despair), 痛む (hurt), 希望 (hope), 元気 (energetic), 寂しい (lonely), 悲しい (sad), うれしい (happy)
-
そなえ (Preparedness):防災 (disaster prevention), 整備 (preparation), 備え (preparation)
-
行政とのかかわり (Relation to government): アンケート (questionnaire survey), 公的支援 (government support), 政府 (government), 公費 (government funds), 支援 (support), 取り組み (effort), 行政 (administration), 予算 (budget)
-
くらしむき (Economic and financial situation): 仮設商店 (temporary shop), 寄付 (donation), 義援金 (relief donation), 奨学金 (scholarship), 輪島塗 (Wajima-nuri), ツアー (tour), 輪島朝市 (Wajima morning market), 住宅ローン (housing loan), 再開 (reopening), 支援 (support)
Appendix C. Example Paragraphs for GPT-Based Method Error Analysis
Table 4 presents example paragraphs for GPT-based method error analysis.
Table 4. Example paragraphs for GPT-based method error analysis.

Acknowledgments
This study was conducted under the Cooperative Laboratory Study Program (COLABS) at Tohoku University. This study was also supported by JSPS KAKENHI Grant Number 25H00782.
- [1] D. E. Alexander, “Principles of emergency planning and management,” Oxford University Press, 2002.
- [2] United Nations Office for Disaster Risk Reduction (UNDRR), “The Sendai Framework Terminology on Disaster Risk Reduction, Recovery.” https://www.undrr.org/terminology/recovery [Accessed July 31, 2025]
- [3] B. Miles and S. Morse, “The role of news media in natural disaster risk and recovery,” Ecological Economics, Vol.63, Nos.2-3, pp. 365-373, 2007. https://doi.org/10.1016/j.ecolecon.2006.08.007
- [4] S. Sato, H. Hayashi, K. Inoue, and T. Nishino, “Visualizing chronological behavior of disaster social aspect based on web news articles on disasters and crises,” Trans. of the Visualization Society of Japan, Vol.29, No.7, pp. 17-26, 2009 (in Japanese). https://doi.org/10.3154/tvsj.29.17
- [5] J. R. Ragini, P. R. Anand, and V. Bhaskar, “Big data analytics for disaster response and recovery through sentiment analysis,” Int. J. of Information Management, Vol.42, pp. 13-24, 2018. https://doi.org/10.1016/j.ijinfomgt.2018.05.004
- [6] K. C. Roy, S. Hasan, and P. Mozumder, “A multilabel classification approach to identify hurricane-induced infrastructure disruptions using social media data,” Computer-Aided Civil and Infrastructure Engineering, Vol.35, No.12, pp. 1387-1402, 2020. https://doi.org/10.1111/mice.12573
- [7] A. D. Malawani, A. Nurmandi, E. P. Purnomo, and T. Rahman, “Social media in aid of post disaster management,” Transforming Government: People, Process and Policy, Vol.14, No.2, pp. 237-260, 2020. https://doi.org/10.1108/TG-09-2019-0088
- [8] Y. Yan, J. Chen, and Z. Wang, “Mining public sentiments and perspectives from geotagged social media data for appraising the post-earthquake recovery of tourism destinations,” Applied Geography, Vol.123, Article No.102306, 2020. https://doi.org/10.1016/j.apgeog.2020.102306
- [9] D. Contreras, S. Wilkinson, N. Balan, and P. James, “Assessing post-disaster recovery using sentiment analysis: The case of L’Aquila, Italy,” Earthquake Spectra, Vol.38, No.1, pp. 81-108, 2022. https://doi.org/10.1177/87552930211036486
- [10] D. Contreras, S. Wilkinson, E. Alterman, and J. Hervás, “Accuracy of a pre-trained sentiment analysis (SA) classification model on tweets related to emergency response and early recovery assessment: the case of 2019 Albanian earthquake,” Natural Hazards, Vol.113, No.1, pp. 403-421, 2022. https://doi.org/10.1007/s11069-022-05307-w
- [11] B. Rouhanizadeh, S. Kermanshachi, and T. J. Nipa, “Exploratory analysis of barriers to effective post-disaster recovery,” Int. J. of Disaster Risk Reduction, Vol.50, Article No.101735, 2020. https://doi.org/10.1016/j.ijdrr.2020.101735
- [12] S. Tatsuki and H. Hayashi, “Seven critical element model of life recovery: General linear model analyses of the 2001 Kobe panel survey data,” Proc. 2nd Workshop for Comparative Study Urban Earthquake Disaster Management, pp. 23-28, 2002.
- [13] S. Tatsuki and F. Kawami, “Longitudinal impacts of pre-existing inequalities and social environmental changes on life recovery: Results of the 1995 Kobe Earthquake and the 2011 Great East Japan Earthquake recovery studies,” Int. J. Mass Emergencies & Disasters, Vol.41, No.1, pp. 94-120, 2023. https://doi.org/10.1177/02807270231171504
- [14] S. Tatsuki, “Long-term life recovery processes among survivors of the 1995 Kobe earthquake: 1999, 2001, 2003, and 2005 life recovery social survey results,” J. Disaster Res., Vol.2, No.6, pp. 484-501, 2007. https://doi.org/10.20965/jdr.2007.p0484
- [15] S. Sato, F. Imamura, and H. Hayashi, “Basic analysis of the web news corpus broadcasted the 2011 Great East Japan earthquake disaster,” J. of Social Safety Science, Vol.303, No.15, p. 311, 2011.
- [16] S. Sato, “Analysis of tweets hashtagged ‘# rescue’ in the 2017 north Kyushu heavy rain disaster in Japan,” Proc. 2018 5th Int. Conf. on Information and Communication Technologies for Disaster Management (ICT-DM), pp. 1-7, 2018.
- [17] Disaster Management in Japan, Cabinet Office Japan, “Reiwa 6-nen Noto Hantō Jishin ni yoru higai jōkyō-tō ni tsuite” 2025 (in Japanese). https://www.bousai.go.jp/updates/r60101notojishin/r60101notojishin/pdf/r60101notojishin_59.pdf [Accessed October 20, 2025]
- [18] Yahoo! JAPAN News (in Japanese). https://news.yahoo.co.jp/ [Accessed July 31, 2025]
- [19] B. Liu, “Sentiment analysis and opinion mining,” Morgan & Claypool Publishers, 2012.
- [20] OpenAI Platform. https://platform.openai.com/docs/overview [Accessed July 31, 2025]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.