Research Paper:
Design of Hotspot Mining System for Social Media Network News and Public Opinion Based on Fuzzy Clustering Analysis
Shuai Wang†, Xiaomeng Mu, and Xiaolan Sun
Weifang Engineering Vocational College
No.8979 South Yunmen Mountain Road, Qingzhou, Weifang, Shandong 262500, China
†Corresponding author

Due to the limitations of conventional data processing methods, traditional information analysis techniques often struggle to handle massive and rapidly disseminated information accurately and efficiently. This leads to low efficiency and poor accuracy in mining hot topics from social media news and public opinion. To address this, a system for mining hot topics in social media news and public opinion based on fuzzy clustering analysis is proposed. Following a hierarchical design logic, the overall architecture of the social media network news and public opinion hot spot mining system is constructed. A hardware architecture for embedded systems is designed to support multi-source data capture and resource loading, enhancing system performance. A semantic concept tree, built using a generalized mapping method, is employed to define hot news and public opinion information on social media networks. Utilizing a text tag structure as the core framework for the news and public opinion topic tag model facilitates the targeted collection of hot topic information. Innovatively, the fuzzy clustering analysis method is applied to cluster public opinion hot topics, determine the optimal clustering centers for these topics, and thereby achieve effective mining of news and public opinion hot topics. Experimental results demonstrate that the proposed system completes the hot topic mining process in 18.47 seconds. Furthermore, it achieves precision and recall rates above 95% across multiple categories of public opinion texts. This indicates that the designed system operates with high overall application efficiency and short processing times. It can comprehensively and accurately mine news and public opinion hot topics, effectively avoiding the misclassification of non-hot topics as hot topics, and exhibits strong practical application performance.
1. Introduction
In a social media network environment, online news spreads at an exponential rate, forming a highly complex communication network. This complexity, arising from diverse sources and dissemination paths, introduces significant uncertainty into information propagation 1,2. From a user perspective, during major public opinion events, the information circulating on social media often contains substantial redundancy—including unverified reports, personal viewpoints, and emotional comments. Such redundancy impedes users’ ability to filter meaningful news and can lead to a prolonged escalation of public sentiment, potentially affecting social stability in the digital space 3. Consequently, the effective detection and mining of news and public opinion hotspots is critically important.
In 4, a novel sub-event mining detection method based on a biclustering approach is proposed. First, the data matrix is clustered using spectral co-clustering. Subsequently, an ordering framework among sub-events (words) is established to identify the top-ranked sub-events within the clusters for detection. However, this method necessitates simultaneous clustering of rows (samples) and columns (features), which significantly increases computational complexity and can adversely affect mining efficiency. In 5, an unsupervised learning-based method is proposed for evaluating the evolutionary trend of social media public opinion. Initially, an evaluation index system for the evolution trend is established. Then, these indices are combined with neighborhood features via a graph convolutional neural network to extract hybrid features of the evolution trend; the relevance of these hybrid features is computed using a correlation ranking method. Finally, an unsupervised learning-based evaluation model for opinion evolution trends is constructed based on the correlation degree of the mining results, which demonstrates improved effectiveness in mining and evaluating the trend. However, this method lacks clear label information during the feature mining stage for public opinion evolution, making it difficult to accurately capture its hotspots and evolutionary trends. Reference 6 proposes a sentiment text analysis and mining method for national police data based on the CRISP-DM framework. It adopts this cross-industry standard process, advances five data-mining activities, and employs topic modeling to develop police-related topics for sentiment analysis. However, the method utilizes traditional machine learning techniques during modeling, which exhibit insufficient adaptability to complex text data, thereby affecting the mining accuracy of sentiment text. In 7, a deep learning method for traffic accident recognition and information mining from online Chinese news is proposed, consisting of three modules: automatic news gathering, news classification, and traffic accident information mining. The automatic news gathering module collects news from online resources, cleanses and organizes them into a general news database containing different categories. The news classification module robustly identifies traffic accident news from various types by fusing semantic information from sentences and contexts. The accident information mining module extracts key attributes (e.g., cause, time, location) from news texts using a soft lexicon-based bidirectional long short-term memory network-conditional random field approach. However, this method employs deep learning models that typically require transforming text into high-dimensional vectors, which is computationally intensive during data transformation and struggles to adapt to the dynamic nature of news data features. Reference 8 proposes a semantic driven topic modeling technique using transformer based embedding and clustering algorithms. Topic modeling is a powerful technique that can discover hidden topics and patterns in document collections without prior knowledge. This study introduces an innovative end-to-end semantic-driven topic modeling technique for topic extraction, utilizing advanced word and document embeddings as well as clustering algorithms. This approach represents a significant advancement, leveraging contextual semantic information to extract coherent and meaningful themes. Specifically, the model employs a pre-trained transformer-based language model to generate document embeddings, reduces the embedding dimensionality, clusters embeddings based on semantic similarity, and generates coherent themes for each cluster. Compared to traditional topic modeling algorithms, the proposed model yields more coherent and meaningful topics. However, this method faces challenges in capturing contextual semantic information based solely on topic modeling and clustering techniques. Reference 9 proposes using the BERT model to enhance sentiment analysis in multi contextual social media content. This study investigates the application of the BERT model in sentiment analysis of multi-context social media content, aiming to improve sentiment classification accuracy by utilizing contextual embeddings. The research objectives include examining BERT’s effectiveness in capturing sentiments across different social media posts and evaluating its performance against traditional methods. The method involves annotating text content, using BERT to transform annotations into contextual embeddings, and integrating multimedia features to form a comprehensive sentiment analysis framework. Experimental results indicate that the BERT model achieves high accuracy in sentiment classification, with significant improvement in performance and low cross-entropy loss. These findings underscore the model’s capability to understand nuanced contextual differences and its potential for optimizing social media monitoring and analysis processes. However, this method requires larger and more diverse datasets, as well as the incorporation of multimedia content to improve generalizability.
Compared with the above methods, the system proposed in this paper exhibits the following characteristics:
-
(1)
To address the dynamic and fuzzy nature of public opinion boundaries, fuzzy clustering and particle swarm optimization (PSO) are introduced during the clustering stage. This approach better handles the fuzziness and real-time evolution characteristics of public opinion boundaries.
-
(2)
Semantic-enhanced representation: Through a semantic concept tree and tagging models, the semantic discriminative capability of topics is improved, compensating for the insufficient semantic understanding inherent in unsupervised methods.
-
(3)
Computational efficiency optimization: By employing density clustering for initialization and PSO for acceleration, the computational complexity is significantly reduced while maintaining clustering accuracy, thereby meeting the requirements for real-time mining of large-scale public opinion data.
-
(4)
System integrity: A complete system encompassing collection, representation, clustering, and visualization is constructed, addressing the limitation of existing methods that often focus on a single component and lack overall coordination.
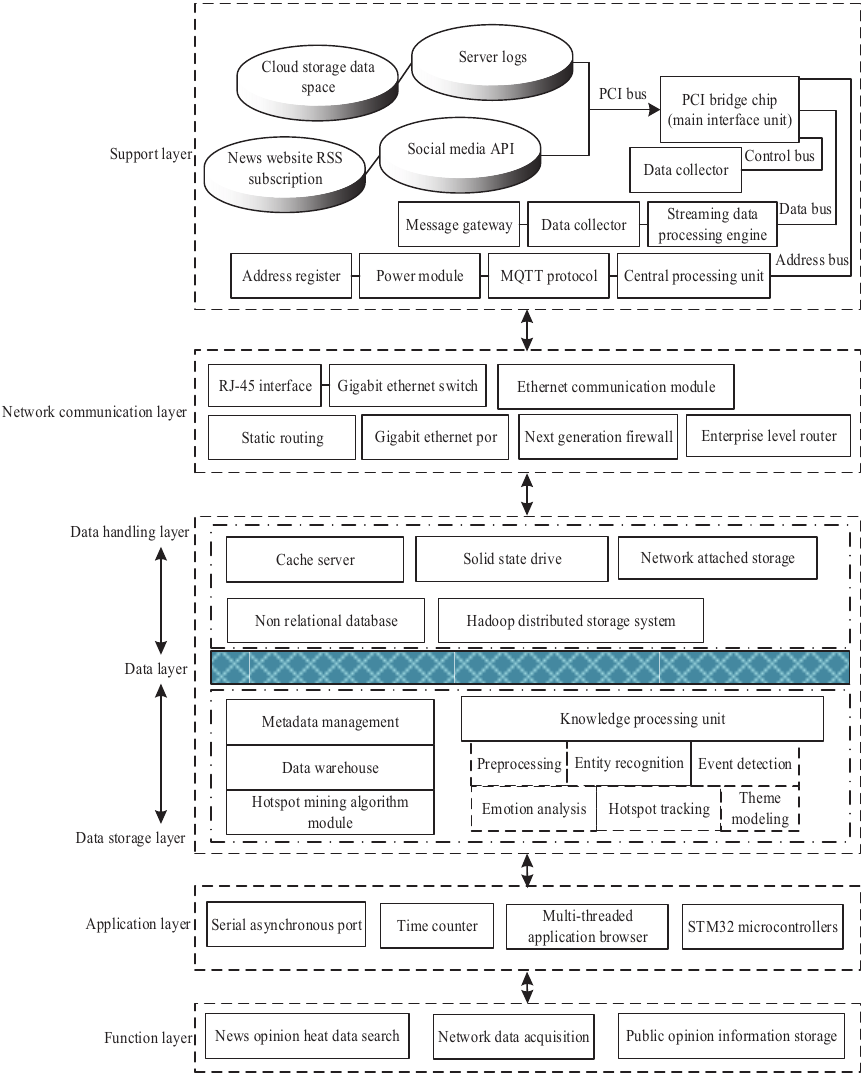
Fig. 1. Architecture of a social media news and public opinion hotspot mining system.
Based on this, to mitigate information overload caused by news and public opinion hotspot mining—which can interfere with user decision-making and the subsequent evolution of high-discussion public opinion—this paper proposes a fuzzy clustering analysis framework integrating semantic concept tree modeling and PSO for mining hotspots in social media news and public opinion. The main innovations of this study are as follows:
-
(1)
By constructing a semantic concept tree using generalized mapping, public opinion information is represented as multi-level semantic units, thereby enhancing the semantic discriminative capability of hotspot information.
-
(2)
A text tag structure is designed as a topic tag model, enabling the dynamic identification and aggregation of primary tags (core topics) and secondary tags (sub-topics).
-
(3)
The PSO algorithm is introduced to accelerate and optimize the fuzzy clustering process, ensuring clustering accuracy while significantly improving mining efficiency.
-
(4)
A complete system architecture is proposed, covering multi-source data collection, real-time processing, and visual interaction, to support efficient mining of large-scale public opinion data.
The proposed system not only retains the advantages of fuzzy clustering in handling uncertain data but also achieves a synergistic improvement in the accuracy, efficiency, and interpretability of public opinion hotspot mining through the aforementioned innovations, thereby demonstrating strong practical application value.
2. Design of a Social Media News and Public Opinion Hotspot Mining System
2.1. System Architecture for Social Media News and Public Opinion Hotspot Mining
A social media network news and public opinion hotspot mining system is an analytical tool that integrates machine learning, network communication, and data processing technologies, suitable for processing massive unstructured public opinion data. The system employs a hierarchical architecture design, characterized by high cohesion, low coupling, a clear structure, and ease of expansion, as illustrated in Fig. 1.
As shown in Fig. 1, the social media network news and public opinion hotspot mining system employs a layered architecture, comprising structural layers such as the support layer, the network communication layer, the data layer (including data storage and data processing), the application layer, and the functional layer. Each layer possesses clearly defined system functions and interacts through standardized interfaces, demonstrating considerable scalability. Within this system, the fuzzy clustering analysis algorithm model in the data processing layer operates as an independent module. It supports system functionality by serving as a component of the support layer to collect social media network news and opinion data for fuzzy clustering analysis, and subsequently enables the acquisition of personalized opinion hotspot data within the functional layer. The system-level functions are described as follows:
-
(1)
Support layer: This layer encompasses the system’s associated data sources, data collectors, PCI bridge chips (serving as general interface units), central processing units, and fundamental network resources. The support layer connects to the data layer via the network communication layer, transmitting crawled network news and public opinion data to the data layer. Concurrently, hardware devices within the support layer exchange data and signals through connections established by the control bus, data bus, and address bus.
-
(2)
Network communication layer: This layer is based on the system’s network conditions and includes elements such as network coverage range, gateway rules, information access interfaces, and network communication hardware (including communication modules). One end of the network communication layer connects to the support layer to receive network public opinion data output from it, while the other end connects to the data layer to transfer data to its database 10. Simultaneously, network devices within this layer forward and exchange data via the RJ-45 interface and static routing network protocol.
-
(3)
Data layer: This layer can be subdivided into a data storage layer and a data processing layer. The data storage layer primarily consists of elements such as a Hadoop distributed storage system, cache servers, and non-relational databases. It is used to temporarily store collected unstructured data from social media and network news, providing a foundation for subsequent data retrieval by the data processing layer. The data processing layer mainly includes a metadata management system, a knowledge processing unit, and an algorithm module dedicated to mining network public opinion information hotspots. This layer is responsible for preprocessing social network news and public opinion data, performing fuzzy clustering analysis, and aggregating public opinion hotspots within the system. The application layer accesses the aggregated data through an information access interface.
-
(4)
Application layer: This layer is the primary level for system operation, mainly comprising a serial asynchronous port, a time counter, a multi-threaded application browser, and an STM32 microcontroller. The serial asynchronous port and time counter facilitate serial communication with external terminal devices within the system, sending and receiving public opinion data asynchronously to achieve data-level communication between systems. The STM32 microcontroller, acting as the peripheral controller for the multi-threaded application browser motherboard, coordinates the operational sequence of components in the functional layer to ensure the system executes data processing and analysis tasks according to the predetermined logical flow 11.
-
(5)
Functional layer: This layer is primarily user-oriented, leveraging the system’s main software applications and data information to provide users with diversified services. These include massive social network news and public opinion hot topic data search, news resource acquisition, information storage, permission maintenance, and the recommendation of personalized application service content based on user search preferences.
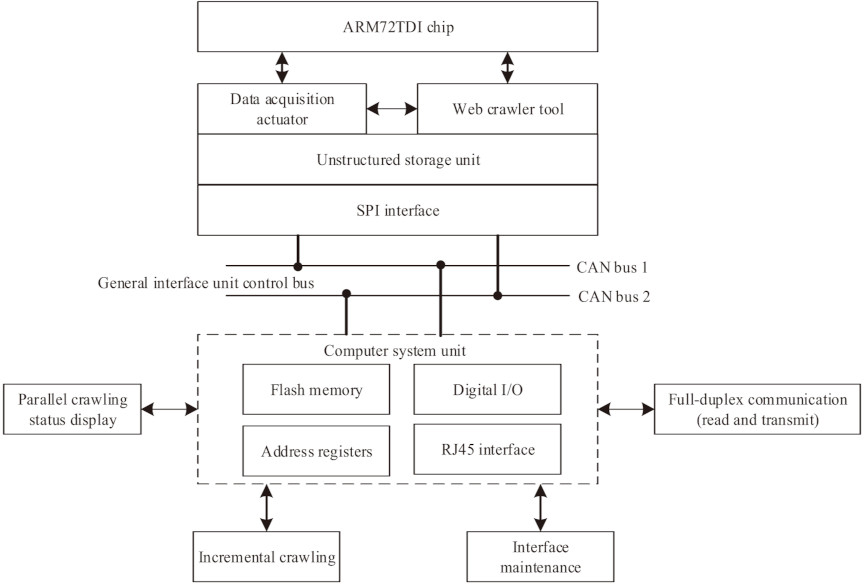
Fig. 2. Architecture of the public opinion data collector.
2.2. Hardware Architecture of a News and Public Opinion Hotspot Mining System
To meet the requirements of high concurrency and low latency in collecting and processing social media public opinion data, the hardware architecture of this system is designed following the principles of low power consumption, high parallelism, and strong real-time performance, selecting an embedded ARM processor and an STM32 microcontroller as the core hardware platform. The specific rationale is as follows:
-
(1)
The ARM architecture features low power consumption and high performance, making it suitable for long-running tasks such as web crawling and data preprocessing.
-
(2)
The STM32 microcontroller supports multiple peripheral interfaces and real-time operating systems, making it suitable for coordinating the collaboration between multi-threaded browsers and communication modules.
-
(3)
The multi-threaded browser design can simulate real user behavior and capture multi-source web pages, thereby improving the coverage efficiency and real-time performance of public opinion data collection.
-
(4)
The hardware communication module ensures stable data transmission among system components and avoids acquisition delays caused by software protocol overhead.
2.2.1. Public Opinion Data Collector
In the system architecture shown in Fig. 1, the support layer presents the main hardware elements and computational resources for system construction. To achieve effective capture of social media network news and public opinion data, a 16/32-bit ARM72TDI chip is adopted as the core processor of the data collection module, which hosts a web crawler tool for multi-source data capture. The specific structure is illustrated in Fig. 2.
As shown in Fig. 2, the basic structure of the news and public opinion data collector can be regarded as consisting of a data collection execution unit for acquiring and initially storing public opinion data, and a computer system unit for reading and accessing computational data. The collector employs the ARM72TDI chip as its built-in processing unit, utilizes a web crawler tool to crawl unstructured news and public opinion data from target source websites, and interacts with a general interface unit via the CAN control bus to transmit the collected data to the computer system 12,13. During data crawling and transmission, control signals are sent to the actuator from an external device through a digital I/O interface to enable a parallel crawling status display.
The public opinion data collector is designed based on the ARM72TDI chip, which features a 16/32-bit mixed instruction set and a hardware network protocol stack, supporting high-concurrency network connections and real-time packet analysis. Combined with customized crawler tools, it can crawl and duplicate multi-source social media data in parallel. The hardware design communicates with the host computer through a CAN bus, ensuring reliable and real-time data transmission and meeting the requirements for high-frequency data acquisition during public opinion outbreaks.
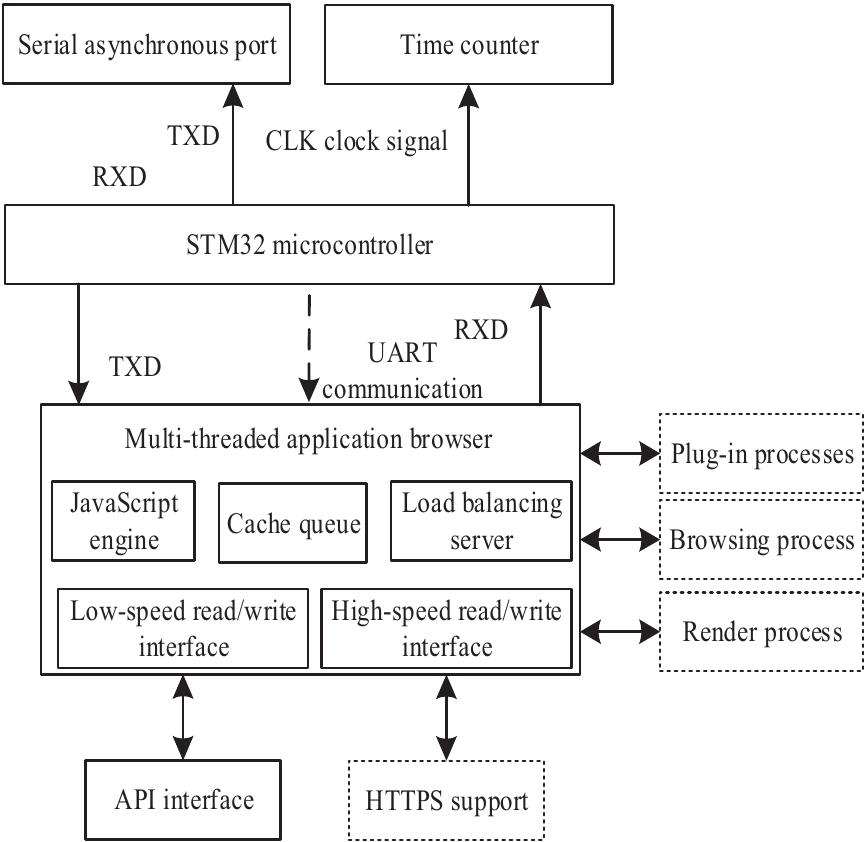
Fig. 3. Architecture of the multi-threaded application browser.
2.2.2. Multi-Threaded Application Browser
The multi-threaded application browser is responsible for handling user requests, enabling concurrent rendering and resource loading of public opinion web pages, and supporting high-concurrency data acquisition and real-time public opinion capture. It employs an embedded microcontroller architecture and facilitates efficient data transmission between systems through an asynchronous communication mechanism. The specific structure is illustrated in Fig. 3.
As shown in Fig. 3, the multi-threaded application browser employs a low-power embedded STM32 microcontroller as its core control unit, which acts as the peripheral controller of the browser’s motherboard. The controller primarily utilizes two peripheral modules—a serial asynchronous port (UART) and a time counter—to perform serial communication of network public opinion data and control instructions among system devices 14. In the former application, transmit data (TXD) is used as the transmission data pin and receive data (RXD) as the reception data pin to achieve serial asynchronous communication. When the JavaScript engine generates a demand to send public opinion data externally, the data are encoded, transmitted via the TXD line, and added to a cache queue. The API interface then retrieves the data sent by the transmitter through the RXD line, decodes it, and restores it to the original data 15. The latter mainly participates in communication time management and, during public opinion analysis, records timestamps such as the time of data collection, the time of event occurrence, and other temporal markers related to public opinion heat information.
During outbreaks of public opinion hotspots, the browser can simulate user behavior, support multi-process concurrent processing, and effectively enhance the real-time performance and system throughput of public opinion data collection.
The multi-threaded application browser employs an STM32 microcontroller as its core scheduling unit and achieves high-precision synchronous communication between systems through hardware UART and timer modules. The browser supports multi-process rendering and resource loading, enabling it to simulate real users simultaneously accessing public opinion web pages and effectively handle peak traffic during hotspot events. This design not only ensures collection efficiency but also reduces access pressure on target servers, thereby meeting the ethical requirements for compliant data collection.
2.3. Software Design for a News and Public Opinion Hotspot Mining System
2.3.1. Definition of Hotspot Information in Social Media News and Public Opinion
Social media news is primarily presented in webpage format, where the linkage between pages constitutes the information dissemination path. Pages with a higher number of inbound links are generally more significant and more likely to contain public opinion hotspots. Therefore, this paper focuses on analyzing high-frequency information across multi-source webpages to identify public opinion hotspots. Instead of examining the information silo of a single webpage, the study investigates the interrelationships among webpages within a multi-source data platform. Intuitively, it can be inferred that the more frequently a webpage is linked and the greater its relative importance, the higher the likelihood that it contains online public opinion hotspots.
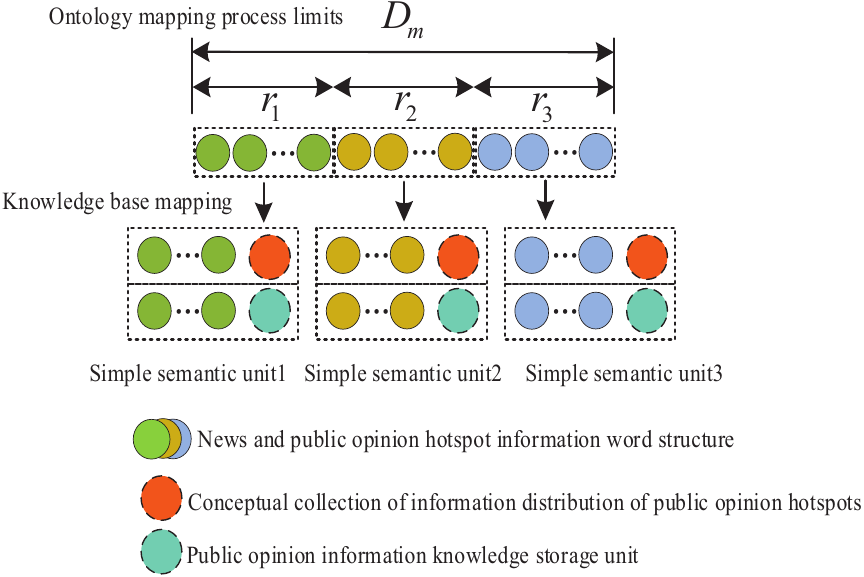
Fig. 4. Semantic concept tree for news and public opinion hotspot mining.
Hotspot information in multi-connected webpages refers to data samples that frequently appear within social media network news and public opinion datasets. For web hosts, mining algorithms developed for this type of data sample can more intuitively reflect the transmission trends of online social media news and public opinion. A higher repetition frequency of hotspot information indicates stronger relevance between the ongoing public opinion discussion and this category of data samples 16,17,18. From the perspective of news dissemination characteristics, hotspot information shares the same transmission level as other public opinion data; however, the former evidently possesses a greater capacity to dominate the direction of public opinion and influence users’ subjective thoughts more strongly 19. Therefore, this study identifies webpages with high connection counts (from diverse sources) and represents hotspot information based on the aforementioned principles.
By taking the maximum value of the network news dissemination characteristic parameter as the initial memory representation of social media network news and public opinion, the definition of hotspot information in social media network news and public opinion is described as follows:
The definition of \(D_m\) must not only correspond to the semantic features of public opinion hotspot information but also reflect its basic semantic components. Accordingly, this study sets \(r_1\), \(r_2\), \(r_3\) in the form of a triple as the semantic division scale and adopts a semantic concept tree model to design the semantic ontology structure and analyze the internal structural features of public opinion hotspot information distribution. The specific concept tree structure is illustrated in Fig. 4.
As shown in Fig. 4, the semantic concept tree for mining news and public opinion hotspot information, constructed via a generalized mapping method, divides the word structures contained in \(D_m\) into semantic features based on the feature relationships of \(r_1,r_2,r_3\), yielding word segmentation results that reflect the semantic features of public opinion hotspot information. Based on this, a concept set for public opinion hotspot information distribution is constructed according to relevant knowledge-base information. The divided semantic feature word structures are then mapped onto the generated concept set. The semantic features within the mapped concept set can be encapsulated into knowledge storage units, each of which serves as a knowledge storage unit for public opinion information. The smallest semantic unit is subsequently extracted from the knowledge storage unit to obtain the most fundamental semantic component, termed a simple semantic unit, within the hotspot information of a single-topic public opinion category. By reading the simple semantic units within the concept set structure, an autocorrelation function is derived for the distributed mining of hotspot information in social media network news and public opinion. This functional relationship reflects the final definition of \(D_m\):
2.3.2. Targeted Hotspot Information Collection
In the social media network news and public opinion hotspot mining system, considering the fragmented and real-time transmission characteristics of social media network news and public opinion information, it is necessary to integrate the stored network news and public opinion information into multiple tag collections while preserving the transmission of hotness for key data samples. These collections are then organized for complete transmission to the host unit, enabling the host device to split them into primary and secondary labels according to topic characteristics. To provide an overview of the semantic features of online news and public opinion 20, this study constructs a text tag structure for representing simple semantic units covering semantic feature information in \(r_1(D_j),r_2(D_j),r_3(D_j)\), which serves as a news and public opinion topic tag model:
To achieve the final definition of \(D_m\) and the construction of \(C_0\), it is necessary to collect hotspot information from target social network news and public opinion data (i.e., primary labels). Here, target information collection is used to extract key news data—which comprehensively covers hotspot information—from information samples of network news and public opinion that contain such hotspot information, thereby meeting the system host’s requirements for data mining and processing. If the topic tagging model \(C_0\) maintains a stable transfer capability for public opinion data, it can be inferred that a larger volume of information to be transferred corresponds to a greater amount of target information requiring processing by the system host. Accordingly, the transmission characteristics of micro-social media network news and public opinion are described as follows:
Based on the transmission characteristics of public opinion information described in Eq. \(\eqref{eq:5}\), the expression for collecting hotspot target information of social media network news and public opinion is derived as:
2.3.3. Mining Hotspots in Social Media News and Public Opinion Using Fuzzy Clustering Analysis
Social media public opinion data often exhibit characteristics such as overlapping topics, semantic redundancy, and fuzzy boundaries, making it difficult for traditional hard clustering methods to effectively handle such uncertainties. Fuzzy clustering allows each data point to belong to multiple clusters with a certain degree of membership, making it more suitable for capturing the real distribution of public opinion topics. Based on the fuzzy \(C\)-means clustering framework, this paper introduces semantic constraints and a dynamic optimization mechanism to improve the accuracy and stability of hotspot recognition. The core idea can be intuitively understood as follows: the text features extracted through the semantic concept tree form a high-dimensional semantic space, where each topic corresponds to a “semantic centroid.” Data points (i.e., public opinion texts) do not strictly belong to a single centroid but are distributed around multiple centroids according to semantic similarity, resulting in a “soft assignment” of membership. This approach not only captures overlapping regions between topics but also quantifies hotspot intensity through membership degrees. The theoretical foundation of fuzzy clustering lies in fuzzy set theory, which achieves intra-class compactness and inter-class separation by minimizing the sum of weighted membership distances. Building on this, the present study integrates density-aware initialization and PSO to further enhance the model’s adaptability to dynamic changes in public opinion data distribution.
Social media network news and public opinion information typically involve multiple topics, with hotspots evolving in response to real-time changes in public opinion. This dynamic and fuzzy nature poses challenges for the accurate identification and mining of public opinion hotspots 21. Although fuzzy clustering analysis has been applied in text mining, it still faces issues such as difficulty in initializing cluster centers, slow convergence speed, and insufficient semantic representation in multi-source, real-time, and semantically complex public opinion scenarios 22,23. Therefore, building upon traditional fuzzy clustering, this paper proposes an improved fuzzy clustering method that incorporates density clustering initialization and PSO. It enhances public opinion representation through a semantic concept tree, constructs a tagged topic model, and designs an adaptive cluster center update mechanism, thereby achieving fast, accurate, and interpretable mining of public opinion hotspots. The steps for determining initial cluster centers are as follows.
-
(1)
Using a density-based clustering method, obtain a multidimensional social media network news and public opinion data collection space. Define the fuzzy clustering center of each independent dimension in this space as \(k_0\), and distribute all \(Q_c\) instances within density-reachable intervals.
-
(2)
Partition the density-reachable intervals based on \(k_0\) in each dimension, and establish labeled subsets of social media online news and public opinion data within each resulting subinterval 24. Simultaneously, compute the intersection of subintervals across dimensions in the collection space (i.e., the region where sample points are jointly contained by subintervals of multiple dimensions, representing the spatial scope for opinion hotspot mining). The consistency of data sample points is then evaluated based on the precision of this intersection. The intersection consistency evaluation expression is as follows:
\begin{equation} \label{eq:7} P_2=\dfrac{\vartheta\left(J_g\right)}{\vartheta\left[B'\left(Q_c\right)\right]}. \end{equation}In Eq. \(\eqref{eq:7}\), \(P_2\) denotes the degree of intersection exactness, i.e., whether the distribution of sample points within the intersection region satisfies the condition of belonging to subintervals across all dimensions; \(\vartheta(\cdot)\) represents the cardinality (size) of the set; \(J_g\) signifies the intersections of each dimensional subinterval that exist within the collection space; \(g\) indicates the number of intersections; and \(B'(Q_c)\) corresponds to the labeled subset of social media network news and public opinion data.
-
(3)
Based on Eq. \(\eqref{eq:7}\), a higher value of \(P_2\) indicates a greater density of sample points within the intersection region, which implies that the sample points screened through intersection are more accurate and better reflect the characteristics of multidimensional social media online news and public opinion data 25,26. Under the premise that \(P_2\) satisfies the intersection exactness corresponding to a centralized distribution state of sample points, and treating sparsely distributed sample points within \(J_g\) as isolated sample points in a virtual clustering state, an effective clustering subset \(B'(Q_c)\) that satisfies the conditions of Eq. \(\eqref{eq:7}\) can be obtained by excluding these isolated sample points.
-
(4)
Apply the \(k\)-means clustering algorithm to subset \(B'(Q_c)\) to obtain the cluster center \(k_1\) within the effective cluster subset, which serves as the initial cluster center for the fuzzy clustering analysis algorithm—that is, the centroid of each social media network news and public opinion topic to which the surrounding samples belong.
-
(5)
PSO initialization strategy and computational gain analysis
To further enhance the convergence speed and stability of fuzzy clustering, this study introduces the PSO algorithm to optimize the cluster centers. The specific implementation is as follows:
-
1)
PSO initialization strategy (particle coding): Each particle represents a set of candidate cluster centers, encoded as \(x_i=[c_1,c_2,\dots,c_K]\), where \(c_K\) is the feature vector of the \(K\)-th cluster center.
-
2)
Initial position: \(K\) samples are randomly selected from the high-density sample subset \(S_K\)—screened based on density clustering—as the initial cluster centers, with a small random perturbation added to enhance diversity.
-
3)
Initial velocity: Set as a zero vector or a small-range random vector to ensure smooth initial search.
-
4)
Parameter setting: Learning factor \(c_1=c_2=2.0\), inertia weight \(w\) linearly decreasing from 0.9 to 0.4, population size \(N=50\), and maximum iteration number \(T_{\max}\).
Computational gain is reflected in accelerated convergence, improved stability, and reduced computational overhead:
-
1)
Accelerated convergence: The traditional fuzzy clustering algorithm relies on gradient descent, which is prone to falling into local optima and exhibits slow convergence. Through group cooperation and a historical memory mechanism, PSO significantly reduces the number of iterations required for convergence.
-
2)
Improved stability: The global search capability of PSO effectively avoids fluctuations in clustering results caused by improper initial center selection, thereby enhancing system robustness in dynamic public opinion data environments.
-
3)
Reduced computational cost: Although PSO itself introduces additional computational load, its faster approach to the optimal solution results in an overall time cost lower than that of traditional fuzzy clustering, which is particularly advantageous in real-time public opinion hotspot mining scenarios.
The method proposed in this paper is comprehensively integrated across the following aspects, forming a complete solution tailored to the characteristics of social media public opinion:
-
(1)
Traditional fuzzy clustering predominantly employs random initialization. This paper constructs an initialization strategy based on density and semantic consistency by integrating simple semantic units extracted from a semantic concept tree, significantly improving convergence speed and clustering stability.
-
(2)
By constructing a text tag structure, public opinion information is organized into tags according to semantic levels, supporting real-time identification and evolution tracking of core topics and sub-topics, thereby enhancing the semantic comprehension capability of the system.
-
(3)
PSO is incorporated into the fuzzy clustering process, dynamically adjusting cluster centers through a fitness function, which effectively addresses the clustering drift problem encountered by traditional methods in scenarios with complex public opinion data distribution and fuzzy boundaries.
-
(4)
An embedded data acquisition and multi-threaded browser based on ARM and STM32 is designed, supporting parallel capture and preprocessing of large-scale real-time data and improving the overall throughput and response speed of the system.
To accurately determine whether \(B'(Q_c)\) represents a social media network news and public opinion hotspot, the PSO algorithm is employed to reduce the clustering time of the fuzzy clustering analysis and enhance the mining accuracy for such hotspots. The optimization process for mining social media online news and public opinion hotspots proceeds as follows.
-
(1)
Set the allowable error to \(\mu_1\), the learning factor to \(\mu_2\), and the population size to \(c_1\).
-
(2)
Initialize the particle swarm, where each particle within the PSO represents an initial cluster center. Each particle corresponds to a randomly generated set of hotspot cluster centers for social media network news and public opinion, with this set maintaining dimensional consistency with \(B'(Q_c)\). The fitness function for the PSO is defined as:
\begin{equation} \label{eq:8} f_3\left[B'\left(Q_c\right)\right]=\dfrac{1}{\phi\left(x_i\right)^{c_1 c_2}}. \end{equation}In Eq. \(\eqref{eq:8}\), \(f_3(\cdot)\) denotes the particle swarm optimization fitness function; \(\phi\) represents the objective function value, i.e., the individual optimal positions of the particles; \(x_i\) signifies the position of particle \(i\) in the density-reachable interval, which corresponds to a potential solution—namely, the set of hotspot cluster centers for social media network news and public opinion; and \(c_2\) indicates the number of cluster centers.
-
(3)
Introduce \(\mu_2\) to solve Eq. \(\eqref{eq:8}\) and update the position and velocity of each particle. When successive iterations cause \(x_i\) to reach the global extremum, the global optimal solution is identified from the final generation, yielding particle \(i'\). The obtained particle is compared with neighboring particles from the preceding two generations to determine whether their difference is smaller than \(\mu_1\). If the difference exceeds \(i'\), return to step 2 to reset the fitness value; if it is smaller, utilize \(i'\) for mining to obtain the hotspot of social media network news and public opinion, which corresponds to the global cluster center.
Table 1. Experimental simulation parameters.

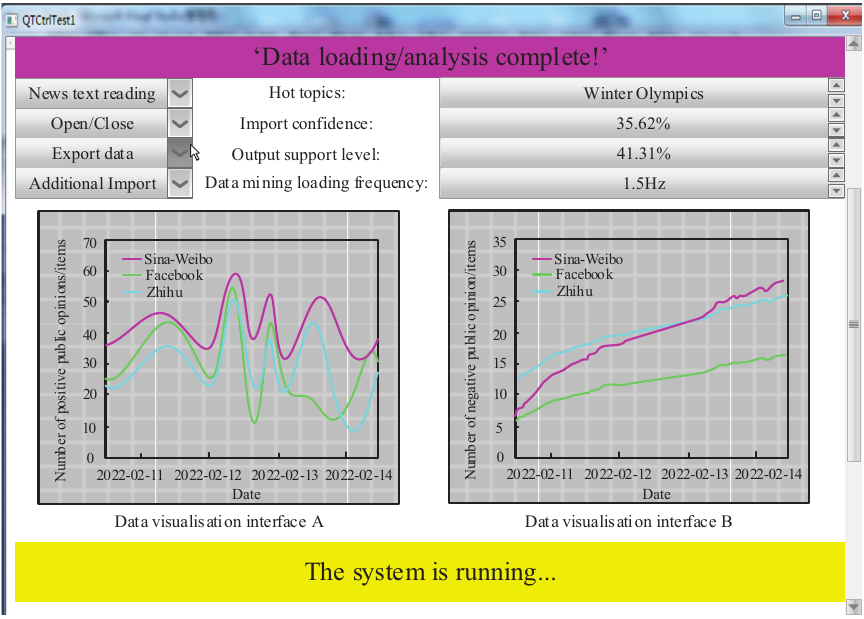
Fig. 5. Hotspot mining system environment for news and public opinion.
3. Experiment
3.1. Experimental Environment Analysis
The rationality of the designed social media network news and public opinion hotspot mining system is validated under the Windows operating system, and the test results are compared to demonstrate the system’s superior performance.
The experimental data in this study are derived from real news and public opinion data collected from Sina Weibo, Zhihu, and Facebook. A Python-based script using the Scrapy framework is employed to crawl data with the keywords “Winter Olympics” and “Watergate Bridge.” A total of 6582 recent original content entries are crawled from each platform across all categories. From these, 730 original texts with a length exceeding 25 characters per category are selected as the dataset and manually annotated with corresponding category labels. This study utilizes Jieba segmentation as the word-segmentation tool. Based on the lexical characteristics of the dataset, a new custom dictionary is created to incorporate terms such as “Bing Dwen Dwen,” “China Red,” “Four-character Brother,” “Water Gate Bridge of Changjin Lake,” “Flower Skating,” “Shuey Rhon Rhon,” “Feather Knots,” “China Red,” and “Flower Skating.” After merging the Baidu stopword list, the Harbin Institute of Technology stopword list, and the Sichuan University Machine Intelligence Laboratory stopword library and removing duplicates, the final stopword library for this study consists of 3320 words. Finally, the segmented text is vectorized using the vector space model, and text clustering is performed with an improved \(K\)-means algorithm.
The data screening process comprises the following steps:
-
Step 1:
Length filtering: Eliminate short texts containing fewer than 25 characters to prevent ineffective extraction of semantic features due to overly simplistic content.
-
Step 2:
Deduplication: Based on the SimHash algorithm, remove highly duplicated or reposted texts while retaining items with high originality.
-
Step 3:
Keyword enhancement: To ensure topic relevance and typicality, TF-IDF is combined with manual verification to preserve texts highly related to the target topic.
-
Step 4:
Balanced sampling: To maintain category balance, 365 texts are randomly selected from each of the two major topics, “Winter Olympics” and “Watergate Bridge,” forming a total of 730 experimental datasets.
The data annotation method is as follows: if the text content involves hot events or high-frequency discussion points under the topic, it is labeled as a “hotspot”; otherwise, it is labeled as a “non-hotspot.” The Kappa coefficient is used to evaluate inter-annotator agreement. The Kappa value obtained in this experiment is 0.86, indicating high reliability of the labeling results. Inconsistent samples are discussed and negotiated to determine the final label.
The system test implementation is based on the .NET 2.0 framework platform, and the backend database employs MongoDB 5.0, which supports storing news and public opinion data in JSON format. The experimental parameters are listed in Table 1.
Based on the above experimental parameters, the visualization interface of the system during the semantic feature analysis of online news and public opinion data is described and utilized as the constructed experimental environment, as illustrated in Fig. 5.
The experiment employs a 50% cross-validation mechanism, with 80% of the data used as the training set and 20% as the test set. The procedure is repeated five times to obtain stable results. All performance metrics—accuracy, recall, and time consumption—represent the macro-average results over the five repetitions, and the standard deviation is calculated to evaluate stability.
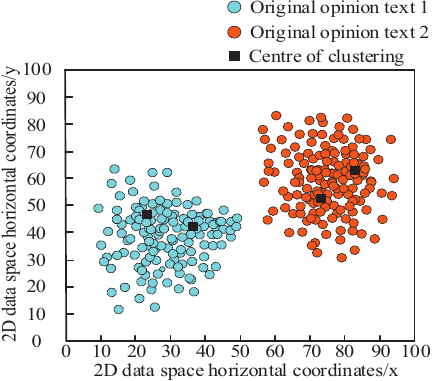
Fig. 6. Clustering effect of online news and public opinion hotspots.
3.2. Testing the Clustering Effect of Online News and Public Opinion Hotspots
To validate the data clustering performance of the designed system, the constructed original text dataset of online news and public opinion is used as an example. This dataset contains two categories of online news and public opinion hotspot information (including hotspots), namely, “Winter Olympics" and “Watergate Bridge." The rationale for selecting these topics is that both represent public events widely discussed on social media platforms, featuring complex propagation paths and distinct hotspot evolution characteristics, making them suitable for verifying the semantic modeling and clustering capabilities of the public opinion hotspot mining system. During the experimental period (2022–2023), both topics exhibit high data activity and openness, facilitating the construction of high-quality labeled datasets. In the initial phase of method validation, controlling the number of topics helps to clearly demonstrate key metrics such as clustering effect, time consumption, and accuracy, while avoiding interpretational difficulties arising from an excessive number of topics. The “Winter Olympics" topic is designated as original text data category 1, and the “Watergate Bridge" topic as original text data category 2. Using a two-dimensional data space as the presentation environment, the designed system processes the various data types within the dataset to verify its clustering performance. The results are presented in Fig. 6.
As shown in Fig. 6, the original text dataset of online news and public opinion contains two categories of data. After clustering via the designed system, the output results also comprise two categories, aligning with the actual number of original text data categories. Furthermore, the clustering results correctly assign data points of similar categories to the same cluster (with the cluster center serving as the cluster head). The data points within each cluster are densely distributed, exhibiting high overall clustering compactness. There is no occurrence of ambiguous cluster boundaries or data points simultaneously belonging to multiple clusters in overlapping regions. This demonstrates that the designed method can effectively handle uncertainty and fuzziness in public opinion data, accurately identify public opinion hotspots, and reduce misjudgments of such hotspots in online news.
3.3. Time Consumption Test of News and Public Opinion Hotspot Mining Across Progress Stages
To further analyze the efficiency of the designed system in mining social media network news and public opinion hotspots, the information mining time consumption is adopted as an evaluation metric. The methods from 4,5 are introduced as comparative baselines. The time consumed for news and public opinion hotspot mining by different methods and systems is recorded at mining progress levels of 5%, 25%, 50%, 75%, and 100%. The specific test results are presented in Table 2.
As shown in Table 2, at different stages of news and public opinion hotspot mining progress, the total mining time using the method from 4 is 27.00 s, while that using the method from 5 is 29.77 s. Both methods exhibit relatively high data mining efficiency and favorable overall application performance within the 525% hotspot mining progress range. In contrast, the designed system requires only 18.47 s to mine news and public opinion hotspots, which is lower than that of the other two methods and demonstrates stable performance in data mining applications. The system proposed in this paper consumes less time for mining public opinion hotspots compared to the methods in 4,5, with a smaller standard deviation and a statistical test \(p\)-value generally below 0.05. This indicates that the proposed method not only achieves superior efficiency but also exhibits stronger temporal stability and predictability, making it suitable for social media public opinion monitoring scenarios with high real-time requirements. Therefore, the designed system can efficiently, rapidly, and stably mine news and public opinion hotspots on social media networks, featuring high overall application efficiency and short processing time.
Table 2. Time consumption of news and public opinion hotspot mining at different progress stages.

Table 3. Comparative evaluation of public opinion hotspot mining methods.

3.4. Comparative Test of Application Effectiveness
To evaluate the practical application effectiveness of the designed system, the methods from 4,5 are adopted as comparative baselines. Accuracy and recall are employed as performance evaluation metrics, where accuracy denotes the proportion of correctly predicted positive network public opinion documents among all predicted positive network public opinion documents, and recall refers to the proportion of correctly predicted positive texts relative to the actual positive texts. These metrics effectively validate the accuracy and application stability of different methods in hotspot mining. The test results are presented in Table 3.
According to Table 3, when mining hotspot data from the “Winter Olympics” news and public opinion text category using the designed system, the accuracy is 97.52% and the recall is 98.04%. For the “Watergate Bridge” news and public opinion text category, the accuracy reaches 96.35% and the recall 97.13%. These numerical results outperform those of other comparative methods, exhibiting high recall and precision while ensuring that both metrics remain above 95% with only minor fluctuations (low standard deviation). Statistical tests further confirm the significance of the performance improvement (\(p <0.05\)). This demonstrates that the system not only enhances hotspot identification accuracy but also possesses strong robustness and consistency, enabling reliable mining of multi-category public opinion data. When processing large volumes of news and public opinion data, the designed system can comprehensively and accurately mine hotspots while effectively avoiding misclassification of non-hotspots as hotspots, indicating good practical application performance.
To provide a more comprehensive evaluation of system performance, this study also computes the macro-average F1-score as a composite metric. The F1-score is the harmonic mean of precision and recall, which offers a more balanced reflection of the model’s classification capability in the presence of imbalanced positive and negative samples. The results are presented in Table 4.
As presented in Table 4, the F1-scores of the proposed system exceed those of the comparative methods across both topic categories, further confirming its comprehensive effectiveness in hotspot identification tasks.
3.5. Multi-topic Expansion Performance Test
The performance test of multi-topic expansion is shown in Table 5.
As shown in Table 5, as the number of topic categories gradually increases from 2 to 15, the total number of texts rises correspondingly. The system’s average accuracy and recall exhibit a moderate declining trend yet remain above 90%, indicating that the proposed method retains good stability and robustness in hotspot identification under multi-topic expansion scenarios. The total time consumption increases linearly with the number of topics, while the average time per topic decreases significantly. This demonstrates that the system can effectively share computational overhead through parallel processing and optimization mechanisms when handling larger topic sets, exhibiting favorable scalability and computational efficiency. These results further confirm that the integrated system architecture proposed in this paper is not only suitable for accurate mining of small-scale topics but also applicable to real-time analysis of multi-topic, large-volume social media public opinion, possessing strong practicality and expansion potential.
Table 4. F1-score comparison of public opinion hotspot mining methods.

Table 5. Performance comparison of multi-topic expansion experiments.

4. Conclusions
Based on the above analysis, to address the limitations of traditional information processing methods in accurately and efficiently mining news and public opinion hotspots, this study proposes the design of a social media network news and public opinion hotspot mining system grounded in fuzzy clustering analysis. The approach innovatively applies fuzzy clustering to group public opinion hot topics, determines the optimal clustering centers for these topics, and thereby accomplishes the mining of news and public opinion hotspots. Experimental results demonstrate that the proposed method can effectively handle uncertainty and fuzziness in public opinion data, accurately identify public opinion hotspots, and reliably avoid misclassifying non-hotspots as hotspots, exhibiting favorable practical application performance.
Although the system performs effectively in the experimental environment, the following limitations remain:
-
(1)
The capacity to handle topic drift is limited, and dynamic tracking of long-term public opinion evolution still relies on fixed time windows.
-
(2)
The generalization capability of the model requires further validation. Currently, the experiments focus on Chinese social media platforms, and its adaptability in multilingual and cross-cultural contexts has not been fully evaluated.
-
(3)
The incremental learning mechanism for real-time streaming data is not yet fully developed, making it difficult to adequately accommodate the instantaneous data growth during public opinion outbreaks.
Future research will be conducted in the following directions:
-
(1)
Introduce an online learning mechanism to support dynamic modeling and hotspot drift tracking of streaming public opinion data.
-
(2)
Enhance multilingual text processing capabilities and construct a cross-language public opinion hotspot mining framework.
-
(3)
Incorporate reinforcement learning to optimize cluster center update strategies, thereby improving the system’s adaptability in complex public opinion scenarios.
-
(4)
Explore visualization interaction and decision-support functionalities to increase the system’s application value in public opinion monitoring.
Funding statement Not applicable. Competing interests policy The authors have no competing interests to disclose. Data availability Access to the raw data is available upon request by contacting the corresponding author.
- [1] M. A. Manzoor, S.-U. Hassan, A. Muazzam et al., “Social mining for sustainable cities: Thematic study of gender-based violence coverage in news articles and domestic violence in relation to COVID-19,” J. of Ambient Intelligence and Humanized Computing, Vol.14, pp. 14631-14642, 2023. https://doi.org/10.1007/s12652-021-03401-8
- [2] Y. Huang, D. Han, Z. He et al., “Research to identify factors influencing the country’s energy security based on text data mining technology,” Chemistry and Technology of Fuels and Oils, Vol.59, pp. 394-403, 2023. https://doi.org/10.1007/s10553-023-01539-z
- [3] I. Sokolov, E. Antonov, and A. Artamonov, “Evaluation of named entity recognition software packages for data mining,” Physics of Particles and Nuclei, Vol.55, pp. 557-559, 2024. https://doi.org/10.1134/S1063779624030791
- [4] S. R. Chowdhury, S. Basu, and U. Maulik, “Disastrous event and sub-event detection from microblog posts using bi-clustering method,” IEEE Trans. on Computational Social Systems, Vol.11, No.1, pp. 161-170, 2024. https://doi.org/10.1109/TCSS.2022.3213794
- [5] Y. Shen, “An evolution trend evaluation of social media network public opinion based on unsupervised learning,” Int. J. of Web Based Communities, Vol.20, Nos.1-2, pp. 139-152, 2024. https://doi.org/10.1504/IJWBC.2024.136653
- [6] L. Z. S. Sudar, J. L. Imbenay, I. Budi et al., “Textual analysis for public sentiment toward national police using CRISP-DM framework,” Revue d’Intelligence Artificielle, Vol.38, No.1, pp. 63-72, 2024. https://doi.org/10.18280/ria.380107
- [7] Y. Ling, Z. Ma, X. Dong et al., “A deep learning approach for robust traffic accident information extraction from online chinese news,” IET Intelligent Transport Systems, Vol.18, No.10, pp. 1847-1862, 2024. https://doi.org/10.1049/itr2.12493
- [8] M. A. Mersha, M. G. Yigezu, and J. Kalita, “Semantic-driven topic modeling using transformer-based embeddings and clustering algorithms,” Procedia Computer Science, Vol.244, pp. 121-132, 2024. https://doi.org/10.1016/j.procs.2024.10.185
- [9] H. Saragih and J. Manurung, “Leveraging the BERT model for enhanced sentiment analysis in multicontextual social media content,” J. Teknik Informatika C.I.T Medicom, Vol.16, No.2, pp. 82-89, 2024. https://doi.org/10.35335/cit.Vol16.2024.766.pp82-89
- [10] E. M. A. Stephanie, L. G. B. Ruiz, M. A. Vila et al., “Study of violence against women and its characteristics through the application of text mining techniques,” Int. J. of Data Science and Analytics, Vol.18, pp. 35-48, 2024. https://doi.org/10.1007/s41060-023-00448-y
- [11] R. S. M. Permana and C. N. Wijaya, “Peran facebook dan instagram sebagai fungsi pendukung program-program net. news,” J. Kajian Budaya dan Humaniora, Vol.6, No.3, pp. 265-276, 2024. https://doi.org/10.61296/jkbh.v6i3.279
- [12] P. R. J. Dhanith, K. Saeed, G. Rohith et al., “Weakly supervised learning for an effective focused web crawler,” Engineering Applications of Artificial Intelligence: The Int. J. of Intelligent Real-Time Automation, Vol.132, Article No.107944, 2024. https://doi.org/10.1016/j.engappai.2024.107944
- [13] J. Zhao, R. Chen, and P. Fan, “TS-Finder: Privacy enhanced web crawler detection model using temporal–spatial access behaviors,” The J. of Supercomputing, Vol.80, pp. 17400-17422, 2024. https://doi.org/10.1007/s11227-024-06133-6
- [14] P. B. Kaleel and S. Sheen, “Focused crawler based on reinforcement learning and decaying epsilon-greedy exploration policy,” The Int. Arab J. of Information Technology, Vol.20, No.5, pp. 819-830, 2023. https://doi.org/10.34028/iajit/20/5/14
- [15] A. Ghai, P. Kumar, and S. Gupta, “A deep-learning-based image forgery detection framework for controlling the spread of misinformation,” Information Technology & People, Vol.37, No.2, pp. 966-997, 2024. https://doi.org/10.1108/ITP-10-2020-0699
- [16] M. Li, C. Shan, Z. Tian et al., “Adaptive information hiding method based on feature extraction for visible light communication,” IEEE Communications Magazine: Articles, News, and Events of Interest to Communications Engineers, Vol.61, No.4, pp. 102-106, 2023. https://doi.org/10.1109/MCOM.001.2200035
- [17] E. Hossain, A. Alshahrani, and W. Rahman, “News modeling and retrieving information: Data-driven approach,” Intelligent Automation and Soft Computing, Vol.38, No.2, pp. 109-123, 2023. https://doi.org/10.32604/iasc.2022.029511
- [18] L. E. Kadhim and S. A. Fadhil, “Information security topics extraction and classification method based on modified LDA model,” J. of Discrete Mathematical Sciences and Cryptography, Vol.26, No.4, pp. 1207-1212, 2023. https://doi.org/10.47974/JDMSC-1613
- [19] N. Loukachevitch, E. Artemova, T. Batura et al., “NEREL: A Russian information extraction dataset with rich annotation for nested entities, relations, and wikidata entity links,” Language Resources and Evaluation, Vol.58, pp. 547-583, 2024. https://doi.org/10.1007/s10579-023-09674-z
- [20] P. Narang, A. V. Singh, and H. Monga, “Enhanced detection of fabricated news through sentiment analysis and text feature extraction,” Int. J. of Information Technology, Vol.16, pp. 3891-3900, 2024. https://doi.org/10.1007/s41870-024-01971-2
- [21] Z. Yang, L. Cui, X. Wang et al., “MIAR: Interest-activated news recommendation by fusing multichannel information,” IEEE Trans. on Computational Social Systems, Vol.10, No.6, pp. 3433-3443, 2023. https://doi.org/10.1109/TCSS.2022.3201944
- [22] P. Li and J. J. Liu, “Simulation of big data random mining based on improved fuzzy clustering algorithm,” Computer Simulation, Vol.41, No.2, pp. 496-499,521, 2024 (in Chinese).
- [23] I. Bombelli, I. Manipur, M. R. Guarracino, and M. B. Ferraro, “Representing ensembles of networks for fuzzy cluster analysis: A case study,” Data Mining and Knowledge Discovery, Vol.38, pp. 725-747, 2024. https://doi.org/10.1007/s10618-023-00977-x
- [24] S. Li, K. Liu, and X. Chen, “A context-aware personalized recommendation framework integrating user clustering and BERT-based sentiment analysis,” J. of Computer, Signal, and System Research, Vol.2, No.6, pp. 100-108, 2025. https://doi.org/10.71222/1cgq9333
- [25] X. Wei and Z. Wang, “TCN-attention-HAR: Human activity recognition based on attention mechanism time convolutional network,” Scientific Reports, Vol.14, Article No.7414, 2024. https://doi.org/10.1038/s41598-024-57912-3
- [26] H. Naveed, A. U. Khan, S. Qiu et al., “A comprehensive overview of large language models,” ACM Trans. on Intelligent Systems and Technology, Vol.16, No.5, Article No.106, 2025. https://doi.org/10.1145/3744746
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.