Research Paper:
Tsallis Entropy-Regularized Fuzzy c-Varieties
Haruki Kobayashi and Yuchi Kanzawa

Shibaura Institute of Technology
3-7-5 Toyosu, Koto-ku, Tokyo 135-8548, Japan

Fuzzy c-means (FCM) and its variants, including entropy-regularized FCM and Tsallis entropy-based FCM (TFCM), are widely used in fuzzy clustering. Although these algorithms are effective, they cannot model the cluster-specific subspaces that are often present in high-dimensional data. To address this limitation, fuzzy c-varieties (FCV) represent each cluster as a low-dimensional variety and iteratively alternate between dimension reduction and clustering, thereby capturing intrinsic cluster structures. Building on this, we propose a Tsallis entropy-regularized FCV (TFCV), which generalizes both standard FCV (SFCV) and entropy-regularized FCV (EFCV) by regularizing the SFCV objective with Tsallis entropy. TFCV inherits the enhanced flexibility of TFCM, leading to improved clustering performance. Theoretical analysis of the fuzzy classification functions confirmed that TFCV generalizes SFCV and EFCV. Empirical evaluations on 14 real datasets demonstrated that TFCV achieves a higher clustering accuracy than the existing methods with statistical significance, establishing its effectiveness as a robust approach that integrates dimension reduction and fuzzy clustering.
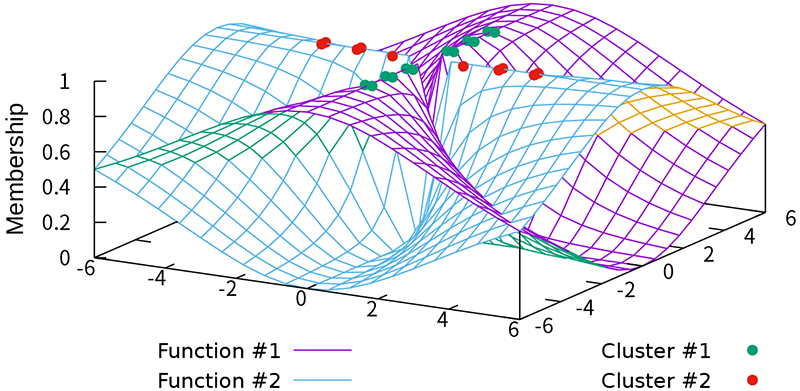
FCF example of TFCV
- [1] J. C. Bezdek, “Pattern Recognition with Fuzzy Objective Function Algorithms,” Plenum Press, 1981. https://doi.org/10.1007/978-1-4757-0450-1
- [2] S. Miyamoto and M. Mukaidono “Fuzzy c-Means as a Regularization and Maximum Entropy Approach,” Proc. 7th Int. Fuzzy Systems Association World Congress (IFSA’97), pp. 86-92, 1997.
- [3] M. Ménard, V. Courboulay, and P.-A. Dardignac, “Possibilistic and Probabilistic Fuzzy Clustering: Unification within the Framework of the Non-extensive Thermostatistics,” Pattern Recognition, Vol.36, No.6, pp. 1325-1342, 2003. https://doi.org/10.1016/S0031-3203(02)00049-3
- [4] C. Tsallis, “Possible Generalization of Boltzmann–Gibbs Statistics,” J. of Statistical Physics, Vol.52, Nos.1-2, pp. 479-487, 1988. https://doi.org/10.1007/BF01016429
- [5] J. C. Bezdek, C. Coray, R. Gunderson, and J. Watson, “Detection and Characterization of Cluster Substructure II. Fuzzy c c-Varieties and Convex Combinations Thereof,” SIAM J. on Applied Mathematics, Vol.40, No.2, pp. 358-372, 1981. https://doi.org/10.1137/0140030
- [6] G. E. Hinton, P. Dayan, and M. Revow, “Modeling the Manifolds of Images of Handwritten Digits,” IEEE Trans. on Neural Networks, Vol.8, No.1, pp. 65-74, 1997. https://doi.org/10.1109/72.554192
- [7] S. Miyamoto, H. Ichihashi, and K. Honda, “Algorithms for fuzzy clustering: Methods in c c-means clustering with applications,” Springer, 2008. https://doi.org/10.1007/978-3-540-78737-2
- [8] UCI Machine Learning Repository. https://archive.ics.uci.edu/ [Accessed August 11, 2025]
- [9] P. D. McNicholas, A. ElSherbiny, K. R. Jampani, A. F. McDaid, T. M. Murphy, and L. Banks, “pgmm: Parsimonious Gaussian Mixture Models,” R package, 2011. https://doi.org/10.32614/CRAN.package.pgmm
- [10] W. N. Venables and B. D. Ripley, “Modern Applied Statistics with S,” 4th ed., Springer, 2002. https://doi.org/10.1007/978-0-387-21706-2
- [11] G. Williams, “Data mining with Rattle and R: The art of excavating data for knowledge discovery,” Springer, 2011. https://doi.org/10.1007/978-1-4419-9890-3
- [12] G. K. Smyth, “Australasian Data and Story Library (OzDASL)," 2011. https://gksmyth.github.io/ozdasl [Accessed August 11, 2025]
- [13] Keel. http://www.keel.es. [Accessed December 23, 2025]
- [14] Kaggle, Pima Indians Diabetes Database. https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database [Accessed December 23, 2025]
- [15] L. Hubert and P. Arabie, “Comparing Partitions,” J. of Classification, Vol.2, No.1, pp. 193-218, 1985. https://doi.org/10.1007/BF01908075
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.