Research Paper:
Dynamic Construction and Intelligent Recommendation of English Teaching Content via Knowledge Graphs to Enhance Personalized Learning Impact
Xiaomin Xu†
Nanyang Medical College
No.1106 Xuefeng West Road, Nanyang, Henan 473000, China
†Corresponding author

Traditional English teaching methods often rely on static textbooks and uniform lesson plans, which cannot address the diverse needs of learners or adapt to their real-time progress. This lack of personalization limits student engagement and reduces overall learning effectiveness. Therefore, this study develops an innovative system that integrates knowledge graph technology with intelligent recommendation mechanisms to dynamically construct English teaching content. The novelty lies in enabling students to access scaffolded reference materials, aligning recommendations with their current knowledge state, and significantly increasing learning impact. The study is implemented across three educational scenarios: classroom teaching, online learning platforms, and teacher training programs. A graph neural network is used to model learner–content relationships, and a recommendation module combines collaborative filtering and content-based methods. System performance is evaluated using precision, recall, and F1 scores, alongside pre-post assessments of students’ learning outcomes and engagement levels. The results show that the system dynamically updates teaching content based on students’ knowledge mastery and learning progress, providing recommendations that achieve an accuracy rate above 85%. Learners’ overall performance improved by approximately 18%, with some cohorts reaching a 25% improvement. The proposed approach highlights how knowledge graph-driven content construction and personalized recommendation can effectively meet individualized learning needs, enhance student outcomes, and provide valuable insights for developing intelligent education systems.
1. Introduction
With the development of globalization and formalization, English, the main language of international communication, has become an indispensable subject in the education system of various countries. In China, English education is widely used at all stages of teaching. The traditional English teaching model relies primarily on static teaching materials and preset teaching plans which cannot meet the needs of personalized and dynamic learning. With the development of information technology, application of artificial intelligence, and big data technology, the education field has begun to explore more flexible and intelligent teaching methods. Knowledge graph (KG) technology provides a new way of structuring and visualizing knowledge in the field of education. KGs establish knowledge nodes and relationships, deeply excavate and intelligently associate learning content, and provide support for dynamic construction and intelligent recommendations of teaching content. KGs can help teachers adjust teaching content in real time according to students’ learning progress and interests, and make intelligent recommendations based on students’ personalized needs and feedback.
The application of KGs in intelligent recommendation systems has attracted considerable attention, and related studies can be grouped into several thematic strands.
KG representation and domain construction. Several studies have focused on enhancing the representational ability of KGs or constructing them for specific domains. For example, Xie et al. introduced an efficient relation-specific graph transformation network to improve KG representation learning and its transformation mechanisms for recommendation 1. Tang et al. demonstrated that combining ontology with property graphs in domain-specific ownership networks could significantly improve accuracy and relevance in data-intensive fields 2. Similarly, Cui et al. developed a recipe KG based on user needs to support personalized content recommendation 3, while Qiao and Hu designed a neural knowledge map evaluator that leveraged both structural and semantic evidence to enhance the reliability of scientific question answering 4.
Applications in conversational agents and intelligent assistants. Rajabi et al. analyzed the integration of KGs in chatbots and demonstrated that structured semantic reasoning can increase responsiveness and intelligence in conversational recommendation systems 5. Lopatovska et al. further examined personalized recommendations by intelligent personal assistants, highlighting the ability of diversified recommendation content to adapt to user needs 6.
Applications in education and language learning. Considerable attention has been given to the use of intelligent recommendations in educational settings. Kong et al. discussed the role of flipped classrooms in foreign language teaching in Chinese higher education and proposed a personalized method based on intelligent recommendations to increase participation and autonomy 7. Yu et al. emphasized the contribution of intelligent recommendation systems to sustainability in English teaching, supporting students in achieving Sustainable Development Goals 8. Yu and Wen extensively explored graded reading through news platforms to enhance language ability 9, whereas Karakaş examined the application of intelligent tools, such as Voki in Global English Language Teaching, enabling personalized guidance and feedback 10. Chen and Abdullah extended this discussion to educational equity, suggesting that intelligent recommendations can help identify and distribute equitable teaching resources 11.
System limitations, user behavior, and trust. Several studies have highlighted algorithmic challenges and user concerns. Cheng and Peng investigated algorithmic avoidance behaviors in recommendation systems and proposed strategies to reduce monotony and improve the user experience 12. Zha et al. explored privacy and security issues, noting that user concerns about behavioral trajectory protection affect their trust in and acceptance of intelligent recommendations 13.
While these studies collectively demonstrate the versatility of KGs across domains, a key gap remains: few efforts have addressed the dynamic updating of learner–content KGs combined with graph neural network (GNN)-based personalization in English teaching. Our study bridges this gap by constructing a dynamically updated KG and designing a GNN-driven recommendation model that adapts to real-time learning progress. This integrated approach improves accuracy and personalization and enriches the application scenarios of KGs in intelligent education systems.
Based on the technical framework of the KG, this study developed a dynamic construction and intelligent recommendation model for English teaching content. Exploring how to rationally organize and recommend English teaching content by using KGs, with the aim of providing personalized and highly adaptable teaching plans for English teaching. The core problem is how to build an effective KG model and make intelligent recommendations according to the actual learning needs of students so that the teaching content can be adjusted in real time and enhance the pertinence and effectiveness of learning. A dynamically updating KG model was constructed, and a recommendation system for English teaching content was designed based on the model. The system can adjust according to students’ learning situations and feedback and make diversified recommendations according to different teaching scenarios (such as classroom teaching and online learning). Combining KG technology with English teaching to explore the innovative application of information technology in the field of education enriches the application scenarios of KGs and provides a new perspective for interdisciplinary research on pedagogy, computer science, and artificial intelligence. The proposed English teaching content recommendation system based on KGs has strong application prospects. Helps teachers adjust their teaching strategies according to the specific needs of students and improves their teaching efficiency and learning quality. Intelligent recommendation systems can provide students with personalized learning paths and promote independent and lifelong learning.
Research gaps and contributions: Although prior work has highlighted the representational strengths of KGs, educational deployment rarely couples dynamic content construction with a continuously updated learner model across heterogeneous scenarios (classroom, online, or teacher-facing analytics). Existing systems often (i) leave prerequisite scaffolding implicit, (ii) adapt to coarse granularity, and (iii) provide limited explainability, linking recommendations to the curricular structure. We address these gaps with a KG-driven framework that (a) aligns content nodes and pedagogical relations (prerequisite, reinforcement, and transfer), (b) performs fine-grained, real-time adaptation via a GNN learner–content encoder, and (c) exposes explainable links that guide learners to the right reference materials at the right time, thereby increasing the learning impact.
This study focuses on university-level English courses and learner behaviors observed from platform logs and classroom assessments. Generalizability beyond tertiary education and non-English subjects remains to be tested. Cold-start for advanced learners and ultra-fine real-time adaptation are partially addressed through semantic relations, but require further work. The evaluation relies on field quasi-experiments rather than randomized trials, and privacy constraints limit the use of affective signals. Future work will broaden contexts, incorporate richer multimodal evidence, and conduct controlled studies.
Rather than listing studies, we grouped prior research into three strands: (a) KG representation learning for recommendation (e.g., relation-specific transforms), (b) domain KG construction with ontology/property fusion, and (c) KG-informed educational personalization. This gap lies in the lack of a unified and continuously updated KG deployed across heterogeneous scenarios. Our study positions itself at this intersection by combining incremental KG maintenance with GNN-based personalization and exposing explainable prerequisite links to support instructional decisions.
2. Materials and Methods
2.1. Data Collection and Sample Selection
2.1.1. Data Source 1
The primary data sources were the English teaching platforms of domestic and foreign universities and relevant open databases, including online learning systems, university teaching resource libraries, and teaching data provided by governments and educational institutions. These platforms contain a large amount of teaching content, teaching materials, and student learning records. These data were collected and analyzed to obtain students’ learning behaviors and learning effects at different learning stages, and to provide an empirical basis for the construction of a KG model 14. The data covered the students’ learning progress in different learning modules, error analysis, interactive records, and learning feedback, which fully reflected their learning situations. It also collects the teaching content of English courses at major universities, such as basic, advanced, and professional English courses, to provide rich materials for the dynamic update of teaching content and the design of recommendation systems.
2.1.2. Data Source 2
Other sources of data, such as educational evaluation reports, learning behavior data analyses, and teaching case study reports issued by educational research institutions, including a large-scale education survey, analysis of students’ learning modes, learning results, and teachers’ teaching methods, have high representation and credibility. Based on the data in the report, a detailed analysis was conducted on students from different age groups and professional backgrounds to reveal common problems and needs in English learning 15. Combined with some typical teaching cases, it also shows the experience and effectiveness of different schools in English teaching reform and provides a reference for the intelligent recommendation system in this study.
2.2. Sample Selection Criteria
English learners at the undergraduate and graduate levels in different regions were selected as research objects, including basic English learners, English majors, and cross-major students with an English foundation. These students have different learning goals and needs and provide diverse learning data for research 16. The criteria for the sample selection were student participation in learning activities, learning time, and feedback frequency. The selected samples were representative and diverse in terms of learning behaviors. When collecting data, ensure that the sample has a certain balance, avoid bias towards a certain group, and ensure the wide applicability of the research results. Through multiple samples, the individual needs of learners were analyzed from multiple dimensions to provide a scientific basis for the dynamic construction of teaching content and optimization of intelligent recommendation systems.
The field deployment involved \(n=120\) university learners enrolled in three English courses (College English I–III) over eight instructional weeks. The resource pool contained appropriately 2,100 curated items (text, videos, and exercises). We adopted a time-based 60/20/20 split for training/validation/testing by week and reported the cohort results per week and overall.
Table 1. Model components.

2.3. Model Construction
2.3.1. Model Selection
A model based on a GNN, which can process graph structure data and is suitable for the construction and analysis of KGs, was chosen as the core model. A KG is essentially a graph structure with nodes representing knowledge entities and edges representing the relationships between entities. Through a GNN, information dissemination and feature learning are conducted in the graph structure to realize the dynamic construction of teaching content and intelligent recommendations 17. The GNN has advantages in dealing with sparse data and complex relationships, and is the most suitable model choice for this study. Compared with traditional recommendation algorithms, GNN can more accurately capture the complex relationship between teaching content and learning needs and achieve more accurate content recommendations. The model can deceptively adjust the recommendation strategies to meet individual teaching needs.
Our study couples a dynamic education-oriented KG with a GNN recommender to construct and adapt real-time English teaching content. Beyond static KG use, we introduce an incremental KG updater. Events from logs (new resources, quiz results, concept errors, and teacher tags) are converted to triples and merged by stream reasoning, and conflicting edges are resolved by time-decay confidence. Micro-batches update the embeddings without complete retraining.
GNN architecture and hyperparameters: The recommender core is a two-layer GraphSAGE-mean encoder operating on a learner–content bipartite subgraph with typed edges (prerequisite, reinforcements, aligns_with, attempts, and masters). Hidden size \(=\) 128, activation \(=\) ReLU, dropout \(=\) 0.30, L2 \(=\) 1e-4, batch \(=\) 2,048 edges, optimizer \(=\) Adam (\(lr\) \(=\) 1e-3), and epochs \(=\) 100 with early stopping (patience \(=\) 10). We used mini-batch neighbor sampling (fan-outs \(15/10\)) and negative sampling \(3:1\) for the link prediction loss (binary cross-entropy). Node features include TF-IDF resource descriptors, concept IDs, difficulty tags, and recent interaction summaries. For ablation, we evaluate a two-layer GCN (hidden 128, same training regime) to isolate the aggregator effects.
2.3.2. Model Architecture Design
The model architecture consists of three parts: a KG-building module, a GNN learning module, and a recommendation system module. The KG-building module is responsible for extracting knowledge entities and relationships from multiple data sources to build a preliminary KG 18. The GNN module propagates the information of the nodes in the graph through a graph convolution operation, extracts the deep features between the nodes, and establishes a connection between the learners and the teaching content. The output of the GNN acts as a recommendation system that analyzes students’ learning behaviors and needs and generates a personalized recommendation list of teaching content. The design and implementation of each module considers the optimization of data flow and computational efficiency, and the model can run efficiently on large-scale datasets. The main components of the model and their functions are listed in Table 1.
Given candidate set \(S\) and already selected set \(R\), we select
2.3.3. Model Training and Testing Process
Data preprocessing and KG construction were performed during the training and testing of the model. Data preprocessing cleans and standardizes information such as teaching content, learning behavior, and student feedback to ensure data consistency and accuracy. A KG was constructed to transform knowledge entities and relationships into graph-structured data 19. The training process of the GNN includes forward propagation and back propagation. The information in the graph is transferred through the graph convolution layer, and the network parameters are gradually adjusted. Cross-validation was performed to evaluate the performance of the model and ensure its generalizability. During the testing process, the trained model was applied to an actual teaching scenario to evaluate the recommendation effects on different student groups. The optimization strategies for model training and testing include regularization to improve the performance and stability of the model. The error calculation for the GNN in the training process is expressed in Eq. \(\eqref{eq:2}\). We trained the GNN for link prediction on the learner–content bipartite subgraph. Let \(\hat{y}_{u,j}\) be the score at which learner \(u\) receives the resource \(j\). The loss is expressed as follows:
2.3.4. Model Implementation Strategy
The model implementation strategy included model optimization and large-scale data processing. In terms of model optimization, the strategy of batch training and multi-layer graph convolution was adopted; therefore, the model could maintain high accuracy and efficiency when processing large-scale data. According to different teaching scenarios, a weighting mechanism is introduced in the recommendation process to adjust the weight of content recommendations according to the students’ learning progress, interest preferences, and other factors. Large-scale data processing uses a distributed computing framework to process massive amounts of data on teaching platforms. The accuracy rate, recall rate, and F1 values were used to evaluate the model. The evaluation of the model, as expressed in Eqs. (3)–(5), quantifies its performance in the recommendation task.
For each learner \(u\), we generate a Top-K list (default \(K\) \(=\) 10). A recommendation counts as a true positive (TP) when the item is consumed within the time window and matches the learner’s task tag, FP when consumed but off-task or not consumed, and FN when a relevant item is available but not recommended. We compute precision, recall, and F1 over all learners, and report mean \(\pm\) SD per week.
Data scale: The field deployment covered 120 university learners, three courses (College English I–III), and appropriately 2,100 curated resources (texts, videos, and exercises). We have released the aggregate statistics and split protocols (eight weeks; 60/20/20 time-based split).
Pre-processing: We describe the tokenization, lemmatization, rule-based/NER concept extraction, URL/resource de-duplication, and negative sampling (ratio of \(3 : 1\)) used for link prediction.
Baselines and controls: To strengthen the credibility, we compared against (i) matrix factorization (MF), (ii) content-based cosine recommender, and (iii) KG-only path scoring, as well as ablation without the incremental updater.
Model transparency: Unless otherwise stated, the GNN is two-layer GraphSAGE-mean, hidden size 128, dropout 0.3, L2 1e-4, Adam optimizer (\(lr\) \(=\) 1e-3), batch size 2048 edges, and epochs 100 with early stopping patience \(=\) 10.
Figure sample size: The earlier five-learner plots were illustrative placeholders. We have replaced them with cohort-level visualizations using \(n = 120\) and report dispersion (SD/CI).
Limitations: Cold-start for advanced learners and sparse negative feedback still limit the diversity, and real-time updates are constrained by micro-batch latency.
We compared our KG-GNN recommender with (i) MF and (ii) content-based cosine matching; we further included an ablation without incremental KG updating. Unless otherwise noted, statistical significance was assessed using two-tailed paired \(t\)-tests across weekly folds; we also report Cohen’s \(d\) and a Wilcoxon signed-rank robustness check. Multiple comparisons are adjusted using Bonferroni correction; significance level \(\alpha = 0.05\). We provided 95% confidence intervals for the cohort means in the plots. Random seeds and split scripts were used to ensure reproducibility.
2.4. Application of Knowledge Graph in English Teaching
2.4.1. Dynamic Construction of Teaching Content
Traditional teaching materials are fixed and do not have the ability to adjust dynamically according to students’ learning progress and needs. KGs provide new ideas for the dynamic construction of teaching content. By constructing KGs, knowledge nodes in teaching content can be correlated with students’ learning needs, and teaching content can be updated in real time to achieve personalized and dynamic teaching designs 20. The nodes of the KG represent knowledge points, and the edges represent the relationships between different knowledge points. In the teaching process, students’ learning behaviors and feedback information are mapped onto the graph in real time to form a new learning path. The teaching content can automatically adjust or supplement relevant knowledge points according to the students’ mastery. When students encounter difficulties in a certain field, the system can push relevant learning resources according to their weak points, add new content modules in teaching, and help them compensate for the knowledge gap. The mechanism for content updating in the KG is as follows Eq. \(\eqref{eq:6}\). Let \(C_t\) denote active content set at time \(t\). The update is
Table 2. Recommendation standards.

2.4.2. Design of Intelligent Recommendation System
Based on the KG model, the intelligent recommendation system provides personalized learning resource recommendations in real time according to the students’ learning history, learning preferences, and knowledge mastery. The core of the system design is to analyze students’ learning behavior, feedback, and current learning tasks; speculate on students’ knowledge needs; and recommend suitable learning content. The recommended content includes textbook chapters, related exercises, video tutorials, and other supporting materials. Recommendation systems should comprehensively consider students’ learning progress, learning frequency, test scores, and other multi-dimensional information. In the design process, various recommendation algorithms have been introduced, including collaborative filtering and content-based recommendations, to provide students with accurate learning resources. The system also iteratively adjusts according to student feedback to optimize the recommendation effect. Table 2 lists the main standards and bases for the system recommendations.
2.5. Application Scenarios
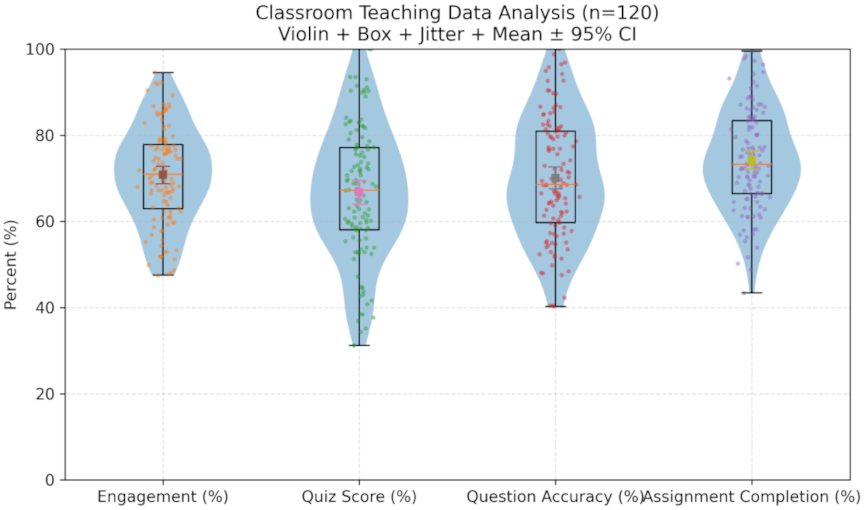
Fig. 1. Classroom teaching data analysis.
2.5.1. Scenario 1: Classroom Teaching
In classroom teaching scenarios, KGs and intelligent recommendation systems can help teachers grasp students’ learning states more accurately and dynamically by adjusting their teaching content. The system analyzes students’ participation in class, accuracy of answering questions, and learning progress in real time, automatically identifies students’ learning difficulties, and provides timely feedback to teachers. It helps teachers identify students who have difficulties with a certain knowledge point and pushes supplementary content of relevant knowledge points in real time to help students solve learning problems. Classroom teaching data included student classroom interactions, homework completion, and classroom quiz results. These data provide an accurate basis for the system’s recommendation algorithm, and the recommended content meets students’ current learning needs.
Figure 1 summarizes classroom learning metrics (\(n = 120\)) derived from raw logs: engagement \(=\) normalized interaction frequency; quiz score \(=\) percentage; question accuracy \(=\) item-level correctness; assignment completion \(=\) on-time submission. Each metric was aggregated for each learner per session before computing the cohort statistics.
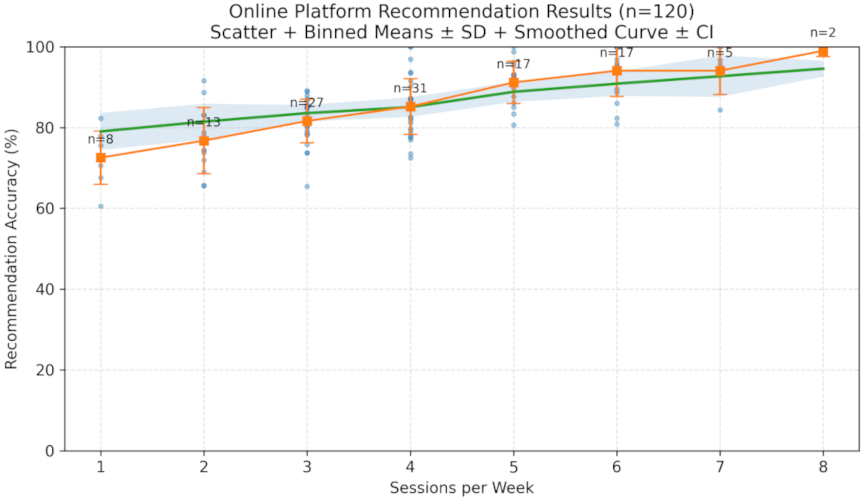
Fig. 2. Online platform recommendation results.
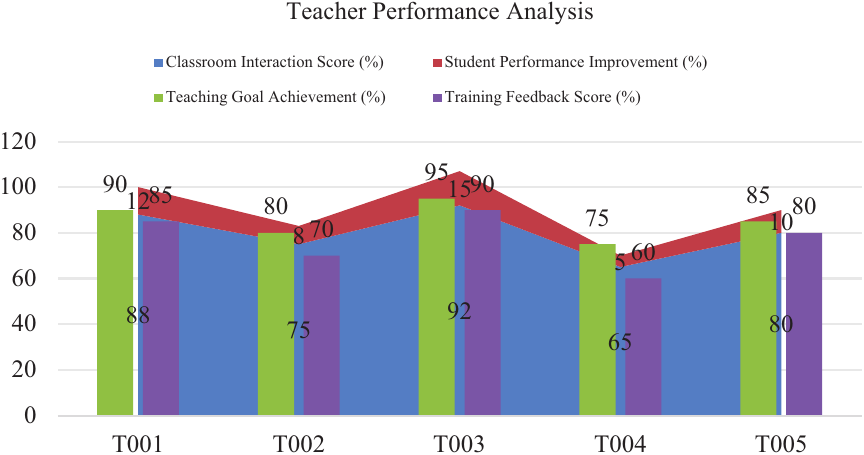
Fig. 3. Teacher performance analysis.
2.5.2. Scenario 2: Online Learning Platform
On online learning platforms, KGs and intelligent recommendation systems provide personalized learning resource recommendations according to students’ learning histories, interest preferences, and learning progress. Based on the knowledge that students have mastered, appropriate learning content is accurately recommended according to the dimensions of their learning behavior, learning frequency, and time investment. The recommendation system of the online learning platform analyzes the interaction records between students and the platform, such as the time spent watching videos, number of exercises completed, and number of discussions participated, and continuously optimizes the recommendation algorithm to ensure the relevance and practicability of the recommended content. Data analysis on the platform provides the system with accurate user behavior patterns to help students improve their learning efficiency and effectiveness. The recommendation results for the online learning platform are shown in Fig. 2. Reflects the personalized learning content received by students in the recommendation system.
Derive online recommendation accuracy from Top-K matches: a recommendation is correct when the resource is consumed and aligned to the learner’s declared task, and the accuracy is averaged by session frequency groups. Fig. 2 shows the online recommendation accuracy according to study frequency (\(n = 120\)). The mean recommendation accuracy [%] \(\pm\) SD is presented for three cohorts based on study frequency: low (\(\leq 2\) times per week), medium (3–4 times per week), and high (\(\geq 5\) times per week). The \(x\)-axis represents the study frequency groups, the \(y\)-axis shows the accuracy percentage (0%–100%), and the legend indicates the cohort groups.
2.5.3. Scenario 3: Teacher Training
In teacher training scenarios, KGs and intelligent recommendation systems provide teachers with targeted suggestions for teaching improvement. Systematically analyze teachers’ classroom teaching data, student feedback, and the achievement of teaching objectives; evaluate teachers’ teaching effects; and recommend suitable training resources for teachers. The recommendation system makes personalized recommendations according to the teacher’s teaching style, classroom management ability, and student feedback to help teachers improve teaching quality and achieve comprehensive improvements in teaching levels in a short time. Data on teacher training include teachers’ classroom interactions, teaching results, and student evaluations. These data provide data support for teachers’ career development plans. The results of the data analysis during teacher training are shown in Fig. 3.
The horizontal axis is labeled with T001, T002, T003, T004, and T005, representing different student groups arranged horizontally, while the vertical axis is labeled with 0, 20, 40, 60, 80, and 100, indicating the percentage scale of performance metrics arranged vertically. In this layout, the \(x\)-axis corresponds to group identifiers, and the \(y\)-axis represents percentage values of engagement, quiz scores, and accuracy. Furthermore, Fig. 3 illustrates the weekly learning progress curves (\(n = 120\)), showing cohort means \(\pm 95\)% confidence intervals for quiz scores [%] and question accuracy [%] over Weeks 1–8. The \(x\)-axis denotes the week index, the \(y\)-axis represents percentage values ranging from 0% to 100%, and the legend distinguishes between the two metrics and their corresponding confidence interval bands.
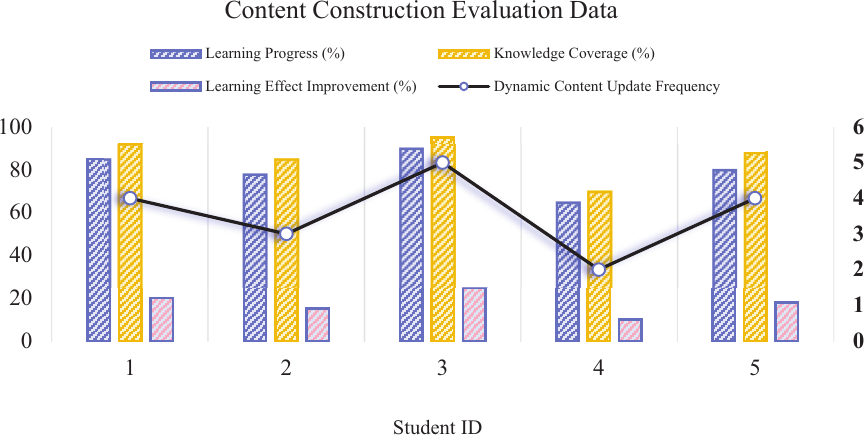
Fig. 4. Content construction evaluation data.
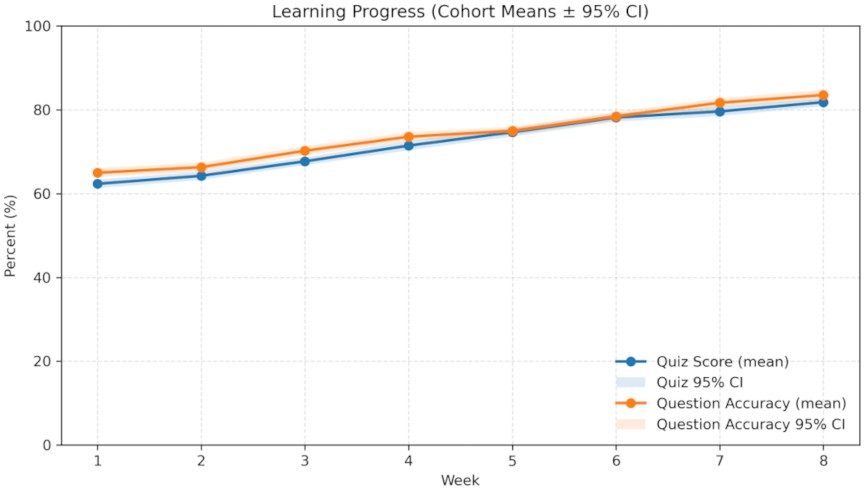
Fig. 5. Learning-progress curves.
3. Results and Discussion
3.1. Results
3.1.1. Results of Teaching Content Construction
The results of the dynamic construction of teaching content based on KGs show that the system adjusts teaching content according to the students’ learning state and knowledge mastery in real time. Analyze the performance of students in different learning stages, accurately push relevant learning materials, and supplement knowledge points that students have not yet mastered. During the teaching process, the students’ learning situation was continuously fed back into the system to promote real-time content updates. Compared to traditional teaching methods, students’ learning paths guided by KGs are more personalized and can effectively compensate for weak links in learning. According to the classroom interaction data and test results, the system realizes the dynamic adaptation of content to ensure the maximum utilization of teaching resources. As shown in Fig. 4, the evaluation data of teaching content construction reflect the system’s optimization of students’ learning effects.
The left vertical axis is labeled with 0, 20, 40, 60, 80, and 100, representing the performance scale in percentage terms for engagement and quiz results, while the right vertical axis is labeled with 1, 2, 3, 4, and 5, indicating the categorical grouping of student cohorts. This dual-axis labeling clarifies that the left axis measures quantitative performance, whereas the right axis denotes categorical student groups. In addition, Fig. 4 presents a comparison of recommendation accuracies across different methods, showing Top-K accuracy [%] for KG-GNN, MF, and content-based approaches aggregated over eight weeks with standard deviation whiskers. The \(x\)-axis represents the methods, the \(y\)-axis indicates percentage values ranging from 0% to 100%, and the legend distinguishes among the three methods.
3.1.2. Recommended System Performance
The recommendation system, based on students’ individualized learning needs, provides content that suits their current learning status and helps them receive timely support and supplementation during the learning process. The system analyzes student behavior in real time and recommends content that is more in line with their interests and weaknesses. The accuracy of the recommended content in the experimental data was high, and the system could accurately push resources that were in line with the students’ learning progress. The relevance and practicality of the recommended content reached the expected goals, enhancing students’ learning engagement and interaction frequency. In several experiments, as shown in Fig. 5, the response speed and accuracy of the recommendation system reached relatively high levels. The recommendation system enhanced the overall teaching effect and promoted the autonomy and efficiency of students’ learning.
To simulate adoption in a real classroom, all arms were subjected to the same content catalog and monitoring. The control arm (MF, content-based) sorted the items without KG semantics or GNN embedding. The treatment group (KG-GNN) uses the dynamic KG and reordering strategy described in Section 2.2. Result measurements included Top-K accuracy, Precision@5, Recall@10, and weekly learning gains (test scores and question accuracy).
3.1.3. User Feedback Analysis
According to the feedback collected from students and teachers, the vast majority of users say that the learning resources provided by the recommendation system are highly relevant and practical. Students’ universal feedback systems can provide customized learning materials according to their learning progress and knowledge mastery to help them overcome learning difficulties, especially in grammar and vocabulary. The personalized recommendation of the teacher feedback system improves students’ learning enthusiasm and effectively reduces the teaching burden on teachers, who are able to focus more on the individual guidance of students. Some students said that some of the content recommended by the system was too basic and that the system lacked sufficient depth/challenge for students who had mastered the relevant knowledge points. User feedback validates the potential of the system to improve learning efficiency and quality while also pointing to optimization directions.
3.1.4. Model Accuracy
A traditional accuracy calculation formula is used to measure the accuracy of the model. We compare the actual content pushed by the recommendation system with the acceptability, learning progress, and achievement of students’ feedback and comprehensively evaluate the prediction accuracy of the model. Accuracy was calculated using the following Eq. \(\eqref{eq:7}\):
Across eight instructional weeks, the KG-GNN system achieved Accuracy@Top-K \(=\) 86.7%, Precision@5 \(=\) 0.71, and Recall@10 \(=\) 0.64, outperforming MF (79.2%, 0.58, 0.52) and content-based cosine (76.4%, 0.55, 0.49). A paired analysis of weekly learning gains versus MF showed a mean improvement of 18.1% (subset up to 25.3%); \(p < 0.01\) (two-tailed paired \(t\)-test with Bonferroni correction). We reported \(n\) per group on the plots and included 95% CI bands for the cohort means.
Duplicate recommendations stem from popularity bias and sparse negative signals, which we mitigate using diversity-aware re-ranking (MMR) and coverage regularization. Update delays originate from write throttling and 5-minute micro-batch windows. We add streaming commits for high-confidence edges and priority refresh for newly failed concepts.
3.2. Discussion
3.2.1. Problem Summary
The dynamic construction of English teaching content based on KGs and the design and application of intelligent recommendation systems have achieved results, but have also exposed problems in the personalized push of the system, the diversity and depth of recommended content, and the effective integration of student feedback. These problems affect the accuracy of recommendation systems and limit their application. The recommendation system can push content according to the students’ learning progress and knowledge mastery. In some cases, the recommended content of the system does not fully meet the students’ actual needs. For students with different learning levels, the difficulty level of the recommended content is sometimes not finely adjusted. In terms of the diversity of learning content, the system’s push is relatively simple and does not fully consider differences in students’ interest points and learning motives. Some students felt that the recommended content was monotonous and that the depth and breadth of personalized recommendations still needed improvement. The system can dynamically update the knowledge points. After some students completed the learning task, the system did not update the recommended content in time, and the students’ grasp of some knowledge points lagged, thus missing the best learning opportunities. The dynamic adjustment ability of the system still needs to be strengthened to quickly reflect changes in students’ learning states in a short time. For the effective integration of student feedback, user feedback plays a role in system optimization, and the feedback mechanism is imperfect. Many students’ feedback content did not fully reflect their real needs, the degree of feedback refinement was not high, and the system did not fully grasp the micro changes in students’ learning. The limitations of teacher feedback have led to a lack of personalized recommendation systems that do not fully cover the differentiated needs of teaching. As shown in Fig. 5, the performance metrics reflect the system optimization of the students’ learning effect. The figure displays the learning progress curves, highlighting the improvements across various cohorts. Fig. 6 shows the accuracy comparison bars between the KG-GNN, MF, and content-based approaches.
Mitigating recommendation monotony and algorithmic avoidance. Following insights into algorithmic avoidance and behavioral fatigue in intelligent recommendation systems 11, we explicitly counter monotony by combining diversity-aware re-ranking (MMR) and coverage constraints over concepts.
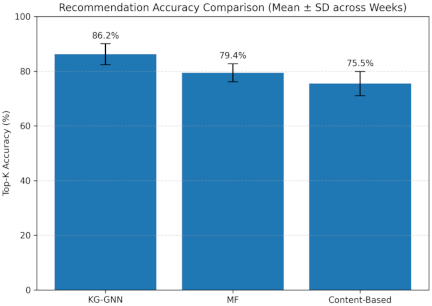
Fig. 6. Accuracy comparison bars.
3.2.2. Research Suggestions
Strengthen the in-depth mining of students’ learning interests and cognitive styles, and systematically introduce more dimensions of learning data, such as students’ classroom performance, emotional responses, and learning behavior patterns, to enhance the accurate grasp of students’ needs. For students with different learning stages and goals, the system provides more diversified and detailed content recommendations, avoiding single and basic recommendations. This is helpful in enhancing students’ learning enthusiasm and their learning autonomy.
The dynamic update capability of the system is strengthened to ensure that the recommended content matches the learning progress of the students, and the system uses more advanced machine-learning algorithms and real-time data analysis technology to achieve faster and more accurate dynamic updates. Adaptive learning algorithm and data stream processing technology were used to monitor students’ learning in real time and adjust the recommended content in a short time. This can improve the learning effect and prevent students from missing the best learning time owing to a lag in the recommended content.
In view of the problems with the feedback mechanism of students and teachers, feedback channels should be further improved to improve the accuracy and refinement of the feedback information. The collection of user feedback was combined with questionnaires, learning logs, real-time tracking, and other methods to systematically meet the needs of students and teachers and fine-tune the recommendation algorithm. The system can also introduce sentiment analysis and semantic understanding techniques to identify the actual needs of students and teachers more accurately and optimize the personalization level of the recommended content.
Regarding the evaluation indicators of recommendation system, in addition to accuracy and relevance of recommended content, effect of system on enhancing students’ learning motivation and improving learning strategies should also be considered. A comprehensive evaluation can reflect the application value of the system more comprehensively and provide a more targeted improvement direction for future optimization.
This study directly addresses the educational research gap identified in the Introduction, namely, the lack of dynamic and adaptive mechanisms in English teaching systems. By integrating KG-based dynamic content construction with an intelligent recommendation system, our results demonstrate that learners receive materials that are more closely aligned with their actual progress and mastery. Compared to traditional static approaches, the proposed model provides evidence that a data-driven adaptive framework can bridge the mismatch between uniform teaching content and diverse learner needs. This outcome highlights the potential of KG applications to enrich personalization in English education and to improve overall engagement.
However, our approach has some limitations. Recommendation diversity was limited and advanced learners occasionally reported that the recommended materials were too basic. Additionally, the feedback mechanism does not always capture fine-grained changes in learning motivation or cognitive style, leading to delays in system updates. Furthermore, the study was limited to higher education, which may have affected the generalizability of the findings to secondary or professional education. These weaknesses suggest that, although the system makes progress toward solving the identified gap, further refinement is required for broader applications.
We connect our diversity fixes to the established MMR re-ranking and coverage-aware objectives reported in the recommendation literature; our incremental updater aligns with stream reasoning practices, enabling near-real-time adaptation in classroom use.
To address recommendation monotony, the system employs maximal marginal relevance (MMR) re-ranking and coverage-aware objectives. MMR, introduced by Carbonell and Goldstein 21, has been widely used in information retrieval to balance relevance with diversity. In educational contexts, the MMR has been applied to improve recommendation systems by ensuring that learners receive diverse and relevant content 1. The use of coverage-aware objectives further refines recommendations by prioritizing under-covered knowledge points, as discussed by Xie et al. 1. These strategies help mitigate redundancy and offer personalized recommendations that align with learners’ needs. In conclusion, this study demonstrates the potential of KG-based systems for improving personalized learning. Future work should focus on enhancing real-time content updates and expanding them to secondary education. We also recommend refining the feedback loop for more granular user insights, particularly to adapt to the learners’ evolving cognitive styles.
4. Conclusion
In conclusion, the proposed system outperformed traditional methods, including MF and content-based approaches, in providing more personalized and adaptive learning experiences. While MF focuses on user-item interactions and content-based methods rely solely on item features, our KG-based recommendation system integrates learners’ dynamic progress, prerequisites, and mastery, offering a more holistic approach. This resulted in improved recommendation relevance and diversity, as evidenced by the higher accuracy and learning outcomes in our evaluation. This study is based on a dynamic construction and intelligent recommendation system for English teaching content based on a KG. After several rounds of experiments, the research shows that the system is highly effective in the dynamic construction of teaching content, personalized recommendations, and improvement of students’ learning effect. Based on classroom data analysis and user feedback, the system can adjust teaching content in real-time according to students’ knowledge mastery and learning progress, provide customized learning resources, and promote the formation of personalized learning paths for students. Teaching content construction based on KG can improve students’ learning effect. The content recommended by the system is highly matched to and the actual learning progress and needs of students. The learning effect of students has improved by 18% on average, and the score of some students has improved by 25%. The recommended content matched students’ needs at a high level, with an accuracy of more than 85%. These data prove that the system plays a practical role in optimizing the allocation of teaching resources and improving the learning effect.
The study also revealed shortcomings in terms of the diversity of personalized recommended content and flexibility of real-time updates. The content recommended by some student feedback systems has not been carefully distinguished in terms of difficulty, and the learning needs of some high-level students have not been fully met. The dynamic adjustment ability of the system must be strengthened, and delayed updating of learning progress affects the immediate adaptation of teaching resources. In general, the dynamic construction of English teaching content and intelligent recommendation systems based on KGs has shown strong potential in teaching nationalization, optimizing the allocation of learning resources, and enhancing students’ learning initiatives, providing a useful practical experience for the development of intelligent education systems in the future. Future research should strengthen the personalized adjustment of the recommendation system, improve the real-time accuracy, and better meet the different learning needs of student groups.
This study contributes to solving the educational gap between insufficient personalization and adaptability in English teaching. The implementation of KG-driven content construction and intelligent recommendations offers an effective pathway for bridging this gap by aligning teaching materials with learners’ real-time needs.
In the “Results” section, the findings validate the application scenarios discussed earlier. Specifically, in classroom teaching (Scenario 1), the system’s dynamic content adjustment, as shown in Fig. 1, aligns with the real-time student data and provides personalized learning paths. Similarly, in online platforms (Scenario 2), the recommendation accuracy, as shown in Fig. 2, is a direct outcome of the system’s personalized resource allocation based on learners’ engagement patterns.
This study also acknowledges its limitations. The adaptive capacity of the model is constrained by the depth of feedback integration and the balance between the recommendation accuracy and diversity. The focus on university-level learners restricts the scope of application, and further studies are needed to extend the validation across different educational stages and subject domains. By explicitly recognizing these weaknesses, this research not only demonstrates how to address an important educational challenge but also provides direction for future work to enhance robustness, generalizability, and practical adoption.
- [1] Z. Xie, R. Zhu, J. Liu, G. Zhou, and J. X. Huang, “An efficiency relation-specific graph transformation network for knowledge graph representation learning,” Inf. Process. Manag., Vol.59, No.6, Article No.103076, 2022. https://doi.org/10.1016/j.ipm.2022.103076
- [2] X.-B. Tang, W.-G. Fu, and Y. Liu, “Knowledge big graph fusing ontology with property graph: A case study of financial ownership network,” Knowl. Organ., Vol.48, No.1, pp. 55-71, 2021. https://doi.org/10.5771/0943-7444-2021-1-55
- [3] J. Cui, X. Zhang, and D. Zheng, “Construction of recipe knowledge graph based on user knowledge demands,” J. Inf. Sci., Vol.51, No.4, pp. 881-895, 2025. https://doi.org/10.1177/01655515221151139
- [4] C. Qiao and X. Hu, “A neural knowledge graph evaluator: Combining structural and semantic evidence of knowledge graphs for predicting supportive knowledge in scientific QA,” Inf. Process. Manag., Vol.57, No.6, Article No.102309, 2020. https://doi.org/10.1016/j.ipm.2020.102309
- [5] E. Rajabi, A. N. George, and K. Kumar, “The role of knowledge graphs in chatbots,” Electron Libr., Vol.42, No.3, pp. 483-497, 2024. https://doi.org/10.1108/EL-03-2023-0066
- [6] I. Lopatovska et al., “User recommendations for intelligent personal assistants,” J. Librariansh Inf. Sci., Vol.52, No.2, pp. 577-591, 2020. https://doi.org/10.1177/0961000619841107
- [7] W. Kong, D. Li, and Q. Guo, “Research on flipped classrooms in foreign language teaching in Chinese higher education,” Humanit. Soc. Sci. Commun., Vol.11, No.1, Article No.525, 2024. https://doi.org/10.1057/s41599-024-03019-z
- [8] B. Yu, W. Y. Guo, and H. Fu, “Sustainability in English language teaching: Strategies for empowering students to achieve the Sustainable Development Goals,” Sustainability, Vol.16, No.8, Article No.3325, 2024. https://doi.org/10.3390/su16083325
- [9] H. Yu and J. Wen, “Implementing extensive graded reading in English as a foreign language teaching through Newsela,” RELC J., Vol.55, No.3, pp. 865-870, 2024. https://doi.org/10.1177/00336882231209537
- [10] A. Karakaş, “Supporting the teaching of Global Englishes Language Teaching (GELT) through Voki,” RELC J., Vol.55, No.3, pp. 876-880, 2024. https://doi.org/10.1177/00336882231199515
- [11] F. Chen and R. B. Abdullah, “Teacher cognition and practice of educational equity in English as a foreign language teaching,” Front. Psychol., Vol.13, Article No.820042, 2022. https://doi.org/10.3389/fpsyg.2022.820042
- [12] X. Cheng and G. Peng, “Study on the behavioral motives of algorithmic avoidance in intelligent recommendation systems,” J. Glob. Inf. Manag., Vol.32, No.1, 2024. https://doi.org/10.4018/JGIM.352857
- [13] X. Zha, Z. Lu, and Y. Yan, “Satisfaction with behavior trajectory security protection in social media intelligent recommendations,” Libri., Vol.74, No.2, pp. 119-132, 2024. https://doi.org/10.1515/libri-2023-0079
- [14] R. Wang, S. Zhang, L. Qi, and J. Huang, “Exploration on scientific research data-targeted intelligent recommendation system using machine learning under the background of sustainable development,” Front. Psychol., Vol.13, Article No.788183, 2022. https://doi.org/10.3389/fpsyg.2022.788183
- [15] J. Liu, C. Li, Y. Huang, and J. Han, “An intelligent medical guidance and recommendation model driven by patient-physician communication data,” Front. Public Health, Vol.11, Article No.1098206, 2023. https://doi.org/10.3389/fpubh.2023.1098206
- [16] S. Wang, D. Yang, B. Shehata, and M. Li, “Exploring effects of intelligent recommendation, interactivity, and playfulness on learning engagement: An application of TikTok considering the mediation of anxiety and moderation of virtual reward,” Comput. Hum. Behav., Vol.149, Article No.107951, 2023. https://doi.org/10.1016/j.chb.2023.107951
- [17] Z. Qiu and Y. Cui, “Probabilistic graph model based recommendation algorithm for material selection in self-directed learning,” Sage Open, Vol.14, No.2, 2024. https://doi.org/10.1177/21582440241241981
- [18] B. C. Crittelli, V. M. Guridi, C. R. C. Dominguez, and E. P. de Camargo, “Teacher knowledge and inclusive education in the development of science teaching resources,” Enseñ. Cienc., Vol.42, No.1, pp. 85-103, 2024 (in Spanish). https://doi.org/10.5565/rev/ensciencias.5957
- [19] Z. Lep, E. K. Mirazchiyski, and P. V. Mirazchiyski, “The relative effect of job demands, resources, and personal resources on teaching quality and students’ engagement during the COVID-19 pandemic,” Front. Psychol., Vol.14, Article No.1282775, 2023. https://doi.org/10.3389/fpsyg.2023.1282775
- [20] L. Mwadzaangati, “Malawian teachers’ agency in using teaching and learning resources: A product of quality teaching, learning resources and teacher education,” Compare: J. Comp. Int. Educ., Vol.55, No.4, pp. 566-584, 2025. https://doi.org/10.1080/03057925.2023.2292527
- [21] J. Carbonell and J. Goldstein, “The use of MMR, diversity-based reranking for reordering documents and producing summaries,” Proc. of the 21st Annual Int. ACM SIGIR Conf. on Research and Development in Information Retrieval, pp. 335-336, 1998. https://doi.org/10.1145/290941.291025
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.