Research Paper:
A Hybrid Collaborative Filtering and LDA-Based Subject Model for Bidirectional Employment
Dijing Hao†
Yellow River Conservancy Technical University
No.1 Dongjing Road, Kaifeng, Henan 475004, China
†Corresponding author

To optimize employment matching in colleges and universities, a hybrid bidirectional model was designed to recommend suitable companies to graduates and vice versa. First, the resume submission records of graduates and interview invitation data from enterprises were integrated to construct a sparse matrix, and K-means clustering was applied to fill missing values and mitigate data sparsity. Resumes and recruitment texts were analyzed using a latent Dirichlet allocation (LDA) topic model, combined with TF-IDF weighting, to generate a graduate–enterprise feature vector space. By dynamically weighted fusion of collaborative filtering (CF) similarity and topic model similarity, a hybrid recommendation coefficient was obtained to achieve efficient bidirectional recommendation. Experimental results revealed that the CF-LDA model constructed with weight coefficients (M=0.45 and N=0.55) significantly improved recommendation performance: the overlap rate between graduate resumes and enterprise recommendations reached 92%, the overlap rate between enterprise interview invitations and recommended talents reached 96%, and user activity increased by more than threefold (graduates and enterprises spent 65 and 141 min online per day, respectively). Compared with a single CF or LDA model, its recall rate increased by 18%–28% and the RMSE reduced by 23%–45% on publicly available datasets such as MovieLens 10M, verifying the effectiveness and generalization ability of the model. The data results indicate that the research model provides effective employment recommendation information for graduates and enterprises, improving the efficiency of graduates’ job search and enterprise recruitment.
1. Introduction
At present, there is a significant employment paradox in society that college graduates find it difficult to secure jobs, and enterprises similarly find it difficult to recruit, making it increasingly important to provide enterprises with personalized employment recommendations 1. However, traditional resume screening and recruitment methods have low efficiency and unclear targets 2,3. It is unable to achieve dynamic coupling between graduate demands and corporate standards. Although the collaborative filtering (CF) model can utilize the user’s historical behavior, it relies heavily on historical interaction data, which leads to cold-start issues. An excessive focus on subjective interests and preferences neglects the dynamic constraints of recruitment standards in enterprises. The latent Dirichlet allocation (LDA) topic model can parse text semantic features. However, it relies solely on static text analysis and cannot capture the implicit decision logic of user behavior, resulting in recommendation results that deviate from actual needs 4,5. Therefore, this study proposes a hybrid bidirectional topic model based on CF-LDA. By comprehensively utilizing the advantages of the CF model and LDA topic, it is expected to achieve accurate matching of “graduates \(\to\) positions, enterprises \(\to\) talents.” The CF-LDA hybrid model constructs a heterogeneous interaction matrix between graduates and enterprises, and tackles the data sparsity through \(K\)-means clustering filling, achieving bidirectional demand integration between college students and enterprises. Simultaneously, the weight of the model design can be adjusted to the mixed coefficient, and behavior similarity and semantic matching can be adaptively balanced, breaking the limitations of a single model. In addition, synchronously evaluating the overlap rate of graduate matching \(\to\) positions and enterprises \(\to\) talents in this model can solve the bias of traditional one-way evaluation.
The research contribution lies in modeling the ability preferences of graduates and the employment standards of enterprises through heterogeneous data synchronization, designing a dynamic weighted fusion strategy, and solving the cold-start problem of a single CF model and the semantic static defects of a single LDA model.
The research is mainly divided into four parts. The first part describes the current research status of employment recommendation methods in colleges and universities at home and abroad and the application of the CF algorithm and LDA topic model. The second part describes the specific construction method of the employment recommendation model based on the CF algorithm and the employment recommendation model based on the LDA topic and then integrates the advantages of both to construct a hybrid recommendation model. The third part focuses on designing experiments to test the effectiveness of the recommendation model and its practical application. The fourth part summarizes and analyzes the test results of the application effect of the hybrid recommendations and explains the shortcomings of the recommendation model.
2. Related Works
College graduates currently face employment pressures and confusion regarding their career choices. To help them better understand market demands and discover suitable career opportunities for themselves, many scholars at home and abroad have studied the graduate employment problem in a general sense. Guo proposed a method based on GM(1,1) to effectively predict the graduate employment rate. This method works by smoothing the fluctuations of raw data into a buffer series, based on which future trends are predicted. The results demonstrate that the method has good accuracy and stability in predicting the employment rates of university graduates 6. Lin studied the challenges faced by senior graduates in terms of employment. Suggestions, including the provision of career planning guidance, job skills training, internships, and entrepreneurial support, were made to improve the employment outcomes of higher vocational graduates 7. Yang et al. explored the employment needs and current situation of college students and analyzed the causes and results of delayed employment. The study provides students with a more accurate and comprehensive understanding of employment, improves the employment rate, reasonably allocates and manages human resources, and improves the quality of employment in society 8.
To solve the employment problem of graduates in the above study, it is necessary to effectively personalize recommendations for graduates and enterprises. A CF algorithm for constructing a recommendation model is a common method. Li and Wei proposed a personalized recommendation algorithm optimization method based on the personalized recommendation strategy of a user’s historical behavior and interests. The method adopts CF and machine learning algorithms to optimize the recommendation algorithm using user behavior data and an item association matrix. Experiments showed that the algorithm could significantly improve the recommendation performance of cloud-computing platforms 9. However, this method focuses solely on the overall employment rate and does not address individual occupational matching. Iwendi et al. proposed a pointer-based item-to-item CF recommendation method for common sparsity and cold-start problems in recommendation models. This method uses a pointer network model to represent relationships between items as a graph structure and makes recommendations by learning the similarity between items. Experiments demonstrate that the method significantly improves recommendation accuracy and coverage 10. This method focuses on group needs but lacks a quantitative recommendation model, making it difficult to achieve personalized employment matching. Zeng et al. proposed a time-based CF algorithm to address the problems of traditional CF algorithms. The algorithm uses the user’s historical interest data and time information to build a user interest model. Experiments demonstrate that the algorithm has significant advantages in improving the recommendation accuracy and personalization 11. Although this method improves the understanding of the quality of social employment, it does not provide a technical implementation path or limited guidance for micro-level job-seeking behaviors.
Additionally, the LDA topic model can extract feature words, thereby significantly improving the performance of the recommendation system. Chen et al. proposed a hybrid personalized recommendation algorithm to improve the accuracy of recommendation systems. This algorithm uses CF and content-based recommendation methods to provide recommendations. The LDA topic model is used to reduce the dimensionality of high-dimensional user behavioral data and build a matrix of the user’s writing topics to reduce inaccurate recommendations. The results show that the effectiveness and accuracy of this recommendation algorithm are generally better than those of the other recommendation algorithms 12. However, this method relies on dense historical data and fails under cold-start scenarios. Park and Liu proposed an LDA-based topic diversification method for the problem in which traditional recommendation systems cannot satisfy the potential needs of users because of the lack of diversity in each topic, which allows for a more diverse range of recommended items in each topic. Experiments were conducted using the MovieLens dataset, and the results showed that the method could achieve more diverse recommendation results while maintaining recommendation accuracy 13. However, this method relies overly on users’ subjective interests and ignores the constraints of enterprise employment standards.
Hybrid models have also been widely used for system recommendations. Wang and Niu designed a deep learning-based hybrid recommendation model to improve the accuracy of recommendation systems that combine deep neural networks and attention mechanisms to dynamically adjust the weights of users’ short-term interests and long-term preferences. Experiments on the Amazon and Yelp datasets demonstrated that the HR@10 and NDCG@10 indicators improved by approximately 15%–20% compared with the baseline model 14. Liang et al. deployed a variant model of GraphSAGE in an actual Pinterest system and solved the cold-start problem by generating project embeddings using inductive graph learning. Online testing revealed that user engagement increased by approximately 20% 15. Duong et al. combined BERT with knowledge graphs and proposed the KG-BERT model, which enhances item representation through pretrained text and graph structure information. Experiments on the MIND news recommendation dataset revealed that its AUC improved by approximately 3%–5% compared to the baseline model. It can be observed that the effectiveness of the hybrid model is partly attributable to the contributions of the single models 16.
Compared with the macro-employment prediction and intervention strategies of Guo 6, Lin 7, and Yang et al. 8, the proposed CF-LDA directly targets individuals and achieves precise two-way matching between graduates and enterprises. Among single-view methods improved by CF 9,10,11 and LDA topic enhancement 12,13, this model uses \(K\)-means missing value filling and dynamic weighting of CF behavior similarity and LDA-TF-IDF semantic vectors to preserve interaction signals and deeply explore text semantics. Compared with the latest deep hybrid models, deep learning hybrid models 14 have high accuracy but rely on a large number of annotations and have poor interpretability. The GraphSAGE variant 15 can alleviate the cold-start problem. However, it is difficult to balance text semantics. KG-BERT 16 relies on external knowledge graphs and has high engineering complexity. CF-LDA not only solves the cold start in sparse campus recruitment data but also achieves high interpretability, low computational overhead, and real-time online updates without the need for additional annotations or external graphics. In general, CF-LDA has significant advantages.
3. College Employment Recommendation Based on CF-LDA Topic Mixture Recommendation Modeling
This section explains the specific construction methods for the employment recommendation models based on the CF algorithm and LDA topic. It then analyzes the shortcomings of the two, fuses them into a hybrid recommendation model based on CF-LDA, and describes the specific process of the model.
3.1. College Employment Recommendation Based on CF Algorithm
Traditional CF recommendation algorithms primarily rely on college graduates’ interest in employment units as the basis for scoring. Commonly, \(K\)-means clustering is applied to student’s interest in the hobby score calculation, and then a comprehensive score is calculated to identify a neighboring set with higher similarity to the target student. Finally, based on the employment data of previous graduates, target students with high similarities are recommended. However, it only considers students’ own subjective needs and does not pay attention to the employment standards of enterprises. Therefore, this study collects, organizes, and analyzes enterprise recruitment and student delivery data from the recruitment websites of graduates in province A. The specific operational steps are illustrated in Fig. 1.
For the enterprise recruitment data, five types of information are collected: enterprise type, job position, city, recruitment brief, and interview invitation record. For the student data, two types of information are collected: resumes and resume delivery records. The collected information is first preprocessed. The invitation records from enterprises and delivery records of graduates are represented in matrix form, while the recruitment briefs and students’ resumes are represented in text form. Abnormal data in the matrix and text are directly deleted to avoid affecting the final results. Subsequently, the Python-based stuttering segmentation method is used to segment the resume information text and recruitment brief text. On the basis of obtaining text participles, irrelevant information in the text is removed using a deactivation word list. \({\{\begin{matrix} A & B & \dots & N \end{matrix}\}}\) represents the collection of graduates. \({\{\begin{matrix} 1 & 2 & \dots & n \end{matrix}\}}\) represents enterprise recruitment. On this basis, a graduate–enterprise matrix is established. If a resume submission or an interview invitation occurs between the two parties, it is denoted as 1. If a resume submission and an interview invitation occur simultaneously, it is denoted as 2. A part of the enterprise–graduate matrix is shown in Fig. 2.
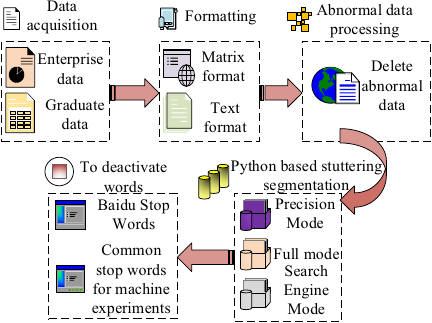
Fig. 1. Flow chart of data information processing.
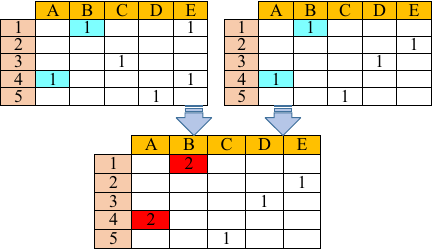
Fig. 2. Enterprise–graduate matrix.
From the overall enterprise–graduate matrix data, enterprise recruitment only occurs for some graduates, and graduates only submit to some enterprises. Therefore, there is no interaction between the majority of graduates and enterprises, and the constructed matrix has strong sparsity, which will affect the subsequent similarity recommendation results. In clustering and analysis, the proportion of “non interactive” records in sparse matrices is relatively large, resulting in high-dimensional and low-density features of the overall data. DBSCAN relies on the density threshold \(\varepsilon\) and MinPts, which can easily classify the vast majority of samples as noise in this context. The feature space dimensions of graduates and enterprises are high, and the value for each dimension varies significantly. The distance matrix calculation complexity of hierarchical clustering is \(O(n^{2})\) and requires repeated merging/splitting of clusters, with time and memory overhead rapidly expanding beyond tens of thousands of samples. However, \(K\)-means has a complexity of only \(O(nkt)\) and can be mini-batch parallel. Therefore, in sparse high-dimensional university employment scenarios that require centroid interpolation and have limited computing resources, \(K\)-means is the clustering scheme that best balances efficiency, scalability, and task fit. Consequently, the \(K\)-means clustering algorithm is used to cluster and analyze the data of graduates and enterprises that do not result in interaction. The initial values of \(K\) object centers \(u_{k}\) are selected. Each data point is categorized into \(\mathit{cluster}\) represented by the closest center to that data point. Subsequently, each new \(\mathit{cluster}\) center point is calculated using Eq. \(\eqref{eq:eq1}\).
In Eq. \(\eqref{eq:eq1}\), \(u_{k}\) is the center point of \(K\), \(j\) is the distance, and \(x_{j}\) is the data point. Next, Eq. \(\eqref{eq:eq1}\) is repeatedly applied to update the center points until the difference between successive \(j\) values is less than a specified threshold. The distance calculation of the \(K\)-means clustering algorithm is defined in Eq. \(\eqref{eq:eq2}\) 17.
In Eq. \(\eqref{eq:eq2}\), \(D\) is the distance between the clustering centers of similar graduates. \(d_{1}\) and \(d_{2}\) are Graduate 1 and Graduate 2, respectively. \(w_{i}\) is the \(i\)-th enterprise. In addition, the predicted scores of graduates and enterprises without interactions are scored and populated to enhance the density of the constructed matrix and improve the accuracy of employment recommendations. The highest similarity \(\mathit{NI}\) is chosen as the neighbor set to calculate the similarity between a target enterprise–graduate and other enterprise–graduates. The similarity \(\mathit{sim}(a, i)\) is calculated as shown in Eq. \(\eqref{eq:eq3}\) 18.
In Eq. \(\eqref{eq:eq3}\), \(\mathit{CSI}_{j}\) is the set of enterprises. \(\bar{R}_{a}\) and \(\bar{R}_{i}\) are the average values of the ratings of \(a\) and \(i\) enterprises by all college graduates of the matrix after \(K\)-means clustering, respectively. \(\mathit{CSI}_{j}(a, i)\) is the subset of users who have ratings in the \(\mathit{CSI}_{j}\) set for \(a\) and \(i\) enterprises. Based on the existing ratings of the project and the rating information of adjacent items of the project, the rating projects that have not yet been executed are predicted. The largest \(N\) items in the predicted value are selected as the set of graduates’ recommended enterprise ratings. The predicted value \(P_{a,k}\) is defined in Eq. \(\eqref{eq:eq4}\).
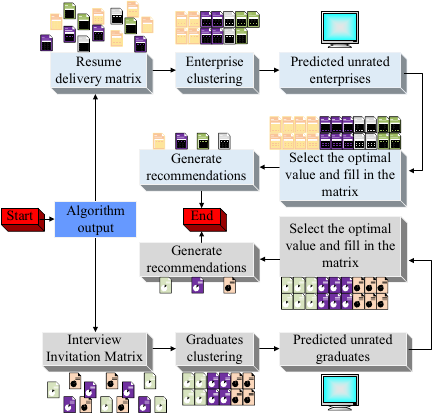
Fig. 3. Total \(K\)-means clustering algorithm run.
In Eq. \(\eqref{eq:eq4}\), \(\mathit{sim}(a, v)\) is the similarity between \(a\) and \(v\). \(R(v, k)\) is the rating of \(v\) to \(k\). \(\bar{R}_{v}\) is the average value of the rating of \(v\) after \(K\)-means clustering. After obtaining the predicted scores of the resume delivery matrix, the scores are entered into the constructed scoring matrix to solve the problem of sparse data in the original matrix, thereby improving the effect of employment recommendations for college graduates. The same steps are taken to construct the invitation matrix for enterprise interviews. The operational steps of the total \(K\)-means clustering algorithm are illustrated in Fig. 3.
The correlation between graduates can be determined by calculating the correlation coefficient of the submitted resumes, as defined in Eq. \(\eqref{eq:eq5}\) 19.
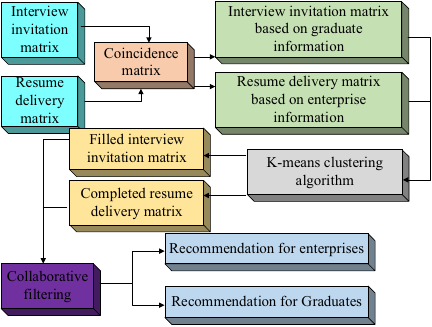
Fig. 4. Employment recommendation process based on collaborative filtering algorithm.
In Eq. \(\eqref{eq:eq5}\), \(r(X, Y)\) is the similarity coefficient of the two graduates of \(X\) and \(Y\). \(\mathit{Con}(X, Y)\) is the covariance of the students’ scores. \(D[X]\) and \(D[Y]\) are the variances of the students’ scores. Based on the calculation results, graduates with higher similarity are filtered for employment recommendations, and the recommendation order is sorted according to the similarity size of the students. The same approach is used to calculate the correlation coefficient of the interview invitations. The process of realizing employment recommendations for college graduates based on the collaborative algorithm is illustrated in Fig. 4.
As shown in Fig. 4, the employment recommendation process is based on a CF algorithm. First, the system collects and preprocesses basic information of enterprises and graduates, resume submission records, and interview invitation records, and then constructs a data matrix. Subsequently, through comprehensive analysis and dual clustering methods, the system improves the accuracy and effectiveness of the recommendations. Finally, based on the CF algorithm, the system provides personalized employment recommendations for graduates and helps companies screen the most suitable candidates. This method provides personalized recommendation services based on the personal situations and job-seeking intentions of graduates, thereby meeting the needs of different users. Clustering and CF algorithms can quickly process large amounts of data, update recommendation results in real time, and ensure the timeliness of the matching information. To alleviate the cold-start problem, for new graduates or enterprises without historical interactions, the system first uses \(K\)-means to cluster resume/recruitment texts, assigning the average rating or invitation probability of existing users in the same category to new nodes, and filling in the missing values in the interaction matrix. Simultaneously, LDA-TF-IDF instantly parses text topics, generates computable semantic vectors, and completes the first round of recommendations based on content similarity, even in the absence of behavioral data.
3.2. Recommendation of College Employment Based on the LDA-Topic Model
For graduates, the feature words are mainly the results of LDA modeling based on resumes and the records of resume submission, while for enterprises, the feature words mainly include the job positions, cities involved, labels of job briefs, and text of job briefs after LDA modeling. A CF method is used to process the records of graduates’ resume deliveries and enterprises’ interview invitations. When constructing the graduate spatial vector model, the feature spatial dimension is first determined, and subsequently, the graduate topic feature vector is constructed. This method adopts the TF-IDF algorithm for feature algorithm extraction, and the calculation method for the TF value is shown in Eq. \(\eqref{eq:eq6}\) 20.
In Eq. \(\eqref{eq:eq7}\), \(|D|\) is the total number of resumes in the data, \(t_{i} \in d_{j}\) is the number of documents containing a feature word, and \(j\) is the number of documents. Eqs. \(\eqref{eq:eq6}\) and \(\eqref{eq:eq7}\) can be multiplied to obtain the weight of the feature word \(w\), from which the vector space model of graduates in Eq. \(\eqref{eq:eq8}\) can be obtained.
In Eq. \(\eqref{eq:eq8}\), \(t_{n}\) is the \(n\)-th feature word of the model, \(w_{n}\) is the weight of the feature word, and \(n\) is the length of the model space. The construction process of the graduate-enterprise feature vector space model can be deduced from the construction process of the graduate space vector, as shown in Fig. 5.
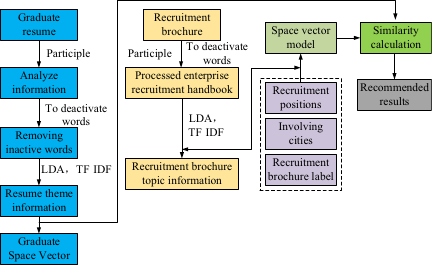
Fig. 5. Vector space model of graduate–enterprise characteristics.
Unlike the resume information of graduates, the information data on corporate recruitment are relatively large. It was divided into two main categories: recruitment brief text information and other recruitment text information, including job positions and cities of employment. The text processing process of the enterprise recruitment brief is word separation \(\to\) deactivation word filtering \(\to\) LDA model to extract the main word \(\to\) TF-IDF algorithm to determine the weight of the main word. While the words of other recruitment text information, such as recruitment position and employment city, are generally few and concise, word frequency is directly used to calculate the weight of the text feature words, as defined in Eq. \(\eqref{eq:eq9}\).
In Eq. \(\eqref{eq:eq9}\), \(w_{i}\) is the weight of the word at \(i\), \(n_{i}\) is the word frequency of the word at \(i\), and \(N\) is the total number of words. Combining the text information model of the recruitment brief and other recruitment text information models can generate the vector space model of the enterprise, as shown in Eq. \(\eqref{eq:eq10}\).
In Eq. \(\eqref{eq:eq10}\), \(E_{i}\) is the feature model of the \(i\) enterprise, \(M_{1}\) and \(M_{2}\) are the spatial vector models of the text information of recruitment brief and other recruitment text information, respectively, \(t_{1l}\) is the \(l\)-th feature word of the model, \(w_{1l}\) is the weight of the feature word, \(t_{2m}\) is the \(m\)-th feature word of the model, \(w_{2m}\) is the weight of the feature word, and \(l\) and \(m\) are the spatial lengths of the model. The similarity of the graduate–enterprise model is calculated using Eq. \(\eqref{eq:eq11}\).
In Eq. \(\eqref{eq:eq11}\), \(\mathit{sim}(D, E)\) is the similarity between the graduate and enterprise feature model. \(\mathit{sim}(D, L)\) is the similarity between the graduate and text features of the job brief. \(\mathit{sim}(D, M)\) is the similarity between the graduate and other vector features of the enterprise’s job information. \(a\) and \(b\) are the weights of these similarities, where, according to experience, the set values are 0.5. By constructing the vector space model of the enterprise and then calculating the similarity of the graduate-enterprise model, the best match between graduates and enterprises can be derived, thereby realizing the final recommendation.
The specific steps of college employment recommendation based on the LDA topic model are as follows: LDA extracts implicit themes from resumes and recruitment brochures to obtain the “theme word” distribution for each text. However, the importance of each topic word is still roughly estimated by the probability given by LDA. TF-IDF measures the discrimination of “words” in the entire corpus again within this topic space, lowering the weight of common but indistinguishable topic words and raising the weight of rare but representative topic words. Using TF-IDF to perform secondary weighting on LDA topic words, the vector model retains the semantic induction advantage of LDA while obtaining the statistical significance filtering of TF-IDF, making the final vector more accurate and less noisy when calculating graduate enterprise similarity. Subsequently, vector space models for graduates and enterprises are constructed, transforming textual information into computable mathematical structures and laying the foundation for similarity calculations. Finally, a bidirectional recommendation is achieved by calculating the similarity of the vector space model. This method extracts topic keywords from the text, making the recommendation results more consistent with the actual needs of the users. By calculating the similarity between graduates and enterprise models, the system can achieve bidirectional recommendations, not only providing suitable job recommendations for graduates but also recommending talents that meet the needs of the enterprise.
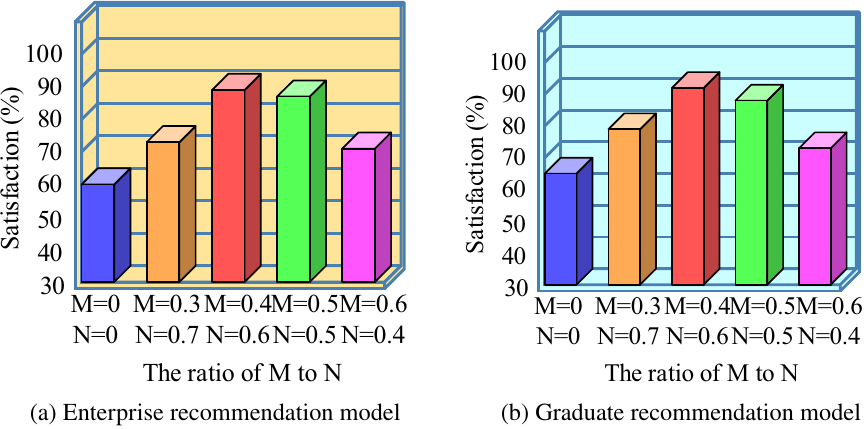
Fig. 6. Comparison results of satisfaction of different coefficient recommendation models.
3.3. College Employment Recommendation Based on CF-LDA Topic Model Algorithm
In Section 3.1, the CF algorithm is used to process the resume submissions of graduates and the interview invitation records of enterprises, thus realizing a two-way recommendation between graduates and enterprises. In Section 3.2, using the text information of graduates’ resumes and enterprises’ recruitment text information, the two-way recommendation between graduates and enterprises is realized by combining the mining of topic words and the establishment of spatial vectors through the LDA model. However, the employment recommendation model based on the CF algorithm considers only historical information and cannot effectively extract and analyze textual information. Employment recommendation models based on the LDA model only consider basic text information and cannot cater to the interests and hobbies of users. Therefore, a hybrid model was developed to combine the two models. The constructed hybrid model can comprehensively consider text information and user interests, thereby improving the accuracy and personalization of employment recommendations. For the final results based on the CF-LDA hybrid employment recommendation model, it is necessary to comprehensively consider the CF algorithm recommendation model, as well as the calculation results of the LDA topic recommendation model, and determine the final recommendation coefficients according to the actual situation, as defined in Eq. \(\eqref{eq:eq12}\).
In Eq. \(\eqref{eq:eq12}\), \(T\) is the final recommendation system of the hybrid model. \(R_{e}\) is the relevance. \(M\) is the weight of relevance. \(\mathit{sim}\) is the similarity. \(N\) is the weight of similarity. The values of \(M\) and \(N\) are constantly adjusted to observe the changes in the satisfaction of graduates and enterprises. To evaluate the hybrid model, the accuracy, recall, and F-value are selected as indicators. This study adopts a linear weighting method to achieve the fusion of the two models, which is simple, intuitive, and easy to understand and implement. It does not require complex algorithms or additional computing resources, which is particularly advantageous for application scenarios with limited resources or those requiring rapid deployment. By adjusting weights \(M\) and \(N\), the influence of the different models on the final recommendation can be flexibly controlled. The accuracy rate is given by Eq. \(\eqref{eq:eq13}\) 21,22:
In Eq. \(\eqref{eq:eq13}\), \(\mathit{ME}\) is the set of recommendations selected by the algorithm, and \(\mathit{HE}\) is the set of recommendations selected manually. The recall is defined in Eq. \(\eqref{eq:eq14}\).
The F-value is defined in Eq. \(\eqref{eq:eq15}\).
The F-value can directly determine the performance of the recommendation model. The higher the F-value, the higher the recommendation quality of the model.
4. Recommendation Model Effect Evaluation
In this section, the parameters of the CF-LDA hybrid recommendation are first calculated, and the validity of the constructed recommendation model is verified using a PR curve test. Subsequently, the recommendation model is applied to a real employment recommendation scenario, and user activity, increase in new users, changes in the number of resume submissions and interview invitations, and the overlap rate between resume submissions and interview invitations are tested to assess the recommendation effect of the hybrid recommendation model.
4.1. CF-LDA Hybrid Recommendation Model Coefficient Determination and Validity Test
To evaluate the effectiveness of the employment recommendations of the constructed model, the values of \(M\) and \(N\) in the CF-LDA hybrid model were determined experimentally. Taking the summer recruitment of a university in 2022 as an example, 500 recruiting enterprises and 200 graduate users were evaluated using a questionnaire survey. The values of \(M\) and \(N\) were determined using the satisfaction scores of the enterprises and graduates based on the recommendation results before and after using the CF-LDA mixed model. The satisfaction surveys included both long- and short-term aspects. Short-term satisfaction mainly measures users’ immediate feelings and evaluations when they first encounter the recommendation results. Long-term satisfaction measures the overall evaluation of a recommendation model during a user’s continuous use and after its actual impact on the final job/recruitment results. The results are presented in Fig. 6.
Figure 6(a) shows the results of the enterprise satisfaction survey with the recommendation results of the hybrid recommendation model under different weight coefficients. As the value of \(M\) increases and that of \(N\) decreases, the satisfaction of enterprises with the recommendation model increases and then decreases. When the coefficients of the hybrid recommendation model are \(M=0.3\), \(N=0.7\); \(M=0.4\), \(N=0.6\); \(M=0.5\), \(N=0.5\); and \(M=0.6\), \(N=0.4\), the enterprise satisfaction with the recommendation results are 73%, 89%, 86%, and 71%, respectively. From this, it can be determined that the optimal weight coefficients of the model are between those of \(M=0.4\), \(N=0.6\) and \(M=0.5\), \(N=0.5\). Fig. 6(b) shows the survey results for graduate satisfaction with the recommendation results of the hybrid recommendation model under different weighting factors. There is not much difference from the survey results of enterprises, and it can also be determined that the optimal weighting coefficients of the model are between \(M=0.4\), \(N=0.6\) and \(M=0.5\), \(N=0.5\). Therefore, \(M=0.45\), \(N=0.55\) was selected as the weighting system for the CF-LDA hybrid model, and subsequent experiments were conducted based on this criterion. In addition, \(M=0\), \(N=0\) is the result of the employment recommendation survey without using the hybrid model, and it can be observed that both enterprises and graduates were less satisfied with the results of the survey than with the results of the employment recommendation survey using the hybrid model. This is because the hybrid model fully considers the needs of graduates and enterprises and uses TF-IDF to extract the most critical information for integrated analysis, thereby recommending the most suitable results for both enterprises and graduates. To further verify its effectiveness, the recommendation effect of the CF-LDA hybrid recommendation model was compared with that of the recommendation models based on CF and LDA and the traditional recommendation model, and the results are shown in Fig. 7.
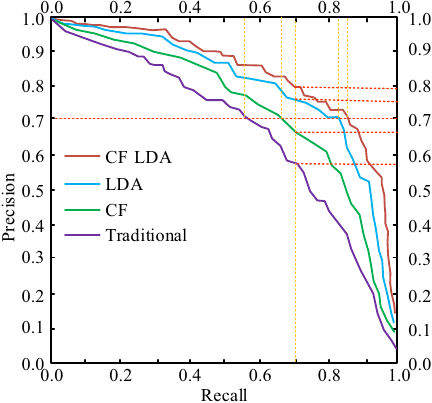
Fig. 7. PR curves for the four recommendation models.
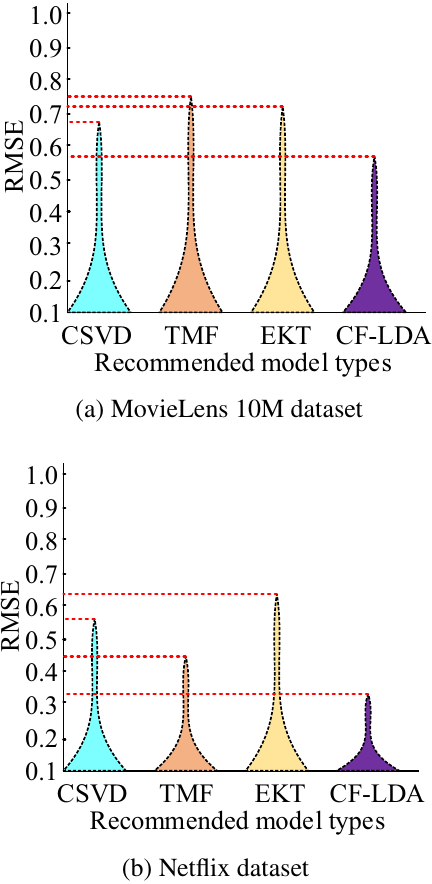
Fig. 8. RMSE values of different recommendation models.
As shown in Fig. 7, with an accuracy rate of 0.7 as the benchmark, the CF-LDA hybrid recommendation model had the highest recall (0.85) because CF can be recommended based on the behavior and preferences of both the enterprise and graduates. The LDA model can mine thematic features hidden in the resume and recruitment information. The CF-LDA hybrid recommendation model effectively combines the advantages of both, improving the recall rate of recommendation results. The LDA-based recommendation model had a slightly lower recall (0.67), which may be attributed to the fact that LDA focuses mainly on the textual body and is unable to effectively focus on the personalized needs of enterprises and graduates. The CF-based recommendation model had a recall of 0.83, which was lower than the CF-LDA hybrid model, probably because CF relies on historical behavioral data, and it is unable to timely and accurately extract key information from resumes and recruitment information to obtain the latest needs of enterprises and graduates. The traditional recommendation model had the lowest recall (0.57) because of the lack of an effective personalized recommendation mechanism. When 0.7 was used as the criterion, the CF-LDA hybrid recommendation model had the highest accuracy (0.79), which is remarkable. The LDA-based recommendation model and CF-based recommendation model had accuracies of 0.76 and 0.67, respectively, reflecting the shortcomings of their respective recommendation strategies, and the traditional recommendation model had the lowest accuracy (0.58) because it cannot accurately capture personalized demands. To verify the superiority and universality of the CF-LDA hybrid model, the CSVD, TMF, and EKT models were selected as baseline models and compared with the CF-LDA hybrid model. The CSVD model captures the potential relationships between users and items through matrix decomposition, the TMF model introduces time factors to adapt to changes in user interests, and the EKT model uses knowledge graphs to improve the accuracy and diversity of recommendations. They represent mainstream recommendation techniques, such as matrix factorization, time perception, and knowledge augmentation. To test these four models on two publicly available datasets, MovieLens 10M and Netflix, the internal training set adopted five-fold cross validation, randomly and uniformly dividing the training set into five parts, taking turns using four parts as sub-training sets to fit the model, and using the remaining part as the validation set for model performance.
The results are shown in Fig. 8.
In Fig. 8, MovieLens 10M is the movie rating dataset, and Netflix is the streaming viewing dataset. Both are universal recommendation datasets. Although they do not come directly from the recruitment field, their underlying data structures are fundamentally isomorphic for employment matching. The rating behavior of users toward movies is analogous to the willingness of graduates to submit to companies, whereas the duration of user viewing is analogous to that of companies’ browsing resumes. The type, director, and actor labels of the movie are parsed into “topic vectors” through LDA, which have the same distributed representation meaning as the job, skill, and industry topic vectors in the recruitment brochure. In addition, newly released movies can be compared to emerging startup companies (without campus recruitment history), and newly registered users can be compared to first-time job-seeking graduates. Therefore, these two datasets were used to test the recruitment and employment recommendation models. As shown in Fig. 8(a), during the testing on the MovieLens 10M dataset, the RMSE values of the CSVD, TMF, EKT, and CF-LDA hybrid models were 0.69, 0.75, 0.72, and 0.58, respectively. The CF-LDA hybrid model had the lowest RMSE value because it combines the advantages of CF and LDA methods. The CF method makes recommendations by analyzing the interaction behavior between graduates and companies, whereas the LDA method can mine potential topic information from the text data of resumes and recruitment information. Therefore, the CF-LDA hybrid model can more comprehensively consider user behavior data and text information, improve the accuracy and personalization of recommendations, and thus improve the testing performance on the MovieLens 10M dataset. According to Fig. 8(b), for the Netflix dataset, the RMSE value of the CF-LDA hybrid model was still the lowest at 0.32. This indicates that the CF-LDA hybrid model has a good generalization ability. The processing speeds of the four models on the MovieLens 10M dataset are shown in Fig. 9.
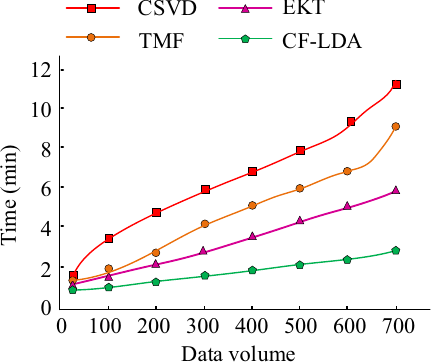
Fig. 9. Results of data processing by different models.
As shown in Fig. 9, as the amount of data to be processed gradually increased, the four models required increasing amounts of time. The difference is that the CF-LDA hybrid model had a slower growth rate in time and took only 2.3 min to process 700 data samples. The other models took much longer than the CF-LDA hybrid model. This indicates that the CF-LDA hybrid model exhibits good performance and efficiency in processing large amounts of data.
In addition, to verify the universality of the CF-LDA recommendation model, the CSVD, TMF, EKT, and CF-LDA models were tested on the balanced dataset, the UCI Company Recruitment Dataset, and the unbalanced dataset, Unbalanced Datasets in Recruitment. The internal training set adopted five-fold cross-validation, randomly and uniformly dividing the training set into five parts, taking turns using four parts as sub-training sets to fit the model, and using the remaining part as the validation set for model performance. The results are summarized in Table 1.
Table 1. Comparison of four recommendation models in different types of datasets.

From Table 1, in the balanced dataset, the CSVD, TMF, EKT, and CF-LDA models exhibited good performance. However, in the imbalanced dataset, the recall rates of the CF-LDA model were 0.16, 0.18, and 0.14, which were higher than those of the CSVD, TMF, and EKT models, respectively, and these differences were statistically significant (\(t=8.13\), \(p<0.001\); \(t=9.45\), \(p<0.001\); and \(t=7.26\), \(p<0.001\)). The accuracy rates were 0.11, 0.18, and 0.19 higher, respectively, with statistical significance (\(t=5.92\), \(p<0.001\); \(t=8.74\), \(p<0.001\); and \(t=9.01\), \(p<0.001\), respectively). The root mean square error decreased by 0.43, 0.40, and 0.46, respectively, and these differences were statistically significant (\(t=15.27\), \(p<0.001\); \(t=13.85\), \(p<0.001\); and \(t=16.93\), \(p<0.001\)). These results indicate that the CF-LDA model has better stability and robustness than the other three recommendation models (CSVD, TMF, and EKT), particularly when dealing with imbalanced data, and can effectively maintain the stability and accuracy of the recommendation performance.
4.2. Effect of Practical Application of Recommendation Model
The study selected 800 graduates who had just signed up for the recommendation service system as experimental topics. The selected graduates had similar age, education, and delivery records. A controlled experiment was conducted to collect data on their job searches from June 11 to June 30 by dividing the 800 new users into four groups, with graduates in the three experimental groups using different recommendation algorithms and graduates in the control group taking no action. Similarly, 200 companies were selected and divided into four groups to collect their interview invitation data from June 11 to June 30, which served as the database for evaluating the combined effect of the recommendation model. First, the web activity of the recruitment system was measured because the recommendation model can provide relatively effective information. The activity of users was also relatively high, as measured by the average online duration of users. The results are presented in Fig. 10.
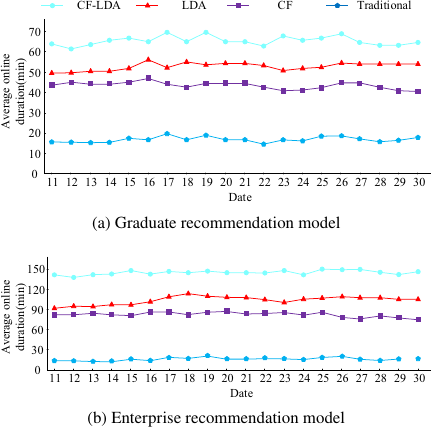
Fig. 10. Test results of user activity of different models.
Figure 10(a) shows the results of the activity test of graduate users under different recommendation models. The CF-LDA hybrid recommendation model had the highest user activity, with an average of 65 min online per person per day. The CF recommendation model and the LDA topic recommendation model had the second-highest activity, with an average of about 43 min and 52 min online per person per day, respectively. Finally, the traditional recommendation model had the lowest activity, with an average of 19 min online per person per day. Fig. 10(b) shows the test results of enterprise users’ activeness under different recommendation models. The average daily online duration per person for CF-LDA hybrid recommendation, CF recommendation, LDA topic recommendation, and traditional recommendation model were approximately 141, 84, 96, and 12 min, respectively, which indicates that the recommendations provided by the CF-LDA hybrid recommendation model are more valuable. Next, the increase in the number of new users during this period was tested, as shown in Fig. 11.
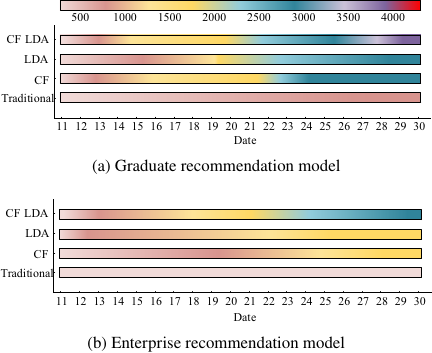
Fig. 11. Results of new user increase detection.
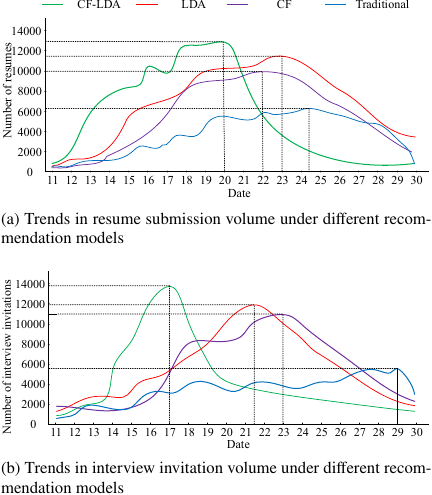
Fig. 12. Trends in resume submission and interview invitation under different recommendation models.
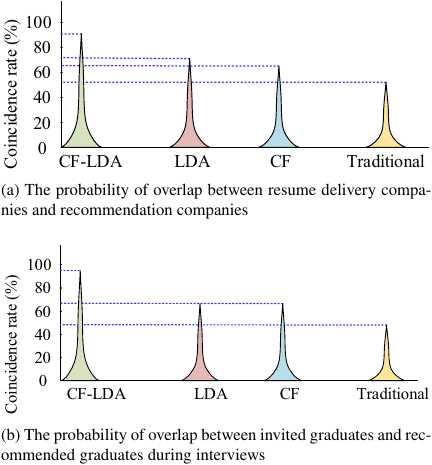
Fig. 13. Overlap rate between resume submission by graduates and invitation by enterprises.
As shown in Fig. 11, the number of new users for the recommendation model changed over time. For the number of graduates, the CF-LDA hybrid recommendation model grew from the initial 200 to nearly 4,000 people, and the growth rate increased. The CF recommendation model and LDA topic recommendation model grew to nearly 2,500 people. The traditional recommendation model grew the least, with approximately 400 people. Regarding the number of companies, the CF-LDA hybrid recommendation model increased from an initial 50 to nearly 2,500. The CF recommendation model and LDA topic recommendation model grew to nearly 1,500. The traditional recommendation model grew the least, barely at all. The rapid growth in the number of new users indicates that the CF-LDA hybrid recommendation model can provide more accurate and effective information. The changes in the number of graduates’ CV submissions and the number of interview invitations from companies were tested. The results are shown in Fig. 12.
Figure 12(a) shows the changes in the number of resumes delivered under the four recommendation models. The number of resumes delivered using the CF-LDA hybrid recommendation model rose quickly compared with the other three models and reached a peak on the 20th, with 12,963 resumes delivered, and then fell rapidly. The rapid increase in the number of CV submissions was partly due to the model’s ability to provide more effective information and partly due to the large increase in new users. The rapid decline was due to graduates finding suitable jobs after resume delivery. Fig. 12(b) shows the number of interview invitations from the CF-LDA using the hybrid recommendation model rose quickly compared to the other three models, reached a peak on the 17th, with 13,465 interview invitations, and then fell rapidly. This indicates that, after the invitation, the company successfully recruited suitable graduates. This shows that CF-LDA has a good employment recommendation effect when using a hybrid recommendation model. Finally, the overlap rate of graduates’ resume deliveries and enterprise invitations was tested, as shown in Fig. 13.
Table 2. Statistical results of long-term evaluation indicators for the model.

Figure 13(a) shows the test results of the overlap rate between the resume delivery of college graduates and the model recommending enterprises. The overlap rates of the CF-LDA hybrid recommendation, LDA topic recommendation, CF recommendation, and traditional models were approximately 92%, 72%, 64%, and 53%, respectively. Fig. 13(b) shows the test results of the overlap rate between the interview invitation of the enterprise and the model-recommended graduates. The overlap rates of CF-LDA hybrid recommendation, LDA topic recommendation, CF recommendation, and traditional models were approximately 96%, 65%, 65%, and 49%, respectively. This indicates that the CF-LDA hybrid recommendation model provided the best employment recommendations.
This study validated the significant advantages of the CF-LDA hybrid recommendation model in short-term behavioral indicators through a 20-day experiment. However, the short-term experiment could not fully evaluate the recommendation results. Consequently, a six-month long-term follow-up plan was implemented. The statistical results are presented in Table 2.
As evident from Table 2, in terms of employment effectiveness, the employment rate of graduates in the CF-LDA group reached 68.2%, and the filling rate of enterprise positions reached 75.4%, both of which were about twice that of the traditional group (\(p<0.001\)), indicating that the model can more accurately match supply and demand. In terms of job retention rate, the retention rates of graduates in the CF-LDA group at three and six months were 89.1% and 82.4%, respectively. The six-month retention rate of talent introduced by enterprises reached 85.7%, which was significantly higher than that of the traditional group (\(p<0.001\)), indicating that CF-LDA-based recommendations not only improved the employment rate but also enhanced the long-term fit between personnel and positions. In terms of satisfaction and performance, the job satisfaction (4.32 points) and employee satisfaction (4.28 points) of CF-LDA were significantly better than those of the traditional group (\(p<0.001\)), and the performance achievement rate was as high as 86.3%, far exceeding that of the traditional group (62.5%). Overall, the six-month tracking results validated the robust and significant advantages of the CF-LDA model in improving long-term employment quality, reducing turnover risk, and enhancing organizational performance.
5. Conclusion
An effective employment recommendation model can significantly improve the efficiency of graduates’ job search and enterprise recruitment. This study proposes a hybrid CF-LDA recommendation model for a two-way selection between graduates and enterprises. The model fully utilizes the advantages of CF and the topic model, effectively exploits and utilizes the implicit information of graduates and enterprises, and realizes two-way recommendations between graduates and enterprises. The test results showed that the overlap rate between graduates’ resumes and recommended companies was 92%, and that between companies inviting and recommending talent was 96%. Further, user activity significantly increased, with an average daily online duration of 65 min and 141 min for enterprises. The growth rate of new users exceeded that of the benchmark model by 200%, with over 4,000 graduates and 2,000\(+\) enterprises. This validates the potential of the hybrid CF-LDA recommendation model to improve job-matching efficiency and provides technical ideas for mitigating structural contradictions in the job market. However, the CF-LDA recommendation model is a hybrid model with high computational complexity, resulting in a longer computation time when processing large-scale data, which limits the real-time performance and response speed of the recruitment recommendation system. Subsequent research will adopt distributed computing frameworks or perform a dimensionality reduction on the model to achieve a balance between accuracy and complexity. Second, the study did not evaluate whether the model introduced or amplified biases, such as systematically favoring graduates from certain majors or companies with larger job pools. Subsequent research will establish a multidimensional fairness-testing benchmark across a “major college region enterprise scale” using statistical parity and equal opportunity measurement systems to detect and quantify the degree of bias in the exposure, interview invitations, and hiring processes of the model.
- [1] N. Nabulsi, B. Mcnally, and G. Khoury, “Improving graduateness: Addressing the gap between employer needs and graduate employability in Palestine,” Education + Training, Vol.63, No.6, pp. 947-963, 2021. https://doi.org/10.1108/ET-06-2020-0170
- [2] O. Gavrylenko and V. Dvornyk, “Application of clustering methods to determine the areas of activity of candidates in recruitment for IT-companies,” System Technologies, Vol.3, No.134, pp. 126-134, 2021 (in Ukrainian). https://doi.org/10.34185/1562-9945-3-134-2021-14
- [3] F. Wang, Y. Wen, T. Guo, J. Liu, and B. Cao, “Collaborative filtering and association rule mining-based market basket recommendation on spark,” Concurrency and Computation: Practice and Experience, Vol.32, No.7, Article No.e5565, 2020. https://doi.org/10.1002/cpe.5565
- [4] K.-H. Cheng, “Use of real-life imagery and words in luxury brand trademarks: A study of the trademark lawsuits involving the Polo/Lauren Company,” Asia Pacific J. of Marketing and Logistics, Vol.35, No.3, pp. 606-624, 2023. https://doi.org/10.1108/APJML-10-2020-0703
- [5] C. Weisser et al., “Pseudo-document simulation for comparing LDA, GSDMM and GPM topic models on short and sparse text using Twitter data,” Computational Statistics, Vol.38, No.2, pp. 647-674, 2023. https://doi.org/10.1007/s00180-022-01246-z
- [6] A. Guo, “Geometric average weakening buffer GM(1,1) and its application in prediction of employment rate of college graduates,” IEEJ Trans. on Electrical and Electronic Engineering, Vol.17, No.7, pp. 1370-1371, 2022. https://doi.org/10.1002/tee.23627
- [7] Y. Lin, “Understand the particularity of graduates and do a good job in higher vocational employment service,” Psychology Research, Vol.11, No.9, pp. 404-407, 2021. https://doi.org/10.17265/2159-5542/2021.09.004
- [8] J. Yang, F. Ding, J. Sun, and Y. Deng, “Delayed employment among college students in Guangdong – Taking Shenzhen University as an example,” J. of Contemporary Education Research, Vol.6, No.1, pp. 29-33, 2022. https://doi.org/10.26689/jcer.v6i1.2908
- [9] X. Li and L. Wei, “Personalized recommendation strategy and algorithm optimization on cloud computing platform,” Int. J. of Performability Engineering, Vol.14, No.10, pp. 2492-2503, 2018. https://doi.org/10.23940/ijpe.18.10.p25.24922503
- [10] C. Iwendi, E. Ibeke, H. Eggoni, S. Velagala, and G. Srivastava, “Pointer-based item-to-item collaborative filtering recommendation system using a machine learning model,” Int. J. of Information Technology & Decision Making, Vol.21, No.1, pp. 463-484, 2022. https://doi.org/10.1142/S0219622021500619
- [11] J. Zeng, X. He, F. Li, and Y. Wu, “A recommendation algorithm for point of interest using time-based collaborative filtering,” Int. J. of Infomation Technology and Management, Vol.19, No.4, pp. 347-357, 2020. https://doi.org/10.1504/ijitm.2020.110242
- [12] S. Chen, L. Huang, Z. Lei, and S. Wang, “Research on personalized recommendation hybrid algorithm for interactive experience equipment,” Computational Intelligence, Vol.36, No.3, pp. 1348-1373, 2020. https://doi.org/10.1111/coin.12375
- [13] S.-T. Park and C. Liu, “A study on topic models using LDA and Word2Vec in travel route recommendation: Focus on convergence travel and tours reviews,” Personal and Ubiquitous Computing, Vol.26, No.2, pp. 429-425, 2022. https://doi.org/10.1007/s00779-020-01476-2
- [14] S. Wang and L. Niu, “A deep reinforcement learning recommendation model based on long and short term interest,” Computer Science and Application, Vol.13, No.5, pp. 1037-1043, 2023 (in Chinese). https://doi.org/10.12677/CSA.2023.135101
- [15] X. Liang et al., “Hybrid Gaussian network intrusion detection method based on CGAN and E-GraphSAGE,” Instrumentation, Vol.11, No.2, pp. 24-35, 2024. https://doi.org/10.15878/j.instr.202400165
- [16] H. T. Duong, V. H. Ho, and P. Do, “Fact-checking Vietnamese information using Knowledge Graph, Datalog, and KG-BERT,” ACM Trans. on Asian and Low-Resource Language Information Processing, Vol.22, No.10, Article No.240, 2023. https://doi.org/10.1145/3624557
- [17] N. Kumari and P. Singh, “Automated Hindi text summarization using TF-IDF and text rank algorithm,” J. of Critical Reviews, Vol.7, No.17, pp. 2547-2555, 2020.
- [18] H. Yu, Y. Ji, and Q. Li, “Student sentiment classification model based on GRU neural network and TF-IDF algorithm,” J. of Intelligent & Fuzzy Systems: Applications in Engineering and Technology, Vol.40, No.2, pp. 2301-2311, 2021. https://doi.org/10.3233/JIFS-189227
- [19] R. B. Salem, E. Aimeur, and H. Hage, “A multi-party agent for privacy preference elicitation,” Artificial Intelligence and Applications, Vol.1, No.2, pp. 82-89, 2023. https://doi.org/10.47852/bonviewAIA2202514
- [20] Y.-L. Qi et al., “Optimal feature selection based on discrete grasshopper optimization algorithm and K-nearest neighbor classifier,” Engineering Letters, Vol.32, No.1, pp. 89-100, 2024.
- [21] S. R. Bhat, R. Bhat, and S. G. Bhat, “A comprehensive analysis of total and semi-total graphs,” Engineering Letters, Vol.32, No.1, pp. 21-29, 2024.
- [22] M. M. Motheogane and A. B. Pretorius, “Alignment of information technology and strategic business objectives,” Proc. of the Int. MultiConf. of Engineers and Computer Scientists 2021, pp. 55-58, 2021.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.