Research Paper:
DroneDetect: Multiscale Feature Fusion and Attention-Driven Architecture for UAV Object Detection
Huiyao Zhang*,**
*School of IoT Engineering, Wuxi Taihu University
No.68 Qianrong Road, Binhu District, Wuxi, Jiangsu 214064, China
**Provincial Key (Construction) Laboratory of Intelligent Internet of Things Technology and Applications in Universities
No.68 Qianrong Road, Binhu District, Wuxi, Jiangsu 214064, China

Aerial object detection continues to face significant challenges such as complex scene compositions, highly variable object sizes and densities, and diverse imaging perspectives. This study presents DroneDetect, a series of progressively enhanced models specifically designed to address these challenges in aerial detection tasks. To address the complexity of aerial scenes and enable effective semantic information extraction, we propose an efficient up-convolution block with a multi-branch auxiliary feature pyramid network that enhances the multiscale feature fusion capabilities. Building on this foundation, we address the critical need for precise spatial localization by introducing a Cross-Stage Receptive Field Attention module that integrates CSPNet with an improved receptive field attention convolution, enabling dynamic spatial attention mechanisms to capture fine-grained positional information. To ensure practical deployment efficiency while maintaining detection accuracy, we developed a lightweight shared detail-enhanced convolution detection head that optimizes parameter utilization and reduces the computational overhead. Extensive experiments on multiple aerial datasets demonstrate the effectiveness of the proposed approach. On VisDrone, DroneDetect-Enhanced achieved an AP of 24.05%, representing a significant improvement of 2.39% over the baseline YOLOv8s on the validation sets. The cross-validation results further validate the generalizability of our model, with performance gains of 3.9% on UAVDT, 3.0% on CARPK, and 1.5% on DIOR. Notably, DroneDetect-Enhanced maintains comparable or reduced computational complexity while using fewer parameters than the baseline. Comprehensive ablation studies and comparative analyses with state-of-the-art methods confirm that our approach effectively balances the accuracy and efficiency of real-world aerial object detection applications. This code is available at https://github.com/aerialCV/DroneDetect.
1. Introduction

Fig. 1. Examples of complex scene compositions and variable object characteristics in aerial object detection datasets.
Object detection in aerial imagery has emerged as a critical capability in diverse applications ranging from urban planning and traffic management to environmental monitoring and emergency responses. Despite significant advances in general object detection frameworks like You Only Look Once (YOLO) 1,2, aerial imagery presents unique challenges that conventional models struggle to address effectively. These challenges include complex scene compositions, highly variable object sizes and densities, and diverse imaging perspectives 3, which are particularly evident in drone-captured images (Fig. 1).
Complex scene compositions in aerial imagery arise from the intricate arrangement of objects within heterogeneous environments, where multiple object categories coexist in cluttered backgrounds with varying contextual relationships. As shown in Fig. 1, the VisDrone coastal scene presents a complex composition with boats scattered across water surfaces alongside the coastal infrastructure, whereas the DIOR harbor view showcases the intricate arrangements of maritime vessels amid port facilities.
Highly variable object sizes and densities present challenging problems in aerial detection. Object size variability occurs because of the different altitudes of aerial platforms and inherent physical size differences within object categories. The UAVDT dataset exemplifies this challenge, showing that cars appear at dramatically different scales depending on their distance from the camera. Meanwhile, density variations manifest as extremely uneven distributions of objects throughout the image space, with certain regions containing densely clustered objects, whereas others remain sparse, as is evident from the concentrated vehicle arrangements along the highway.
Diverse imaging perspectives further compound these challenges, as aerial platforms capture scenes from varying angles, altitudes, and orientations, resulting in significant perspective distortions and appearance variations for the same object categories. These changes alter object aspect ratios, introduce occlusions, and create inconsistent visual representations that conventional detection architectures struggle to handle effectively.
These concurrent challenges create complex scenarios in which all the problems coexist, as demonstrated in the datasets shown in Fig. 1. Conventional object detection architectures typically underperform under these conditions, resulting in missed detections, inaccurate localizations, and classification errors.
Recent efforts to improve aerial object detection have explored various architectural enhancements including feature pyramid networks (FPNs) 4,5, attention mechanisms 6,7, and specialized detection heads. However, most existing approaches address individual challenges in isolation or incur significant computational overhead, which limits their deployment in resource-constrained aerial platforms. Furthermore, many specialized aerial detection models sacrifice generalizability across different aerial datasets, performing well on one specific domain but failing to transfer effectively to others.
The YOLOv8 8 family of models offers a promising baseline performance for aerial object detection owing to its efficient design and strong feature extraction capabilities. However, its standard configuration remains suboptimal for addressing the unique challenges associated with aerial imagery. The conventional FPN structure in YOLOv8 offers limited multiscale feature fusion capabilities for handling complex scene compositions, and its backbone lacks explicit attention mechanisms for focusing on informative regions among highly variable object distributions. Additionally, the standard detection head does not sufficiently address the fine-grained details that are critical for distinguishing objects from diverse imaging perspectives.
To address these limitations, we propose DroneDetect, a series of progressively enhanced YOLOv8s-based models specifically optimized for aerial object detection. Our design philosophy centers on three critical observations regarding the shortcomings of existing approaches when applied to aerial imagery.
First, the complex scene compositions in aerial imagery require more sophisticated feature fusion mechanisms than those provided by conventional FPN structures. The heterogeneous nature of aerial scenes, in which objects of different categories coexist within cluttered backgrounds, demands enhanced multiscale feature integration that can effectively capture both local details and global contextual relationships. To address this need, we introduce a Multi-Branch Auxiliary FPN (MAFPN) with Efficient Up-Convolution Block FPN (EUCB-FPN) that enhances multiscale feature fusion capabilities through a redesigned neck architecture, effectively handling complex scene compositions by efficiently integrating information across different scales while reducing computational complexity compared to conventional FPN structures.
Second, highly variable object sizes and densities, combined with diverse imaging perspectives, necessitate adaptive attention mechanisms that can dynamically adjust their focus based on the spatial characteristics of different image regions. Standard convolutional operations with fixed receptive fields are insufficient for capturing the fine-grained positional information required across diverse visual contexts. Therefore, we develop a Cross-Stage Receptive Field Attention (CSRFA) convolution module that integrates CSPNet with receptive-field attention convolution to enable dynamic spatial attention mechanisms that adapt to highly variable object sizes and densities while capturing fine-grained positional information across diverse imaging perspectives.
Third, the computational constraints of aerial platforms require detection heads that maintain high accuracy while optimizing resource utilization. Conventional detection heads often require extensive parameters to manage the complexity of aerial scenes, rendering them unsuitable for deployment in resource-constrained drones. To balance detection performance with computational efficiency, we propose a Lightweight Shared Detail-Enhanced Convolution Detection Head (LSDECD) that optimizes parameter utilization and reduces computational overhead while maintaining detection accuracy across varying scene compositions and object characteristics through detail-enhanced convolutions with shared parameters.
The remainder of this paper is organized as follows. Section 2 reviews related work on object detection with an emphasis on YOLO architectures, feature fusion mechanisms, attention-driven CNN designs, and detection head evolution. Section 3 details the methodology and elaborates on each proposed architectural enhancement method. Section 4 describes our experimental setup, including the datasets, equipment, and evaluation metrics. Section 5 presents the results, including those of the ablation studies and cross-dataset validation. Finally, Section 6 provides a full discussion of the findings, comparisons with state-of-the-art methods, an analysis of model complexity, and qualitative insights.
2. Related Work
2.1. YOLO Architecture Evolution
The YOLO family has evolved significantly since its introduction by Redmon et al. 1, establishing itself as a leading real-time object detection framework. The architecture’s three-component design, backbone, neck, and head, provides flexibility for various applications, though aerial object detection presents unique challenges becasue of scale variations and perspective distortions.
The key evolutionary milestones include YOLOv3’s 9 introduction of multiscale predictions, YOLOv4’s 10 ImageNet-pretrained backbone, and YOLOv8’s 8 state-of-the-art architecture to balance speed and accuracy. Recent versions of YOLOv9 11 and YOLOv10 12 have incorporated advanced gradient information processing and enhanced CSPNet structures. YOLOv8 serves as an optimal baseline becasue of its computational efficiency and robust feature extraction capabilities.
2.2. Feature Fusion Networks
Feature fusion in object detection has progressed from simple concatenation to sophisticated multiscale integration mechanisms. The seminal FPN 4 establishes top-down pathways with lateral connections, which YOLOv3 adapts for three-scale predictions. PANet 13 enhanced this with a bidirectional information flow, whereas BiFPN 14 introduced a weighted fusion with learnable parameters.
Recent innovations have focused on computational efficiency while maintaining rich feature representation. MAF-YOLO’s 5 multi-branch auxiliary FPN creates specialized pathways for different feature stages, whereas Gold-YOLO’s 15 Gather-and-Distribute mechanism optimizes the cross-scale feature contribution. These advances demonstrate the ongoing pursuit of balancing detection performance with real-time constraints.
2.3. Attention Mechanisms
Attention mechanisms have revolutionized CNNs by enabling selective feature processing rather than the uniform treatment of all features. SE blocks 16 pioneered channel attention through global pooling and excitation, thereby achieving remarkable performance gains with minimal overhead. CBAM 17 extended this concept by sequentially combining channel and spatial attention, improving ImageNet classification by 1.9% on ResNet-50.
Self-attention mechanisms capture long-range dependencies through position-wise similarity computations. Non-local neural networks have demonstrated the effectiveness of global context modeling in video understanding, whereas recent transformer-CNN hybrids represent the latest evolution in attention-augmented architectures. These mechanisms consistently improve the performance across classification, detection, and segmentation tasks by focusing computational resources on the most informative features.
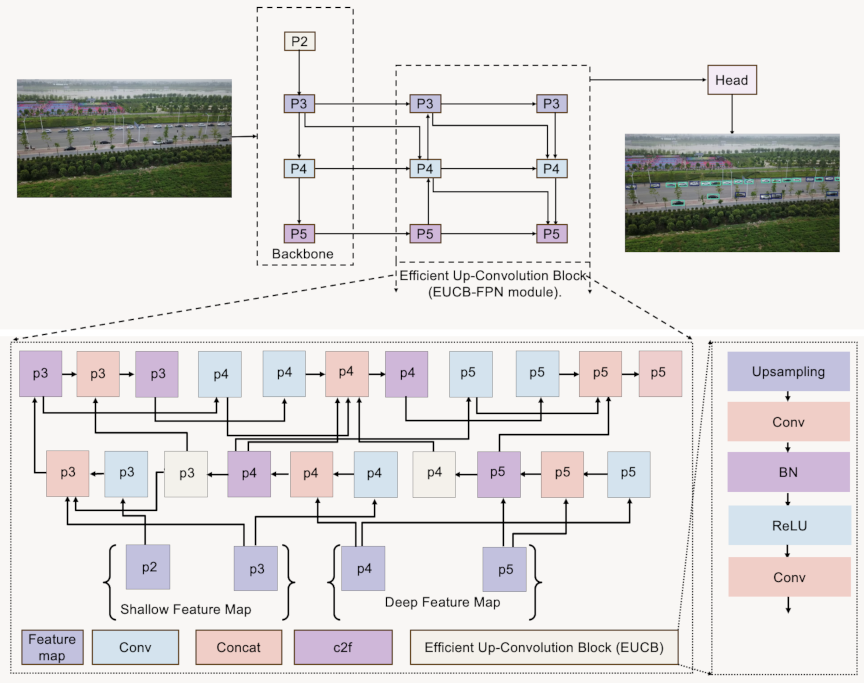
Fig. 2. Detailed architecture of the EUCB-FPN module for enhanced FPN in DroneDetect-Fusion. Shallow features (P2 and P3) contain rich spatial details crucial for small object detection, whereas deep features (P4 and P5) provide semantic representations for classification and localization. P2–P5 represent pyramid levels at \(1/4\), \(1/8\), \(1/16\), and \(1/32\) input resolution, respectively.
2.4. Detection Head Evolution
YOLO detection heads have transformed from simple, fully-connected layers in YOLOv1 to sophisticated multi-branch architectures. Early versions relied on anchor boxes and coupled prediction heads, whereas recent iterations have embraced anchor-free designs with decoupled classification and regression branches.
YOLOv6 18 pioneered the decoupled head approach, separating the classification and localization tasks for improved specialization. YOLOv8 and YOLOv9 further refined this design with anchor-free prediction by directly regressing the bounding boxes relative to the grid positions. YOLOv10’s 12 dual-head strategy employs different assignment mechanisms for training and inference, whereas the recent versions maintain a decoupled approach while integrating attention mechanisms for enhanced feature extraction. This evolution reflects the continuous optimization of accuracy, speed, and deployment efficiency in real-world applications.
3. Methodology
3.1. EUCB-FPN Module
As shown in Fig. 2, the EUCB-FPN represents a novel architecture that integrates the MAFPN 5 with an Efficient Up-Convolution Block (EUCB) 19 to achieve a robust multiscale feature representation. This network improves upon traditional feature pyramid methods by effectively combining shallow features (containing fine spatial details) with deep features (providing semantic understanding). By merging these complementary feature types while preserving the spatial information, the network overcomes the limitations of conventional feature pyramids.
The design begins with the MAFPN component, which uses two specialized fusion modules. The Superficial Assisted Fusion (SAF) module captures and integrates the shallow features from its backbone. It fuses information from three sources: a downsampled version of the preceding feature map, current feature map, and upsampled version of the subsequent feature map. The module employs a \(1 \times 1\) convolution to adjust the channel dimensions and applies a non-linear activation function to enhance the resulting features. This operation is expressed as follows:
The Advanced Assisted Fusion (AAF) module is deployed in deeper layers and further enriches the feature representation. It aggregates multiscale cues by fusing a downsampled version of a previous shallow feature with a downsampled output from a prior advanced layer. In addition, it incorporates the refined output from the SAF and upsampled feature adjusted via a \(1 \times 1\) convolution. The formulation is given as follows:
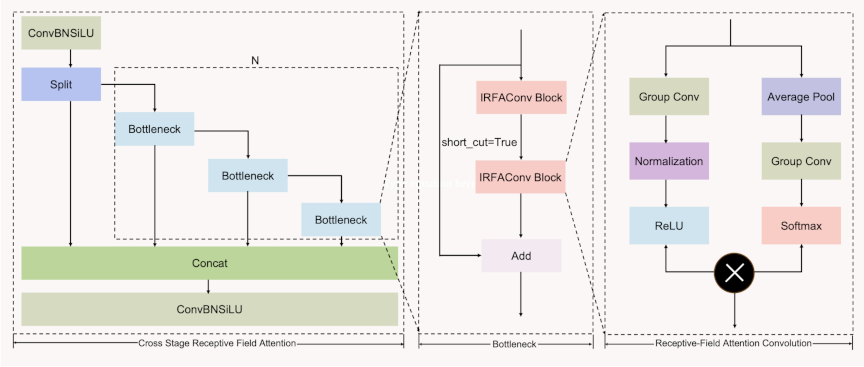
Fig. 3. Architecture of the CSRFA module showing the integration of cross stage partial network with IRFAConv blocks.
By complementing these modules, the EUCB module efficiently upscales the feature maps with minimal computational overhead. Initially, the input feature map was upsampled by a factor of two using interpolation. Next, a \(3 \times 3\) depth-wise convolution (DWC) captures the local spatial relationships by processing each channel independently. Batch normalization (BN) was used to standardize the output, and rectified linear unit (ReLU) activation introduced non-linearity. Finally, a \(1 \times 1\) convolution is used to adjust the channel dimensions. The complete procedure is summarized as follows:
In conclusion, the EUCB-FPN seamlessly blends the fusion capabilities of MAFPN with the efficient upsampling of EUCB. Each module maintains a clear role and ensures that shallow details and deep semantics are preserved. This network architecture is ideally suited for tasks that require high localization accuracy and multiscale feature integration.
3.2. Cross Stage Receptive Field Attention Module
As shown in Fig. 3, we propose a CSRFA module based on a Cross Stage Partial Network (CSPNet) 20 and Receptive Field Attention Convolution (RFAConv) 21. RFAConv solves kernel parameter sharing in standard convolution by introducing a receptive field slider that emphasizes the significance of different features and prioritizes the receptive-field spatial feature. This module introduces dynamic receptive fields and attention mechanisms, enabling the model to focus on salient spatial information and improve the feature extraction across varying object scales.
Spatial location information plays a crucial role in addressing the target location problem prevalent in aerial object detection, in which objects of varying scales are distributed unevenly across drone-captured images. Traditional convolution operations suffer from fixed receptive field constraints and kernel parameter sharing limitations, which restrict their ability to adaptively capture multiscale spatial features. These conventional approaches fail to emphasize the significance of different spatial regions and cannot effectively prioritize receptive-field spatial features, leading to suboptimal performance when detecting objects of diverse scales and spatial distributions in complex aerial scenes.
To further enhance the dynamic attention mechanism, we introduce an Improved Receptive Field Attention Convolution (IRFAConv) that incorporates spatial rearrangement to reconstruct refined feature representations. Unlike the conventional RFAConv, IRFAConv explicitly reorganizes attention-modulated features through spatial unfolding before the final convolution. The IRFAConv operation is formulated as follows:
3.3. Lightweight Shared Detail-Enhanced Convolution Detection Head
To further enhance the detection capabilities and efficiency of the proposed DroneDetect model, we introduced a LSDECD, designed explicitly to address the challenges of aerial object detection.
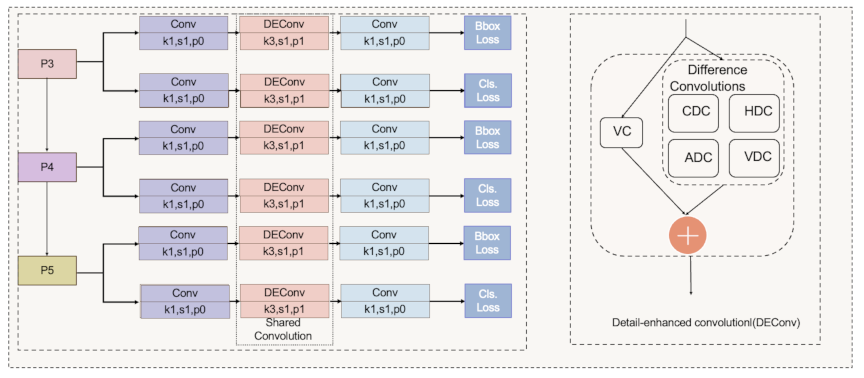
Fig. 4. Architecture of the LSDECD.
The proposed LSDECD module, as shown in Fig. 4, comprises multiple parallel streams originating from three different feature pyramid levels (P3, P4, and P5). Each stream initially passes through a standard convolutional layer (Conv) with a kernel size of \(1 \times 1\), stride of 1, and padding of 0, thereby reducing the channel dimensions and computational complexity.
Subsequently, these features undergo the core component of the LSDECD, the Detail-Enhanced Convolution (DEConv). As shown in Fig. 4, DEConv 22 is specifically designed to emphasize the fine-grained spatial details that are crucial for accurate aerial object localization. DEConv integrates a vanilla convolution (VC) layer with four specialized difference convolutions: central difference convolution (CDC), angular difference convolution (ADC), horizontal difference convolution (HDC), and vertical difference convolution (VDC). These difference convolutions explicitly encode gradient-level spatial information, thereby significantly improving the detection of small closely packed objects that are common in aerial imagery.
Mathematically, the DEConv operation is formulated as follows:
Furthermore, LSDECD employs shared convolutional weights for the DEConv layer across different feature pyramid streams, substantially reducing the parameter count while maintaining detection performance.
Finally, the outputs from DEConv are passed through another convolutional layer (\(1 \times 1\), stride 1, padding 0) to refine the extracted features before branching into task-specific predictions, namely, bounding box (BBox) regression and object classification (Cls). Bounding box regression and classification tasks utilize separate loss functions to enhance feature specialization, significantly improving the model accuracy for diverse object scales.
4. Experiment Settings
4.1. Dataset
This study used four unmanned aerial datasets: VisDrone 23, UAVDT 24, CARPK 25, and DIOR 26. VisDrone supplies images with dense, small targets set against busy backdrops and examines the scale challenges. The UAVDT provides vehicle sequences under fluctuating illumination and weather conditions to probe model resilience. CARPK focuses on high-density parking facilities with frequent occlusions and evaluates spatial resolution. The DIOR comprises multiple object classes across broad aerial shots, covering diverse scales and contexts. In contrast, these datasets gauge the detection accuracy and versatility of the proposed model under realistic conditions.
4.2. Equipment and Parameter Settings
The server features an Intel Xeon Gold 6330 processor. It runs on a 64-bit Linux operating system. The system has 503 GB of memory. An NVIDIA A10 GPU with 24 GB of GDDR6 memory is also integrated. This combination of hardware enables efficient YOLO model training and experimentation using object detection algorithms.
The training process was implemented using PyTorch 2.2 with CUDA 12.1. The model was trained for 300 epochs with a batch size of 16 and an input image size of 640. Stochastic gradient descent (SGD) was selected as the optimizer, with an initial learning rate of 0.01 and a final learning rate of 0.01. The momentum parameter was set to 0.937 and the weight decay was adjusted to 0.0005. Additionally, a warmup strategy was employed for the first 3.0 epochs, incorporating a warmup momentum of 0.8 and a warmup bias learning rate of 0.1.
Table 1. Ablation study: incremental impact of modules on model performance and complexity.

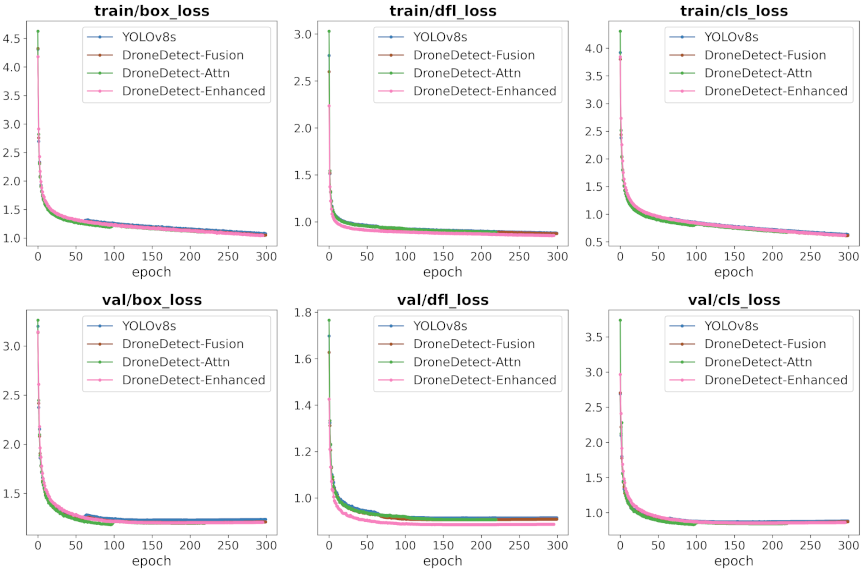
Fig. 5. Training and validation loss curves comparison across model variants. The figure shows box regression loss, distribution focal loss, and classification loss for YOLOv8s baseline and three DroneDetect variants during 300 training epochs on VisDrone dataset.
4.3. Metrics
Object detection performance was evaluated using MS COCO 27 metrics, which provide a comprehensive assessment through true positives (TP), false positives (FP), false negatives (FN), recall, and various average precision measures. These metrics include AP (mean AP for IoUs from 0.50 to 0.95), \(\textrm{AP}_{50}\) and \(\textrm{AP}_{75}\) for specific IoU thresholds, scale-specific metrics \(\textrm{AP}_{s}\), \(\textrm{AP}_{m}\), and \(\textrm{AP}_{l}\) for small (\(\leq 32^2\) pixels), medium (\(32^2\) to \(96^2\) pixels), and large (\(\geq 96^2\) pixels) objects respectively, and average recall (AR) measures \(\textrm{AR}_{1}\), \(\textrm{AR}_{10}\), and \(\textrm{AR}_{100}\) for different detection limits per image. For aerial object detection applications, the scale-specific metrics \(\textrm{AP}_{s}\), \(\textrm{AP}_{m}\), and \(\textrm{AP}_{l}\) are particularly critical because they provide insights into the performance across different object sizes commonly encountered in aerial imagery.
5. Results
5.1. Ablation Study of Progressive Module Enhancement
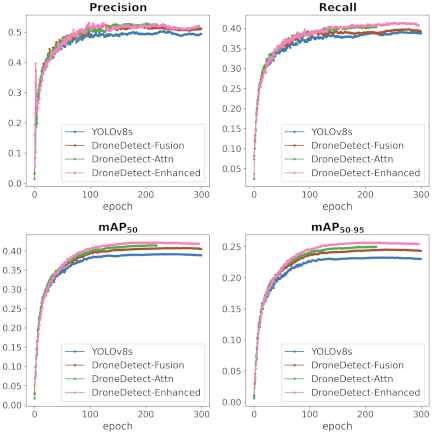
Fig. 6. Performance metrics evolution during training across model variants. Different metric curves demonstrate the progressive improvement achieved by each enhancement module over 300 training epochs on VisDrone dataset.
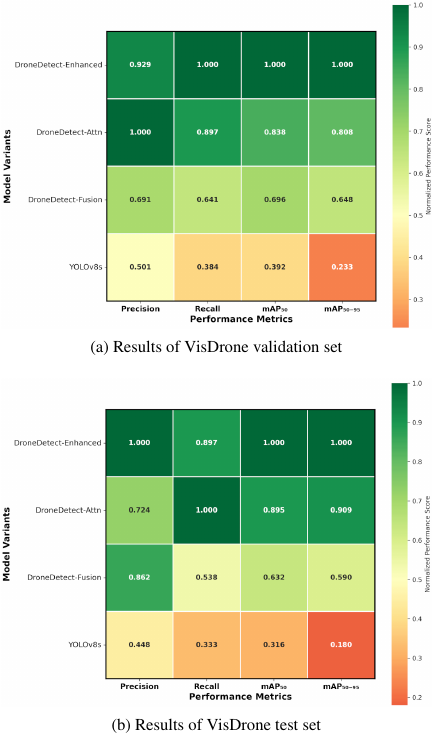
Fig. 7. Performance comparison heatmaps showing normalized scores across four evaluation metrics for different drone detection model variants on the VisDrone dataset. Values are normalized relative to the best-performing model for each metric, with darker green indicating higher performance (normalized score \(=\) 1.0) and orange-red indicating lower performance.
We conducted ablation studies to quantify the performance gains achieved by each proposed module and validate the effectiveness of our progressive enhancement strategy. Our analysis compared the baseline YOLOv8s with three enhanced variants: DroneDetect-Fusion, DroneDetect-Attn, and DroneDetect-Enhanced, as listed in Table 1. All ablation experiments were conducted under identical experimental conditions to ensure a fair comparison with the detailed experimental setup, training parameters, and evaluation protocols described in Section 4.2.
Figure 5 shows the training and validation loss convergence patterns across all model variants, showing the improved optimization stability achieved through our progressive enhancements. The training curves demonstrate that each successive model variant achieved faster convergence and lower final loss values, with DroneDetect-Enhanced exhibiting the most stable training dynamics. Fig. 6 shows the evolution of the key performance metrics during training, where our enhanced models consistently outperformed the baseline YOLOv8s, with DroneDetect-Enhanced achieving the highest precision, recall, and mAP scores.
Figure 7 shows comprehensive performance heatmaps comparing all model variants across key metrics on the VisDrone validation and test sets, effectively addressing the core challenges of aerial object detection, including varying object scales and complex scene understanding. The normalized performance visualization clearly demonstrates a progressive improvement from the baseline YOLOv8s to DroneDetect-Enhanced, with our final model achieving superior performance across all evaluation metrics. DroneDetect-Enhanced showed the most balanced performance profile, particularly in terms of precision and mAP metrics, which are critical for reliable aerial object detection in challenging drone-captured scenarios with dense object distributions and significant scale variations.
5.2. Comparative Analysis of FPN Structures
An effective FPN design is essential for aerial object detection, in which objects span a wide range of scales within complex scenes. To validate our proposed fusion approach, we compared DroneDetect-Fusion with state-of-the-art FPN variants including FDPN 28, GFPN 29, and MAFPAN 5 and demonstrated the advantages of our multiscale feature integration mechanism.
Table 2 lists a comprehensive performance comparison across different FPN structures, demonstrating the superior effectiveness of the proposed drone-detect fusion approach. Our proposed method achieved the highest overall AP of 23.24, representing a 1.58 point improvement over the baseline YOLOv8s. Notably, DroneDetect-Fusion shows consistent improvements across all object scales: \(\textrm{AP}_{s}\) increases from 12.75 to 13.89 (\(+\)1.14), \(\textrm{AP}_{m}\) from 32.50 to 35.02 (\(+\)2.52), and \(\textrm{AP}_{l}\) from 41.86 to 44.16 (\(+\)2.3). This balanced performance enhancement across small, medium, and large objects validated our multiscale feature integration strategy, with particularly significant gains in medium-sized object detection.
The heterogeneous nature of aerial scenes, in which objects of different categories coexist within cluttered backgrounds, demands enhanced multiscale feature integration that can effectively capture both local details and global contextual relationships. Our EUCB-based fusion mechanism addresses this challenge by providing adaptive feature enhancement that preserves fine-grained details while maintaining computational efficiency, thereby enabling more robust detection across the diverse scale variations inherent in drone-captured imagery.
Table 2. Performance comparison of FPN structures in object detection on VisDrone validation split.

Table 3. Comparison of detection errors on validation and test sets.

5.3. Comprehensive Error Analysis
To further understand the improvements introduced by our progressively enhanced DroneDetect models, we performed a detailed toolbox for identifying detection errors (TIDE) 30 analysis. This analysis provides insight into specific error types, including classification (Cls), localization (Loc), combined errors (Both), duplicate detections (Dupe), background false positives (Bkg), missed detections (Miss), false positives (FalsePos), and false negatives (FalseNeg). By examining these granular error patterns, we can better understand the specific mechanisms through which our proposed modules contribute to the overall detection performance improvements.
Table 3 presents a comprehensive breakdown of the detection errors across the validation and test sets, comparing our DroneDetect variants with the YOLOv8s baseline. The results demonstrate consistent improvements across multiple error categories, with DroneDetect-Enhanced achieving the most significant reductions. Notably, classification errors decreased from 16.46% to 16.24% in the validation set, whereas localization errors improved substantially from 3.33% to 2.82%. Progressive enhancement was particularly evident in the duplicate detection reduction (0.21% to 0.17% on validation) and missed detection improvements (19.01% to 18.56%). False negative rates also showed consistent improvement, dropping from 36.01% to 35.48% on validation and from 31.98% to 31.41% on the test sets, indicating enhanced recall performance.
TIDE analysis revealed that the proposed enhancements primarily address localization precision and classification accuracy, which are two critical challenges in aerial object detection. These insights indicate that future improvements should focus on further reducing missed detections and false negatives, which remain the dominant error sources. Understanding these error patterns provides valuable guidance for developing more targeted solutions to enhance the detection performance in complex aerial scenarios with varying object scales and environmental conditions.
5.4. Cross-Dataset Validation on UAVDT, CARPK, and DIOR
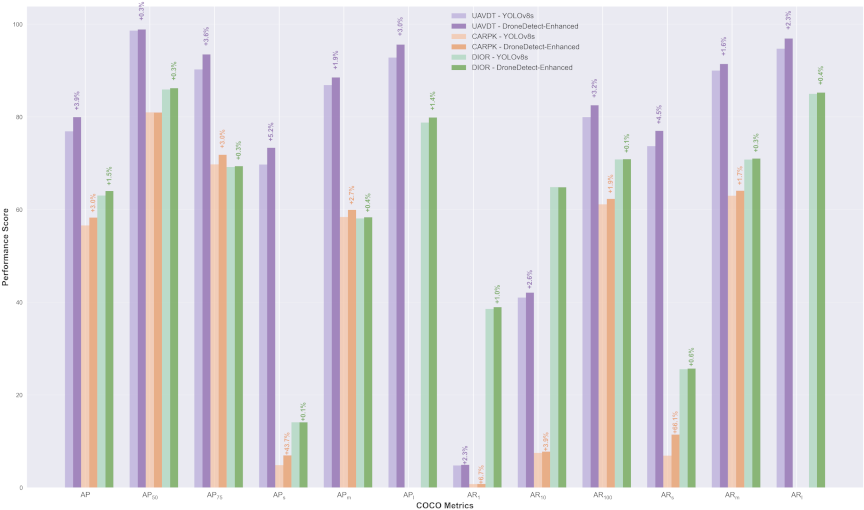
Fig. 8. COCO metrics comparison: YOLOv8s vs. DroneDetect-Enhanced across UAVDT, CARPK, and DIOR datasets.
To validate the generalizability of our model beyond the primary VisDrone dataset, we conducted comprehensive cross-dataset validation using three additional aerial detection benchmarks: UAVDT, CARPK, and DIOR. This evaluation demonstrates the robustness of our model across diverse aerial scenarios, varying object types, and different imaging conditions. Cross-dataset validation is crucial for establishing the practical applicability of our approach because it reveals whether learned features and architectural improvements are transfered effectively to unseen domains with different characteristics and challenges.
Figure 8 shows comprehensive COCO metrics comparison between YOLOv8s and DroneDetect-Enhanced across the UAVDT, CARPK, and DIOR datasets, evaluating both the average precision (AP) and average recall (AR) at various IoU thresholds and object scales. The figure demonstrates consistent performance improvements across all three datasets, with DroneDetect-Enhanced achieving substantial gains in AP metrics: \(+\)3.9% on UAVDT, \(+\)3.0% on CARPK, and \(+\)1.5% on DIOR, compared with the baseline YOLOv8s. Notably, the improvements were most pronounced in the \(\textrm{AP}_{50}\) and \(\textrm{AP}_{75}\) metrics, indicating an enhanced localization accuracy. The consistent performance gains across diverse datasets validated the generalizability of our architectural enhancements and demonstrated the effectiveness of the model in handling various aerial detection scenarios.
6. Discussion
6.1. COCO Benchmark Analysis
Table 4. Performance evaluation with COCO metrics on VisDrone validation.

Table 5. Performance evaluation with COCO metrics on VisDrone test.

Table 6. Comprehensive benchmarking results across four datasets: UAVDT, CARPK, DIOR, and VisDrone.

The COCO benchmark evaluation provides standardized metrics that are essential for assessing the object detection performance across diverse scenarios and object characteristics. This comprehensive analysis enables a direct comparison with state-of-the-art methods while revealing model strengths and limitations across different object scales, densities, and detection thresholds. Such an evaluation is particularly crucial for aerial detection tasks, in which objects exhibit extreme scale variations and complex spatial distributions.
Tables 4 and 5 present detailed COCO metrics for validation and test sets, respectively, comparing our progressive model enhancements against the YOLOv8s baseline. These tables show consistent improvements across all model variants, with DroneDetect-Enhanced achieving the highest performance gains. Notable highlights include overall AP improvements of \(+\)2.39 on validation (from 21.66 to 24.05) and \(+\)1.74 on test sets (from 16.99 to 18.73). The results show particularly strong enhancements in medium-scale object detection (\(\textrm{AP}_{m}\)) and substantial improvements in recall metrics (AR) across all object sizes.
The object size analysis revealed distinct performance patterns across the detection pipeline. Small objects (\(\textrm{AP}_{s}\)) present the greatest challenge, with baseline performance at 12.75 (validation) and 7.68 (test), showing modest but consistent improvements of \(+\)1.32 and \(+\)0.98, respectively, through our enhancements. Medium objects (\(\textrm{AP}_{m}\)) demonstrated optimal detection accuracy, achieving 32.5 (validation) and 26.44 (test) accuracy with substantial gains of \(+\)3.86 and \(+\)2.72. Large objects (\(\textrm{AP}_{l}\)) maintained strong performance at 41.86 (validation) and 37.96 (test), although the improvements were more conservative at \(+\)3.36 and \(+\)0.81, suggesting that our enhancements particularly benefit medium-scale aerial objects that are common in drone imagery.
6.2. Comparison to State-of-the-Art on Several Datasets
To validate the generalizability and effectiveness of our DroneDetect-Enhanced model, we conducted comprehensive comparisons with established state-of-the-art methods across four diverse aerial object detection datasets. This multi-dataset evaluation demonstrates the robustness of our approach across varying scene complexities, object scales, and detection challenges inherent in drone-based imagery. By benchmarking against well-established baselines and recent advanced methods, we provide evidence of the superior performance and practical applicability of our model in real-world aerial surveillance and monitoring scenarios.
Table 7. Comparative analysis of YOLOv8 variants: training time, parameters, GFLOPs, and detection performance on test and validation sets.

Table 6 presents a comprehensive comparison of our DroneDetect-Enhanced model against state-of-the-art methods across four challenging datasets. Our approach consistently outperformed the competing methods, achieving 79.93% AP on UAVDT (surpassing PRB-FPN’s previous best of 76.55%), establishing new benchmarks on CARPK with an MAE of 5.19 and RMSE of 7.26 (significantly improved over BMNet+’s 5.76 and 7.83), reaching 86.20% \(\textrm{mAP}_{50}\) on DIOR (exceeding RingMo’s 75.90%), and attaining 32.65% \(\textrm{AP}_{50}\) on VisDrone (outperforming FPN’s 32.20%). These results demonstrated the effectiveness of the proposed progressive enhancement strategy for diverse aerial detection scenarios.
6.3. Parameter and Computational Complexity Analysis
Understanding the computational trade-offs between model performance and resource requirements is crucial for the practical deployment of aerial object detection systems. Drone-based applications often operate in constrained computational environments, making it essential to evaluate not only the detection accuracy but also the parameter efficiency, computational complexity, and training overhead. This analysis provides insights into the cost-effectiveness of the proposed enhancements and their suitability for real-world deployment scenarios.
Table 7 presents a comprehensive comparison of the computational efficiency and detection performance of different YOLO variants. The proposed DroneDetect-Enhanced model achieves the highest detection performance (mAP of 19.8 on test set and 25.7 on validation set) while maintaining fewer parameters (11.08M) and lower computational complexity (26.4 GFLOPs) compared to the YOLOv8s baseline (11.14M parameters, 28.7 GFLOPs). However, this comes at the cost of an increased training time (308 s vs. 60 s per epoch), primarily becasue of the attention mechanisms in the CSRFA module. Compared with newer YOLO variants (YOLOv10-12), our model demonstrated superior accuracy-efficiency trade-offs, justifying the additional computational overhead during training for significantly improved detection capabilities.
6.4. Visual Analysis and Detection Visualization
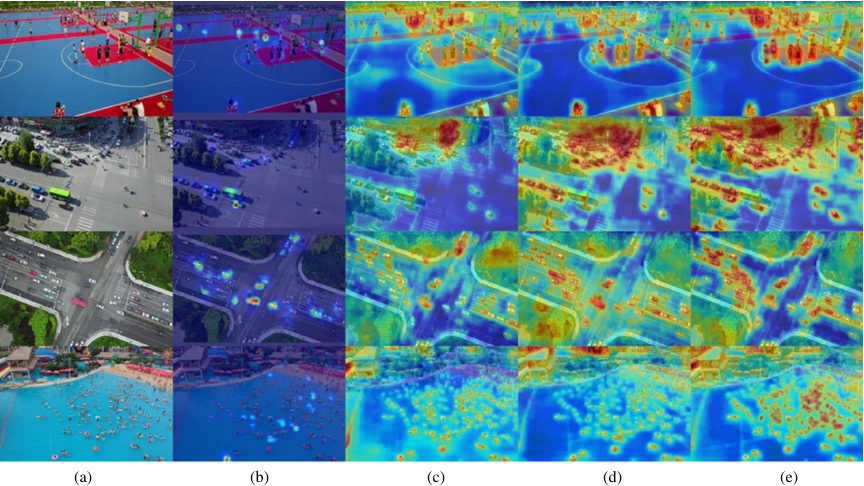
Fig. 9. Heatmaps for object detection: YOLOv8s (baseline) vs. DroneDetect-Fusion vs. DroneDetect-Attn vs. DroneDetect-Enhanced.
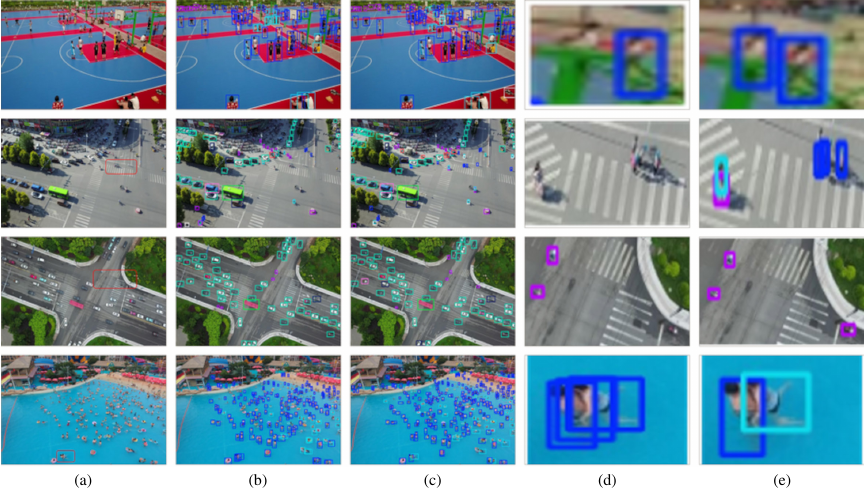
Fig. 10. Comparison of object detection performance on challenging aerial scenarios.
Visual analysis through heatmaps and detection visualization provides crucial insights into the model behavior and performance characteristics. Heatmaps reveal the spatial attention patterns and feature activation distributions across different network layers, enabling an understanding of how attention mechanisms focus on salient regions. Visualization of the detection results demonstrates practical performance differences between models, highlighting improvements in challenging scenarios such as small object detection, dense crowds, and complex backgrounds that are prevalent in aerial imagery.
Gradient-weighted Class Activation Mapping (GradCAM) serves as the foundational visualization technique employed to generate attention heatmaps, providing interpretable insights into the decision-making processes of deep neural networks. GradCAM leverages the gradients of the target classes flowing into the final convolutional layer to produce coarse localization maps, highlighting important regions for prediction without requiring architectural modifications or retraining. By computing the gradient of the class score with respect to the feature maps and applying global average pooling, GradCAM generates class-discriminative visualizations that reveal the spatial locations that contribute most significantly to the model’s predictions. This gradient-based approach is particularly valuable for aerial object detection tasks because it enables researchers to verify whether models focus on semantically meaningful object features rather than spurious correlations or background artifacts, thereby providing an empirical validation of architectural improvements and attention mechanisms.
Figure 9 shows the effectiveness of the attention mechanism effectiveness across progressive model enhancements. This visualization demonstrates the manner in which DroneDetect-Enhanced (Fig. 9(e)) generates more focused and precise attention maps than the baseline model. In the second row traffic intersection scene, our enhanced model showed significantly improved attention localization on vehicle objects, with reduced background noise and stronger activation on actual targets. The heatmap revealed that the CSRFA module successfully captured multiscale spatial relationships, producing concentrated attention on small vehicles while maintaining spatial coherence across a complex urban environment.
Figure 10 shows a comprehensive detection performance analysis across challenging aerial scenarios. Fig. 10(a) shows the original images with red bounding boxes, highlighting particularly difficult objects that suffer from scale variation, occlusion, or low contrast. Figs. 10(b) and (c) compare the YOLOv8s baseline with the DroneDetect-Enhanced detection results, demonstrating substantial improvements. The enlarged views in Figs. 10(d) and (e) clearly show that our enhanced model successfully detects previously missed small objects in crowded scenes, and provides more accurate bounding box localization, which is particularly evident in the beach crowd detection scenario.
The qualitative analysis reinforces our quantitative findings, demonstrating that the integration of the EUCB-FPN, CSRFA, and LSDECD modules creates a synergistic effect that significantly enhances the detection capabilities. The attention visualizations reveal that our model learns more discriminative features and spatial relationships, whereas the detection comparisons show tangible improvements in real-world challenging scenarios. These visual results validate the effectiveness of our architectural innovations and provide evidence for the practical applicability of DroneDetect-Enhanced in drone-based surveillance and monitoring.
7. Conclusion
This study addresses the critical challenges in aerial object detection, where complex scenes and varying object sizes, densities, and perspectives significantly affect the detection performance. We propose DroneDetect-Enhanced, a progressively enhanced YOLOv8s-based model that integrates multiscale feature fusion (EUCB-FPN), attention mechanisms (CSRFA), and efficient detection heads (LSDECD). Our approach achieved superior performance across multiple drone-based datasets while maintaining computational efficiency, demonstrating significant improvements over baseline models and competitive results compared to state-of-the-art methods.
Although the proposed DroneDetect-enhanced model showed promising results, several areas warrant further investigation. The detection performance for small-scale objects remains challenging and requires targeted improvements, potentially through adaptive receptive field mechanisms or scale-aware feature enhancement techniques. Future research should explore the integration of transformer-based attention mechanisms to better capture long-range dependencies in aerial imagery. In addition, investigating domain adaptation techniques for cross-dataset generalization and developing lightweight architectures for real-time deployment on resource-constrained drone platforms are important directions. Furthermore, incorporating temporal information from video sequences and addressing detection under adverse weather conditions can significantly enhance the practical applicability of aerial object detection systems.
Acknowledgments
The authors sincerely thank Wuxi Taihu University for its support and resources that contributed to this research.
- [1] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 779-788, 2016. https://doi.org/10.1109/CVPR.2016.91
- [2] S.-Y. Fu, D. Wei, and L.-Y. Zhou, “Improved YOLOv8-based algorithm for detecting helmets of electric moped drivers and passengers,” J. Adv. Comput. Intell. Intell. Inform., Vol.29, No.2, pp. 349-357, 2025. https://doi.org/10.20965/jaciii.2025.p0349
- [3] J. Leng et al., “Recent advances for aerial object detection: A survey,” ACM Computing Surveys, Vol.56, No.12, Article No.296, 2024. https://doi.org/10.1145/3664598
- [4] T.-Y. Lin et al., “Feature pyramid networks for object detection,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 936-944, 2017. https://doi.org/10.1109/CVPR.2017.106
- [5] Z. Yang et al., “Multi-branch auxiliary fusion YOLO with re-parameterization heterogeneous convolutional for accurate object detection,” Proc. of the 7th Chinese Conf. on Pattern Recognition and Computer Vision, Part 12, pp. 492-505, 2024. https://doi.org/10.1007/978-981-97-8858-3_34
- [6] J. Park, S. Woo, J.-Y. Lee, and I. S. Kweon, “BAM: Bottleneck attention module,” arXiv:1807.06514, 2018. https://doi.org/10.48550/arXiv.1807.06514
- [7] T. Zhang et al., “CAS-ViT: Convolutional additive self-attention vision transformers for efficient mobile applications,” arXiv:2408.03703, 2024. https://doi.org/10.48550/arXiv.2408.03703
- [8] G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO (version 8.0.0),” 2023. https://github.com/ultralytics/ultralytics [Accessed August 12, 2023]
- [9] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” arXiv:1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767
- [10] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “YOLOv4: Optimal speed and accuracy of object detection,” arXiv:2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934
- [11] C.-Y. Wang, I.-H. Yeh, and H.-Y. M. Liao, “YOLOv9: Learning what you want to learn using programmable gradient information,” Proc. of the 18th European Conf. on Computer Vision, Part 31, pp. 1-21, 2024. https://doi.org/10.1007/978-3-031-72751-1_1
- [12] A. Wang et al., “YOLOv10: Real-time end-to-end object detection,” arXiv:2405.14458, 2024. https://doi.org/10.48550/arXiv.2405.14458
- [13] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 8759-8768, 2018. https://doi.org/10.1109/CVPR.2018.00913
- [14] M. Tan, R. Pang, and Q. V. Le, “EfficientDet: Scalable and efficient object detection,” 2020 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 10778-10787, 2020. https://doi.org/10.1109/CVPR42600.2020.01079
- [15] C. Wang et al., “Gold-YOLO: Efficient object detector via gather-and-distribute mechanism,” Proc. of the 37th Int. Conf. on Neural Information Processing Systems, pp. 51094-51112, 2023.
- [16] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 7132-7141, 2018. https://doi.org/10.1109/CVPR.2018.00745
- [17] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” Proc. of the 15th European Conf. on Computer Vision, Part 7, pp. 3-19, 2018. https://doi.org/10.1007/978-3-030-01234-2_1
- [18] C. Li et al., “YOLOv6 v3.0: A full-scale reloading,” arXiv:2301.05586, 2023. https://doi.org/10.48550/arXiv.2301.05586
- [19] M. M. Rahman, M. Munir, and R. Marculescu, “EMCAD: Efficient multi-scale convolutional attention decoding for medical image segmentation,” 2024 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 11769-11779, 2024. https://doi.org/10.1109/CVPR52733.2024.01118
- [20] C.-Y. Wang, H.-Y. M. Liao, and I.-H. Yeh, “Designing network design strategies through gradient path analysis,” arXiv:2211.04800, 2022. https://doi.org/10.48550/arXiv.2211.04800
- [21] X. Zhang et al., “RFAConv: Innovating spatial attention and standard convolutional operation,” arXiv:2304.03198, 2023. https://doi.org/10.48550/arXiv.2304.03198
- [22] Z. Chen, Z. He, and Z.-M. Lu, “DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention,” IEEE Trans. on Image Processing, Vol.33, pp. 1002-1015, 2024. https://doi.org/10.1109/TIP.2024.3354108
- [23] D. Du et al., “VisDrone-DET2019: The vision meets drone object detection in image challenge results,” 2019 IEEE/CVF Int. Conf. on Computer Vision Workshop, pp. 213-226, 2019. https://doi.org/10.1109/ICCVW.2019.00030
- [24] D. Du et al., “The unmanned aerial vehicle benchmark: Object detection and tracking,” arXiv:1804.00518, 2018. https://doi.org/10.48550/arXiv.1804.00518
- [25] M.-R. Hsieh, Y.-L. Lin, and W. H. Hsu, “Drone-based object counting by spatially regularized regional proposal network,” 2017 IEEE Int. Conf. on Computer Vision, pp. 4165-4173, 2017. https://doi.org/10.1109/ICCV.2017.446
- [26] K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in optical remote sensing images: A survey and a new benchmark,” ISPRS J. of Photogrammetry and Remote Sensing, Vol.159, pp. 296-307, 2020. https://doi.org/10.1016/j.isprsjprs.2019.11.023
- [27] T.-Y. Lin et al., “Microsoft COCO: Common objects in context,” Proc. of the 13th European Conf. on Computer Vision, Part 5, pp. 740-755, 2014. https://doi.org/10.1007/978-3-319-10602-1_48
- [28] S. Xu et al., “HCF-Net: Hierarchical context fusion network for infrared small object detection,” 2024 IEEE Int. Conf. on Multimedia and Expo, 2024. https://doi.org/10.1109/ICME57554.2024.10687431
- [29] Y. Jiang, Z. Tan, J. Wang, X. Sun, M. Lin, and H. Li, “GiraffeDet: A heavy-neck paradigm for object detection,” arXiv:2202.04256, 2022. https://doi.org/10.48550/arXiv.2202.04256
- [30] D. Bolya, S. Foley, J. Hays, and J. Hoffman, “TIDE: A general toolbox for identifying object detection errors,” Proc. of the 16th European Conf. on Computer Vision, Part 3, pp. 558-573, 2020. https://doi.org/10.1007/978-3-030-58580-8_33
- [31] K. Ayush et al., “Geography-aware self-supervised learning,” 2021 IEEE/CVF Int. Conf. on Computer Vision, pp. 10161-10170, 2021. https://doi.org/10.1109/ICCV48922.2021.01002
- [32] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” Proc. of the 29th Int. Conf. on Neural Information Processing Systems, pp. 91-99, 2015.
- [33] Y. Cong et al., “SatMAE: Pre-training transformers for temporal and multi-spectral satellite imagery,” Proc. of the 36th Int. Conf. on Neural Information Processing Systems, pp. 197-211, 2022.
- [34] Z. Li et al., “DetNet: A backbone network for object detection,” arXiv:1804.06215, 2018. https://doi.org/10.48550/arXiv.1804.06215
- [35] T. N. Mundhenk, G. Konjevod, W. A. Sakla, and K. Boakye, “A large contextual dataset for classification, detection and counting of cars with deep learning,” Proc. of the 14th European Conf. on Computer Vision, Part 3, pp. 785-800, 2016. https://doi.org/10.1007/978-3-319-46487-9_48
- [36] X. Sun et al., “RingMo: A remote sensing foundation model with masked image modeling,” IEEE Trans. on Geoscience and Remote Sensing, Vol.61, Article No.5612822, 2023. https://doi.org/10.1109/TGRS.2022.3194732
- [37] D. Wang et al., “Advancing plain vision transformer toward remote sensing foundation model,” IEEE Trans. on Geoscience and Remote Sensing, Vol.61, Article No.5607315, 2023. https://doi.org/10.1109/TGRS.2022.3222818
- [38] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” 2017 IEEE Int. Conf. on Computer Vision, pp. 2999-3007, 2017. https://doi.org/10.1109/ICCV.2017.324
- [39] H. Perreault, M. Héritier, P. Gravel, G.-A. Bilodeau, and N. Saunier, “RN-VID: A feature fusion architecture for video object detection,” arXiv:2003.10898, 2020. https://doi.org/10.48550/arXiv.2003.10898
- [40] N. Amini-Naieni, K. Amini-Naieni, T. Han, and A. Zisserman, “Open-world text-specified object counting,” arXiv:2306.01851, 2023. https://doi.org/10.48550/arXiv.2306.01851
- [41] C. Tao et al., “TOV: The original vision model for optical remote sensing image understanding via self-supervised learning,” IEEE J. of Selected Topics in Applied Earth Observations and Remote Sensing, Vol.16, pp. 4916-4930, 2023. https://doi.org/10.1109/JSTARS.2023.3271312
- [42] Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 6154-6162, 2018. https://doi.org/10.1109/CVPR.2018.00644
- [43] H. Perreault, G.-A. Bilodeau, N. Saunier, and M. Héritier, “SpotNet: Self-attention multi-task network for object detection,” arXiv:2002.05540, 2020. https://doi.org/10.48550/arXiv.2002.05540
- [44] E. Goldman, R. Herzig, A. Eisenschtat, J. Goldberger, and T. Hassner, “Precise detection in densely packed scenes,” 2019 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 5222-5231, 2019. https://doi.org/10.1109/CVPR.2019.00537
- [45] Y. Wang et al., “SSL4EO-S12: A large-scale multi-modal, multi-temporal dataset for self-supervised learning in earth observation,” arXiv:2211.07044, 2023. https://doi.org/10.48550/arXiv.2211.07044
- [46] H. Perreault, G.-A. Bilodeau, N. Saunier, and M. Héritier, “FFAVOD: Feature fusion architecture for video object detection,” Pattern Recognition Letters, Vol.151, pp. 294-301, 2021. https://doi.org/10.1016/j.patrec.2021.09.002
- [47] S. Kang, W. Moon, E. Kim, and J.-P. Heo, “VLCounter: Text-aware visual representation for zero-shot object counting,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.38, No.3, pp. 2714-2722, 2024. https://doi.org/10.1609/aaai.v38i3.28050
- [48] D. Muhtar, X. Zhang, P. Xiao, Z. Li, and F. Gu, “CMID: A unified self-supervised learning framework for remote sensing image understanding,” IEEE Trans. on Geoscience and Remote Sensing, Vol.61, Article No.5607817, 2023. https://doi.org/10.1109/tgrs.2023.3268232
- [49] P.-Y. Chen, M.-C. Chang, J.-W. Hsieh, and Y.-S. Chen, “Parallel residual bi-fusion feature pyramid network for accurate single-shot object detection,” IEEE Trans. on Image Processing, Vol.30, pp. 9099-9111, 2021. https://doi.org/10.1109/tip.2021.3118953
- [50] M. Shi, H. Lu, C. Feng, C. Liu, and Z. Cao, “Represent, compare, and learn: A similarity-aware framework for class-agnostic counting,” 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 9519-9528, 2022. https://doi.org/10.1109/CVPR52688.2022.00931
- [51] U. Mall, B. Hariharan, and K. Bala, “Change-aware sampling and contrastive learning for satellite images,” 2023 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 5261-5270, 2023. https://doi.org/10.1109/CVPR52729.2023.00509
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.