Research Paper:
Usage Behaviors of Large Language Models: Taking Undergraduate Students as an Example
Chien-Chou Chen
 and Hung-Yi Lu†
and Hung-Yi Lu†
Department of Statistics and Information Science, Fu Jen Catholic University
No.510 Zhongzheng Rd., Xinzhuang Dist., New Taipei 242062, Taiwan
†Corresponding author

This study reveals the usage behaviors of large language models (LLMs) by undergraduate students (n=56) taking a Management Information Systems course in Spring 2025 at a private university in Taiwan. The study investigates the following: (1) the required courses where students use LLMs, (2) the LLM tools students use, and (3) the paid tools of LLMs students use to assist in their studies. We also examine (1) the association rule analysis of courses using LLMs and (2) the content analysis of the title of an assignment (a word cloud). This study provides firsthand information on the use of LLMs by undergraduate students and offers relevant suggestions for academic settings based on both quantitative and qualitative analyses.

Word cloud of proposal titles generated by large language models
1. Introduction
With advances in artificial intelligence technology, large language models (LLMs) based on generative pretrained transformers (GPTs) 1, such as ChatGPT launched by OpenAI in 2022 2, Gemini released by Google in 2023 3, and DeepSeek initiated by DeepSeek in 2025 4, have been developed. Although LLMs have only been around for a short time, their performance has been very impressive in natural language processing tasks, such as answering questions, language translation, drafting, mathematics problem-solving, and programming. Various LLM-based applications in education have been developed and are thriving 5.
Although LLMs seem promising for assisting in learning, there remain many questions on their use in university settings. For example, what are the usage behaviors of students when interacting with LLMs across courses and tools? In conditions where LLMs are allowed, what are students’ attitudes toward the use of LLMs? More specifically, are students concerned about the quality of the content produced by LLMs? To address these issues, we conducted a study with 56 students using a questionnaire survey. We hope that this study can address the above-mentioned issues and enrich the research on LLM-powered tools in university education.
2. Literature Review
We reviewed the related literature concerning (1) LLMs and (2) the usage behavior of LLMs by students in a university setting.
2.1. LLMs
LLMs are highly complex functions defined as \(f(x)\), and are composed of a large number of parameters (more than \(10^9\)). Input \(x\) generates the probability distribution of output \(y\) (\(=f(x)\)). The minimum input unit of LLMs is a token 6, which can be a single word, phrase, or sentence. Through pretraining and fine-tuning a large amount of training data to estimate model parameters, LLMs can understand the meaning and relationship between each token.
For example, when we ask LLMs through a prompt query (\(=x\)): “Brazil is located in South America, where is Canada located?” LLMs would answer with the result of the highest probability (\(y=\)): “North America.” Taking the series of OpenAI’s GPT as an example, GPT-3 has 175 billion model parameters 7, and the number of parameters of the GPT-4 model far exceeds that of GPT-3. Similarly, although Google has not announced the amount of data and parameters of Gemini, its predecessor Bard has 137 billion parameters 8.
2.2. Usage Behavior of LLMs
The following literature review represents a mix of disciplines: biology, engineering, and computer science, and examines undergraduate students’ usage behavior toward LLMs. It offers a well-rounded view of how students integrate LLMs into their learning process. Paustian and Slinger 9 investigated how undergraduate students (at the University of Wisconsin–Madison, U.S.A.) in a Microbiology course used LLMs such as ChatGPT. They found that nearly half (46.9%) of the total 153 students used LLMs during the semester, primarily for assignments and sometimes for writing entire papers. They also evaluated the effectiveness of LLM detectors and found an 88% success rate, which was insufficient to confidently identify LLM-generated content.
Bernabei et al. 10 examined the use and acceptance of LLMs by 31 engineering students at the Sapienza University of Rome, focusing on their perceptions, trust, and actual application of LLMs in academic settings. While many students found LLMs helpful for idea generation and writing support, concerns about accuracy and ethical implications influenced their usage behavior. Arora et al. 11 analyzed the use of LLMs by 411 students in a Distributed Systems course offered by the Computer Science program at a tier-one Indian university. They found that students leveraged LLMs for tasks such as code generation, debugging, and clarifying complex concepts. They also explored how prompting strategies and varying levels of reliance affected learning outcomes and raised concerns about the over-dependence on LLM assistance. Padiyath et al. 12 explored how 158 undergraduate students (at the University of Michigan, U.S.A.) adopted LLMs in a programming course. They suggested that students’ LLMs usage was shaped by motivations such as career preparation and peer influence, and that early LLM usage was correlated with lower self-efficacy and exam performance.
3. Research Methodology
The objectives of this study are twofold. First, we examined (1) the courses where students used LLMs, (2) the LLM tools used by students, and (3) the paid tools of LLMs used by students in their studies. Second, we investigated (1) the association rule analysis of courses using LLMs and (2) the content analysis of report titles (word cloud analysis).
3.1. Data Collection
Data was collected from undergraduate students taking a Management Information Systems course in Spring 2025—a required course for sophomores—at a private university in Taiwan. Informed consent was obtained from all participants. The total number of participants (\(n\)) was 56.
3.2. Questionnaire
Table 1. Questionnaire on the use of LLMs.

Table 1 lists the questions asked on the use of LLMs. Questions 1–3 are multiple selections; Question 4 is an open-ended survey that asks students to generate a data mining proposal following the cross-industry standard process for data mining (CRISP-DM). Students were expected to self-report if LLMs were used.
3.3. Association Rules
Association rule learning is a data mining technique used to discover relationships, patterns, or associations between variables in large datasets. It was originally derived from Piatetsky-Shapiro’s 13 strong rules. It is well known for its application in market basket analysis by Agrawal et al. 14, where the goal is to identify items frequently purchased together by customers.
An association rule takes the form of “If \(X\), then \(Y\),” (written as \(X\) \(\Rightarrow\) \(Y\)), where \(X\) and \(Y\) are item sets. For example, in a retail setting, a rule such as {Diaper} \(\Rightarrow\) {Beer} might show that customers who buy diapers are also likely to buy beer. These rules help store owners make decisions related to product placement, cross-selling, and inventory management. Algorithms for association rule mining, such as Apriori, FP-Growth, and Eclat, are commonly used to extract rules from datasets 15. An association rule is measured using three key metrics:
-
(1)
Support: The proportion of transactions in the dataset containing both \(X\) and \(Y\). It reflects the frequency at which the rule appears in the data.
-
(2)
Confidence: The probability of seeing \(Y\) in transactions that already contain \(X\). It measures the reliability of inferences made by the rule.
-
(3)
Lift: The ratio of the observed support of \(X\) and \(Y\) appearing together to the expected support if \(X\) and \(Y\) were independent. A lift greater than one indicates a positive association between \(X\) and \(Y\). These metrics are expressed as follows:
\begin{align} \label{eq:1} \textit{Support}\left(X\Rightarrow Y\right)&=P(X\cap Y),\\ \end{align}\begin{align} \label{eq:2} \textit{Confidence}\left(X\Rightarrow Y \right)&=P(Y\mid X),\\ \end{align}\begin{align} \label{eq:3} \textit{Lift}\left(X\Rightarrow Y\right)&=\dfrac{P(X\cap Y)}{P(X)\cdot P(Y)}. \end{align}
3.4. Data Analysis
The R software (version 4.5) was applied for statistical analysis. The R packages arules and wordcloud were used for the association rule and word cloud analyses, respectively.
4. Results
In this pilot study, we investigated 56 undergraduate students’ use of LLMs based on quantitative (Sections 4.1 and 4.2) and qualitative (Section 4.3) approaches.
4.1. Descriptive Statistics of the Usage of LLMs
The following subsections highlight the descriptive statistics of Questions 1, 2, and 3 (Table 1) on the use of LLMs among 56 undergraduate students.
4.1.1. Percentages of Courses LLMs were Used
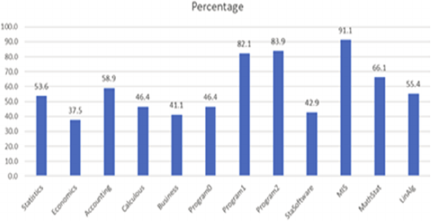
Fig. 1. Percentages of use of large language models across courses.
Figure 1 shows the percentage of students who used LLMs in required courses. The course with the highest percentage (91.1%) of LLMs usage was Management Information Systems. In contrast, Economics had the lowest percentage of users (37.5%). Variations in the adoption of LLMs may be attributed to factors such as instructor policies or student background. The reasons why courses such as Management Information Systems have a higher LLMs adoption rate compared to Economics requires further investigation. The overall average usage of LLMs among the 12 required courses was 58.8%.
4.1.2. Percentages of Tools of LLMs Used
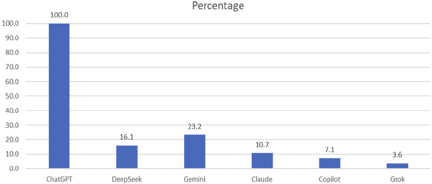
Fig. 2. Percentages of use of large language models across tools.
Figure 2 shows the percentage of LLM tool usage among Taiwanese undergraduate students. The tool with the highest usage percentage (100%) was ChatGPT. Conversely, Grok was the least used tool (3.6%). We observed that 18.0% of students subscribed to ChatGPT for $20 per month.
4.2. Association Rules of Courses
Table 2 shows three association rules: (1) Programming \(\Rightarrow\) Advanced Programming, (2) Advanced Programming \(\Rightarrow\) Management Information Systems, and (3) Programming \(\Rightarrow\) Management Information Systems, with lifts of 1.087, 1.027, and 1.002, respectively.
Taking Programming \(\Rightarrow\) Advanced Programming as an example, we observed that (a) 75.0% of all surveys contained both items based on Eq. \(\eqref{eq:1}\); (b) 91.3% of students used LLMs for Programming and Advanced Programming courses based on Eq. \(\eqref{eq:2}\); (c) those using LLMs for Programming were 1.087 times more likely to use LLMs for Advanced Programming based on Eq. \(\eqref{eq:3}\), indicating a strong positive association.
Table 2. Support, confidence, and lift of the courses.


Fig. 3. Screenshot of the proposal titles.
4.3. Word Cloud Analysis
According to Q4 in Table 1, we used a word cloud (also known as a tag cloud) to visualize the titles of the 56 data mining proposals, where the size of each word reflected its frequency and importance in the dataset. The first impression of these titles was that their semantic structures were very similar (Fig. 3).
The majority of students (54 out of 56) self-reported the use of LLMs to generate the proposal, including the title of the report. Words that appeared most often in the title of data mining proposals were “customer,” “churn,” and “using” (Fig. 4). This may be attributed to the fact that LLMs accept highly similar tokens, such as CRISP-DM. The popular CRISP-DM methodology for data mining and its widely available teaching materials are grounded in business case studies. Therefore, LLMs can mirror these dominant documents. The repetitive outputs generated by LLMs also indicate the potential risk of violating academic integrity.

Fig. 4. Word cloud of the proposal titles.
4.4. Discussion
To the best of our knowledge, this is the first study on the use of LLMs in courses for Taiwanese undergraduate students. Compared with students in other countries 9, Taiwanese students seem to have a relatively high percentage (58.8%) of LLM usage. Interestingly, ChatGPT dominated the use of LLMs (100%), with 18.0% as paid users. Chou et al. 16 further developed the unified theory of acceptance and use of technology (UTAUT) model to study the factors influencing the adoption of LLMs among 454 Taiwanese ChatGPT users recruited from social media and online forums. They concluded that performance and effort expectancies are the two main factors related to behavioral intentions. The UTAUT model provides a framework to associate factors influencing the adoption of LLMs. Further insights into the use of LLMs by undergraduate Taiwanese students may be obtained by applying the UTAUT model in our study.
The results of the association rule analysis demonstrated the possible implications in academic settings. Programming accompanying Advanced Programming, Advanced Programming accompanying Management Information Systems, and Programming accompanying Management Information Systems indicate the mixed use of LLMs in these computer science-related courses. There is a need to integrate LLM literacy into these curricula 17. For example, collaborations among instructors to integrate LLMs into lectures might assist in digital literacy training.
Visualizing the titles of the data mining proposal reveals the limitations of generated content and the misuse of LLMs. When prompts of LLMs are limited to unique terminology such as CRISP-DM, the outcome of the generated text is expected to be similar and of poor quality. Owing to time constraints, we only analyzed the title of the data mining proposal. We plan to assess the full document and study the efficiency of detecting LLM-generated text in future work 18.
Another interesting finding is that students were willing to declare their use of LLMs (54 out of 56 students). Therefore, establishing correct and reasonable usage concepts for LLMs, for example, indicating that the document was produced by LLMs and fully disclosing the version and time of LLMs, is crucial 19. Some limitations of the study are that self-reported data are prone to recall bias, and the findings may not be generalized across institutions or disciplines due to the small sample size of the study.
5. Conclusion
This study examined the use of LLMs by 56 Taiwanese undergraduate students taking a Management Information Systems course at a private university. We investigated (1) the courses in which students used LLMs, (2) the LLM tools used by students, and (3) the paid LLM tools used by students to assist in their studies. We also conducted (1) the association rule analysis of courses using LLMs and (2) the word cloud analysis of assignment titles. This study provides first-hand information on the use of LLMs by undergraduate students and offers relevant suggestions for their use in university settings based on the results of quantitative and qualitative analyses. Future research should increase the sample size to generalize the study. We will further (1) explore the detection of LLM-generated text and (2) promote the ethical and transparent use of LLMs to reveal insights into curriculum design and develop guidelines for transparent LLM use.
Acknowledgments
We are grateful for the funding and support from Fu Jen Catholic University (accounting number: A0111020).
- [1] G. Yenduri et al., “GPT (generative pre-trained transformer) – A comprehensive review on enabling technologies, potential applications, emerging challenges, and future directions,” IEEE Access, Vol.12, pp. 54608-54649, 2024. https://doi.org/10.1109/ACCESS.2024.3389497
- [2] ChatGPT, 2025. https://chatgpt.com/ [Accessed June 30, 2025]
- [3] Gemini, 2025. https://gemini.google/ [Accessed June 30, 2025]
- [4] DeepSeek, 2025. https://www.deepseek.com/ [Accessed June 30, 2025]
- [5] W. Lyu et al., “Evaluating the effectiveness of LLMs in introductory computer science education: A semester-long field study,” Proc. of the 11th ACM Conf. on Learning @ Scale, pp. 63-74, 2024. https://doi.org/10.1145/3657604.3662036
- [6] H. Naveed et al., “A comprehensive overview of large language models,” ACM Trans. on Intelligent Systems and Technology, Vol.16, No.5, Article No.106, 2025. https://doi.org/10.1145/3744746
- [7] T. B. Brown et al., “Language models are few-shot learners,” arXiv:2005.14165, 2020. https://doi.org/10.48550/arXiv.2005.14165
- [8] I. Ahmed et al., “ChatGPT versus Bard: A comparative study,” Engineering Reports, Vol.6, No.11, Article No.e12890, 2024. https://doi.org/10.1002/eng2.12890
- [9] T. Paustian and B. Slinger, “Students are using large language models and AI detectors can often detect their use,” Frontiers in Education. Vol.9, Article No.1374889, 2024. https://doi.org/10.3389/feduc.2024.1374889
- [10] M. Bernabei et al., “Students’ use of large language models in engineering education: A case study on technology acceptance, perceptions, efficacy, and detection chances,” Computers and Education: Artificial Intelligence, Vol.5, Article No.100172, 2023. https://doi.org/10.1016/j.caeai.2023.100172
- [11] U. Arora et al., “Analyzing LLM usage in an advanced computing class in India,” Proc. of the 27th Australasian Computing Education Conf., pp. 154-163, 2025. https://doi.org/10.1145/3716640.3716657
- [12] A. Padiyath et al., “Insights from social shaping theory: The appropriation of large language models in an undergraduate programming course,” Proc. of the 2024 ACM Conf. on Int. Computing Education Research, Vol.1, pp. 114-130, 2024. https://doi.org/10.1145/3632620.3671098
- [13] G. Piatetsky-Shapiro, “Discovery, analysis, and presentation of strong rules,” G. Piatetsky-Shapiro and W. Frawley (Eds.), “Knowledge Discovery in Databases,” pp. 255-264, AAAI/MIT Press, 1991.
- [14] R. Agrawal, T. Imieliński, and A. Swami, “Mining association rules between sets of items in large databases,” Proc. of the 1993 ACM SIGMOD Int. Conf. on Management of data, pp. 207-216, 1993. https://doi.org/10.1145/170035.170072
- [15] V. Srinadh, “Evaluation of Apriori, FP growth and Eclat association rule mining algorithms,” Int. J. of Health Sciences, Vol.6, No.S2, pp. 7475-7485, 2022. https://doi.org/10.53730/ijhs.v6nS2.6729
- [16] Y.-L. Chou, Y.-L. Wu, and R.-F. Chao, “Applying the UTAUT model to explore user behavior in ChatGPT usage,” Int. J. of Research in Business & Social Science, Vol.14, No.2, pp. 332-341, 2025. https://doi.org/10.20525/ijrbs.v14i2.4047
- [17] M. Westerlund and A. Shcherbakov, “LLM integration in workbook design for teaching coding subjects,” Proc. of the 21st Int. Conf. on Smart Technologies & Education, Vol.1, pp. 77-85, 2024. https://doi.org/10.1007/978-3-031-61891-8_7
- [18] D. Weber-Wulff et al., “Testing of detection tools for AI-generated text,” Int. J. for Educational Integrity, Vol.19, Article No.26, 2023. https://doi.org/10.1007/s40979-023-00146-z
- [19] M. Lissack and B. Meagher, “Responsible use of large language models: An analogy with the Oxford tutorial system,” She Ji: The J. of Design, Economics, and Innovation, Vol.10, No.4, pp. 389-413, 2024. https://doi.org/10.1016/j.sheji.2024.11.001
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.