Research Paper:
Verbal Representation of Object Collision Prediction Based on Physical Properties
Eri Kuroda
 and Ichiro Kobayashi
and Ichiro Kobayashi
Ochanomizu University
2-1-1 Ohtsuka, Bunkyo-ku, Tokyo 112-8610, Japan

In recent years, prediction models for the real world have been widely proposed. Most research that deals with the recognition and prediction of the real world generates prediction results from visual predictions such as changes in pixels or numerical changes in physical simulators, and few models can predict them based on both visual and physical characteristics, as humans can. Therefore, in this study, we constructed a new prediction model based on both visual information and physical characteristics in the environment by integrating the mechanism of variational temporal abstraction, which extracts change points in the observation environment from visual information, into PreCNet. Furthermore, to make the prediction results interpretable, we generated the inferred prediction content as a sentence. In addition, we verified whether the generated sentences could explain collision situations in as much detail as a human being when given physical common sense about the environment, such as the movement and mass of objects.
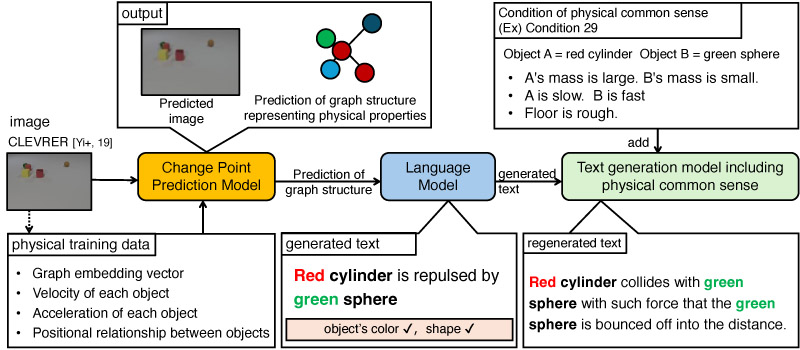
Overview of our research
- [1] D. Ha and J. Schmidhuber, “World models,” arXiv preprint, arXiv:1803.10122, 2018. https://doi.org/10.5281/zenodo.1207631
- [2] Y. LeCun, “A path towards autonomous machine intelligence,” 2022.
- [3] W. Lotter, G. Kreiman, and D. Cox, “Deep predictive coding networks for video prediction and unsupervised learning,” arXiv preprint, arXiv:1605.08104, 2016. https://doi.org/10.48550/arXiv.1605.08104
- [4] Y. Wang, H. Wu, J. Zhang, Z. Gao, J. Wang, P. S. Yu, and M. Long, “PredRNN: A recurrent neural network for spatiotemporal predictive learning,” arXiv preprint, arXiv:2103.09504, 2021. https://doi.org/10.48550/arXiv.2103.09504
- [5] Z. Straka, T. Svoboda, and M. Hoffmann, “PreCNet: Next-frame video prediction based on predictive coding,” IEEE Trans. Neural Netw. Learn. Syst., Vol.35, No.8, pp. 10353-10367, 2023. https://doi.org/10.1109/TNNLS.2023.3240857
- [6] J. Johnson, B. Hariharan, L. van der Maaten, L. Fei-Fei, C. L. Zitnick, and R. Girshick, “CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning,” arXiv preprint, arXiv:1612.06890, 2016. https://doi.org/10.48550/arXiv.1612.06890
- [7] K. Yi, C. Gan, Y. Li, P. Kohli, J. Wu, A. Torralba, and J. B. Tenenbaum, “CLEVRER: CoLlision events for video REpresentation and reasoning,” arXiv preprint, arXiv:1910.01442, 2019. https://doi.org/10.48550/arXiv.1910.01442
- [8] C. P. Burgess, L. Matthey, N. Watters, R. Kabra, I. Higgins, M. Botvinick, and A. Lerchner, “MONet: Unsupervised scene decomposition and representation,” arXiv preprint, arXiv:1901.11390, 2019. https://doi.org/10.48550/arXiv.1901.11390
- [9] J. Mao, X. Yang, X. Zhang, N. D. Goodman, and J. Wu, “CLEVRER-humans: Describing physical and causal events the human way,” arXiv preprint, arXiv:2310.03635, 2023. https://doi.org/10.48550/arXiv.2310.03635
- [10] R. Zellers, A. Holtzman, M. Peters, R. Mottaghi, A. Kembhavi, A. Farhadi, and Y. Choi, “PIGLeT: Language grounding through neuro-symbolic interaction in a 3D world,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (Vol.1: Long Papers), pp. 2040-2050, 2021.
- [11] T. Kim, S. Ahn, and Y. Bengio, “Variational temporal abstraction,” arXiv preprint, arXiv:1910.00775, 2019. https://doi.org/10.48550/arXiv.1910.00775
- [12] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT: Real-time instance segmentation,” arXiv preprint, arXiv:1904.02689, 2019. https://doi.org/10.48550/arXiv.1904.02689
- [13] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft COCO: Common objects in context,” arXiv preprint, arXiv:1405.0312, 2014. https://doi.org/10.48550/arXiv.1405.0312
- [14] A. Mafla, S. Dey, A. F. Biten, L. Gomez, and D. Karatzas, “Multi-modal reasoning graph for scene-text based fine-grained image classification and retrieval,” 2021 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 4023-4033, 2021.
- [15] Y. Zhang, J. Gao, X. Yang, C. Liu, Y. Li, and C. Xu, “Find objects and focus on highlights: Mining object semantics for video highlight detection via graph neural networks,” Proc. Conf. AAAI Artif. Intell., Vol.34, No.07, pp. 12902-12909, 2020. https://doi.org/10.1609/aaai.v34i07.6988
- [16] A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” arXiv preprint, arXiv:1607.00653, 2016. https://doi.org/10.48550/arXiv.1607.00653
- [17] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint, arXiv:1301.3781, 2013. https://doi.org/10.48550/arXiv.1301.3781
- [18] A. Narayanan, M. Chandramohan, R. Venkatesan, L. Chen, Y. Liu, and S. Jaiswal, “graph2vec: Learning distributed representations of graphs,” arXiv preprint, arXiv:1707.05005, 2017. https://doi.org/10.48550/arXiv.1707.05005
- [19] Q. V. Le and T. Mikolov, “Distributed representations of sentences and documents,” arXiv preprint, arXiv:1405.4053, 2014. https://doi.org/10.48550/arXiv.1405.4053
- [20] E. Kuroda and I. Kobayashi, “Predictive inference model of the physical environment that emulates predictive coding,” A. Bifet, A. C. Lorena, R. P. Ribeiro, J. Gama, and P. H. Abreu (Eds.), “Discovery Science,” pp. 431-445, Springer, 2023. https://doi.org/10.1007/978-3-031-45275-8_29
- [21] D. P. Kingma, T. Salimans, and M. Welling, “Variational dropout and the local reparameterization trick,” arXiv preprint, arXiv:1506.02557, 2015. https://doi.org/10.48550/arXiv.1506.02557
- [22] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” Proc. of the 40th Annual Meeting on Association for Computational Linguistics (ACL’02), pp. 311-318, 2002. https://doi.org/10.3115/1073083.1073135
- [23] A. Lavie and A. Agarwal, “METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments,” Proc. of the Second Workshop on Statistical Machine Translation, pp. 228-231, 2007.
- [24] R. Vedantam, C. L. Zitnick, and D. Parikh, “CIDEr: Consensus-based image description evaluation,” arXiv preprint, arXiv:1411.5726, 2014. https://doi.org/10.48550/arXiv.1411.5726
- [25] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” arXiv preprint, arXiv:1910.10683, 2019. https://doi.org/10.48550/arXiv.1910.10683
- [26] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” arXiv preprint, arXiv:1706.03762, 2017. https://doi.org/10.48550/arXiv.1706.03762
- [27] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint, arXiv:1711.05101, 2017. https://doi.org/10.48550/arXiv.1711.05101
- [28] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “BERTScore: Evaluating text generation with BERT,” arXiv preprint, arXiv:1904.09675, 2019. https://doi.org/10.48550/arXiv.1904.09675
- [29] T. Sellam, D. Das, and A. P. Parikh, “BLEURT: Learning robust metrics for text generation,” arXiv preprint, arXiv:2004.04696, 2020. https://doi.org/10.48550/arXiv.2004.04696
- [30] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” Proc. of the Workshop on Text Summarization Branches Out (WAS 2004), pp. 74-81, 2004.
- [31] Y. Liu, D. Iter, Y. Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: NLG evaluation using GPT-4 with better human alignment,” arXiv preprint, arXiv:2303.16634, 2023. https://doi.org/10.48550/arXiv.2303.16634
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.