Research Paper:
A Parallel CNN-Transformer Framework for Speech Age Recognition
Zheyan Zhang
 , Renwei Li
, and Kewei Chen†
, Renwei Li
, and Kewei Chen†
Faculty of Mechanical Engineering and Mechanics, Ningbo University
No.818 Fenghua Road, Ningbo, Zhejiang 315211, China
†Corresponding author

In human–robot interaction, personalized services can be provided for different age groups through speech age recognition, thereby enhancing the service robots’ intelligence. However, due to the diversity of human pronunciation and the similarity of voice features across different age groups, it is challenging to obtain accurate speech-based age recognition using traditional machine learning techniques. Therefore, this research proposes a parallel CNN-Transformer framework for speech age recognition, using deep learning techniques from image processing. Based on speech spectrograms, parallel CNN and Transformer branches extract local and global characteristics of the speech signal. To address data imbalance across age–gender categories, a spectrogram frame-shift strategy is additionally adopted, thereby expanding the training set and enhancing robustness. Additionally, the impact of gender on speech age recognition is discussed, and a single system for recognizing age and gender is implemented. An average accuracy of 84.9% is achieved through testing on the English subset of the Common Voice dataset to confirm the efficacy of the proposed model.
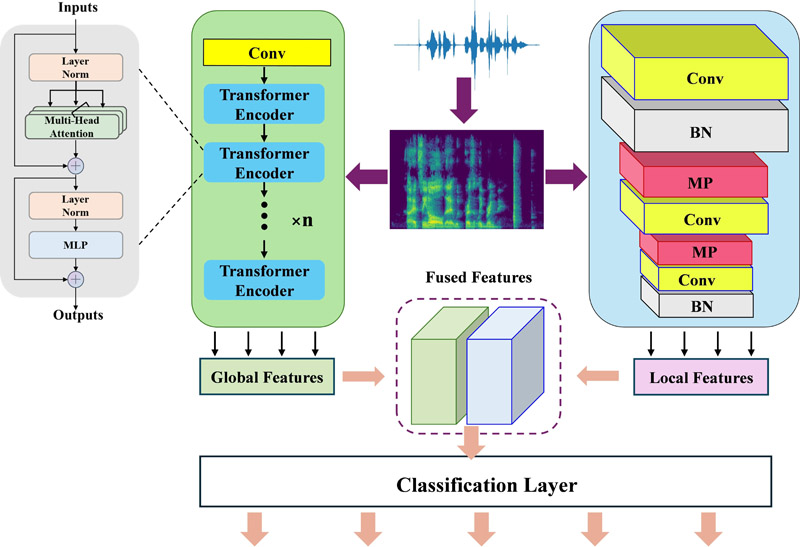
CNN-Transformer framework structure
- [1] R. M. Hanifa, K. Isa, and S. Mohamad, “A review on speaker recognition: Technology and challenges,” Computers & Electrical Engineering, Vol.90, Article No.107005, 2021. https://doi.org/10.1016/j.compeleceng.2021.107005
- [2] M. Yue, L. Chen, J. Zhang, and H. Liu, “Speaker age recognition based on isolated words by using svm,” 2014 IEEE 3rd Int. Conf. on Cloud Computing and Intelligence Systems, pp. 282-286, 2014. https://doi.org/10.1109/CCIS.2014.7175743
- [3] O. T.-C. Chen and J. J. Gu, “Improved gender/age recognition system using arousal-selection and feature-selection schemes,” 2015 IEEE Int. Conf. on Digital Signal Processing (DSP), pp. 148-152, 2015. https://doi.org/10.1109/ICDSP.2015.7251848
- [4] X.-N. Du and Y.-B. Yu, “Multi resolution feature extraction of effective frequency bands for age recognition,” J. of Signal Processing, Vol.32, No.9, pp. 1101-1107, 2016. https://doi.org/10.16798/j.issn.1003-0530.2016.09.13
- [5] M. H. Bahari, M. McLaren, and D. A. van Leeuwen, “Speaker age estimation using i-vectors,” Engineering Applications of Artificial Intelligence, Vol.34, pp. 99-108, 2014. https://doi.org/10.1016/j.engappai.2014.05.003
- [6] P. Ghahremani, P. S. Nidadavolu, N. Chen, J. Villalba, D. Povey, S. Khudanpur, and N. Dehak, “End-to-end deep neural network age estimation,” Proc. of Interspeech 2018, pp. 277-281, 2018.
- [7] A. Tursunov, Mustaqeem, J. Y. Choeh et al., “Age and gender recognition using a convolutional neural network with a specially designed multi-attention module through speech spectrograms,” Sensors, Vol.21, No.17, Article No.5892, 2021. https://doi.org/10.3390/s21175892
- [8] H. A. Sánchez-Hevia, R. Gil-Pita, M. Utrilla-Manso, and M. Rosa-Zurera, “Age group classification and gender recognition from speech with temporal convolutional neural networks,” Multimedia Tools and Applications, Vol.81, No.3, pp. 3535-3552, 2022. https://doi.org/10.1007/s11042-021-11614-4
- [9] S. Mavaddati, “Voice-based age, gender, and language recognition based on resnet deep model and transfer learning in spectro-temporal domain,” Neurocomputing, Vol.580, Article No.127429, 2024. https://doi.org/10.1016/j.neucom.2024.127429
- [10] A. Akan and O. K. Cura, “Time–frequency signal processing: Today and future,” Digital Signal Processing, Vol.119, Article No.103216, 2021. https://doi.org/10.1016/j.dsp.2021.103216
- [11] A. Vaswani, N. Shazeer, N. Parmar et al., “Attention is all you need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [12] M. A. Anusuya and S. K. Katti, “Front end analysis of speech recognition: A review,” Int. J. of Speech Technology, Vol.14, pp. 99-145, 2011. https://doi.org/10.1007/s10772-010-9088-7
- [13] R. Ardila, M. Branson, K. Davis, M. Kohler, J. Meyer, M. Henretty, R. Morais, L. Saunders, F. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” Proc. of the 12th Language Resources and Evaluation Conference (LREC), pp. 4218-4222, 2020.
- [14] P. Torre III and J. A. Barlow, “Age-related changes in acoustic characteristics of adult speech,” J. of Communication Disorders, Vol.42, No.5, pp. 324-333, 2009. https://doi.org/10.1016/j.jcomdis.2009.03.001
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.