Research Paper:
Research on Action Recognition Algorithm Based on SlowFast Network
Yinhao Xu and Yuanyao Lu†

School of Information Science and Technology, North China University of Technology
No.5 Jinyuanzhuang Road, Shijingshan District, Beijing 100144, China
†Corresponding author

As a major branch of video understanding, human action recognition has become a popular research topic in the field of computer vision and has a wide range of applications in many areas. To address the problems of high parameter consumption and weak spatiotemporal modeling capabilities in existing action recognition methods, this study proposes a lightweight dual-branch convolutional network called SlowFast-Light Net. Inspired and influenced by the renowned two-branch SlowFast network proposed by the expert Kaiming He, this study adopts a lightweight two-branch network design, which is an improvement based on the SlowFast network. The network significantly reduces parameter consumption by introducing a lightweight feature extraction network and accelerating the model convergence speed. This study conducts experimental verification on the UCF101 and HMDB51 datasets, achieving an action recognition accuracy of 93.80% and 80.00%, respectively, on the two test sets. The experimental results showed that the model proposed in this study achieved a recognition accuracy comparable to that of the original model with a considerably lower number of parameters.
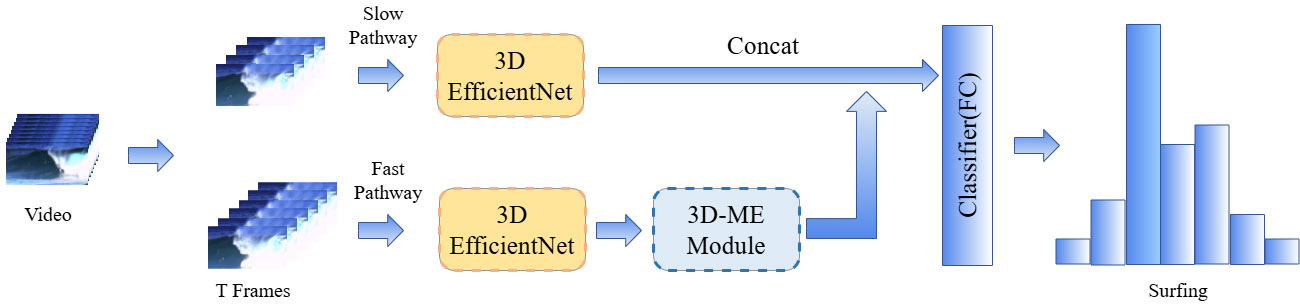
Model structure diagram for action recognition algorithm SlowFast network
- [1] S. Hoshino and K. Niimura, “Robot vision system for human detection and action recognition,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.3, pp. 346-356, 2020. https://doi.org/10.20965/jaciii.2020.p0346
- [2] C. Feichtenhofer, H. Fan, J. Malik, and K. He, “SlowFast networks for video recognition,” 2019 IEEE/CVF Int. Conf. on Computer Vision, pp. 6201-6210, 2019. https://doi.org/10.1109/ICCV.2019.00630
- [3] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 6848-6856, 2018. https://doi.org/10.1109/CVPR.2018.00716
- [4] A. G. Howard et al., “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv:1704.04861, 2017. https://doi.org/10.48550/arXiv.1704.04861
- [5] M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” Proc. of the 36th Int. Conf. on Machine Learning, pp. 6105-6114, 2019.
- [6] K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” Proc. of the 28th Int. Conf. on Neural Information Processing Systems, Vol.1, pp. 568-576, 2014.
- [7] C. Feichtenhofer, A. Pinz, and A. Zisserman, “Convolutional two-stream network fusion for video action recognition,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 1933-1941, 2016. https://doi.org/10.1109/CVPR.2016.213
- [8] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3D convolutional networks,” 2015 IEEE Int. Conf. on Computer Vision, pp. 4489-4497, 2015. https://doi.org/10.1109/ICCV.2015.510
- [9] Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3D residual networks,” 2017 IEEE Int. Conf. on Computer Vision, pp. 5534-5542, 2017. https://doi.org/10.1109/ICCV.2017.590
- [10] J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the Kinetics dataset,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition, pp. 4724-4733, 2017. https://doi.org/10.1109/CVPR.2017.502
- [11] F. N. Iandola et al., “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size,” arXiv:1602.07360, 2016. https://doi.org/10.48550/arXiv.1602.07360
- [12] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical guidelines for efficient CNN architecture design,” Proc. of the 15th European Conf. on Computer Vision, Part 14, pp. 122-138, 2018. https://doi.org/10.1007/978-3-030-01264-9_8
- [13] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 4510-4520, 2018. https://doi.org/10.1109/CVPR.2018.00474
- [14] P. Wang, L. Li, F. Pan, and L. Wang, “Lightweight bilateral network for real-time semantic segmentation,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.4, pp. 673-682, 2023. https://doi.org/10.20965/jaciii.2023.p0673
- [15] Z. Du, Y. Jin, H. Ma, and P. Liu, “A lightweight and accurate method for detecting traffic flow in real time,” J. Adv. Comput. Intell. Intell. Inform., Vol.27, No.6, pp. 1086-1095, 2023. https://doi.org/10.20965/jaciii.2023.p1086
- [16] Y. Li et al., “TEA: Temporal excitation and aggregation for action recognition,” 2020 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 906-915, 2020. https://doi.org/10.1109/CVPR42600.2020.00099
- [17] C. Gu et al., “AVA: A video dataset of spatio-temporally localized atomic visual actions,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 6047-6056, 2018. https://doi.org/10.1109/CVPR.2018.00633
- [18] K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A dataset of 101 human actions classes from videos in the wild,” arXiv:1212.0402, 2012. https://doi.org/10.48550/arXiv.1212.0402
- [19] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” Proc. of the 32nd Int. Conf. on Machine Learning, pp. 448-456, 2015.
- [20] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?,” arXiv:2102.05095, 2021. https://doi.org/10.48550/arXiv.2102.05095
- [21] D. Chen et al., “LS-VIT: Vision Transformer for action recognition based on long and short-term temporal difference,” Frontiers in Neurorobotics, Vol.18, Article No.1457843, 2024. https://doi.org/10.3389/fnbot.2024.1457843
- [22] O. Köpüklü, N. Kose, A. Gunduz, and G. Rigoll, “Resource efficient 3D convolutional neural networks,” 2019 IEEE/CVF Int. Conf. on Computer Vision Workshop, pp. 1910-1919, 2019. https://doi.org/10.1109/ICCVW.2019.00240
- [23] D. Wei et al., “Efficient dual attention SlowFast networks for video action recognition,” Computer Vision and Image Understanding, Vol.222, Article No.103484, 2022. https://doi.org/10.1016/j.cviu.2022.103484
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.