Research Paper:
Consensus Knowledge-Guided Semantic Enhanced Interaction for Image-Text Retrieval
Hongbin Wang*,**
 , Hui Wang*,**, and Fan Li*,**,†
, Hui Wang*,**, and Fan Li*,**,†
*Faculty of Information Engineering and Automation, Kunming University of Science and Technology
727 Jingmingnan Road, Kunming, Yunnan 650500, China
**Yunnan Key Laboratory of Artificial Intelligence, Kunming University of Science and Technology
727 Jingmingnan Road, Kunming, Yunnan 650500, China
†Corresponding author

Image–text retrieval, as a fundamental task in the cross-modal domain, centers on exploring semantic consistency and achieving precise alignment between related image–text pairs. Existing approaches primarily depend on co-occurrence frequency to construct coherent representations of commonsense knowledge introduction patterns, thereby facilitating high-quality semantic alignment across the two modalities. However, these methods often overlook the conceptual and syntactic correspondences between cross-modal fragments. To overcome these limitations, this work proposes a consensus knowledge-guided semantic enhanced interaction method, referred to as CSEI, for image–text retrieval. This method correlates both intra-modal and inter-modal semantics between image regions or objects and sentence words, aiming to minimize cross-modal discrepancies. Specifically, the initial step involves constructing visual and textual corpus sets that encapsulate rich concepts and relationships derived from commonsense knowledge. Subsequently, to enhance intra-modal relationships, a semantic relation-aware graph convolutional network is employed to capture more comprehensive feature representations. For inter-modal similarity reasoning, local and global similarity features are extracted through two cross-modal semantic enhancement mechanisms. In the final stage, the approach integrates commonsense knowledge with internal semantic correlations to enrich concept representation and further optimize semantic consistency by regularizing the importance disparities among association-enhanced concepts. Experiments conducted on MS-COCO and Flickr30K validate the effectiveness of the proposed method.
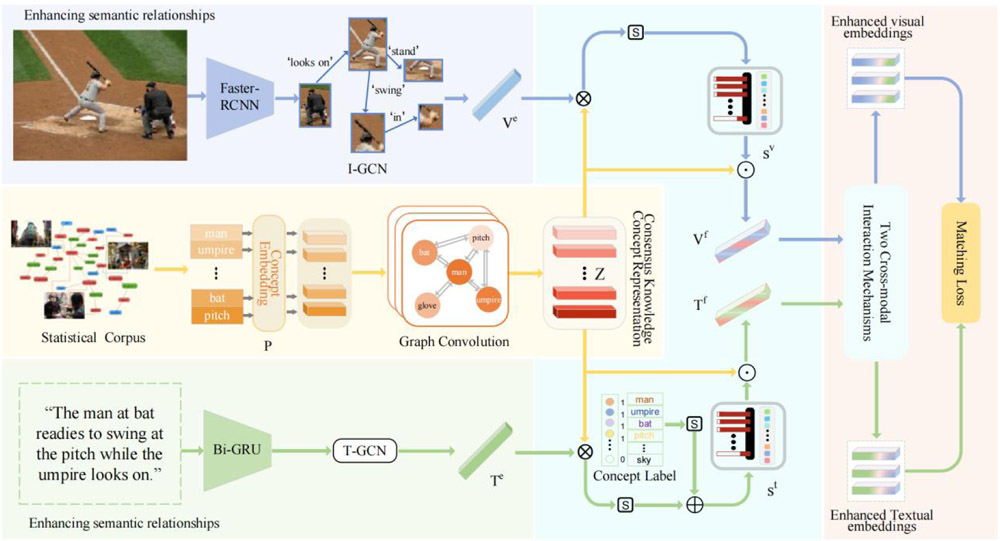
Overall framework of the proposed CSEI
- [1] D. M. Vo, H. Chen, A. Sugimoto, and H. Nakayama, “Noc-rek: novel object captioning with retrieved vocabulary from external knowledge,” 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 17979-17987, 2022. https://doi.org/10.1109/CVPR52688.2022.01747
- [2] T. Yao, Y. Pan, Y. Li, and T. Mei, “Exploring visual relationship for image captioning,” Proc. of the European Conf. on Computer Vision (ECCV), pp. 684-699, 2018. https://doi.org/10.1007/978-3-030-01264-9_42
- [3] Y. Ding, J. Yu, B. Liu, Y. Hu, M. Cui, and Q. Wu, “Mukea: Multimodal knowledge extraction and accumulation for knowledge-based visual question answering,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 5089-5098, 2022. https://doi.org/10.1109/CVPR52688.2022.00503
- [4] H. Jiang, I. Misra, M. Rohrbach, E. Learned-Miller, and X. Chen, “In defense of grid features for visual question answering,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 10267-10276, 2020.
- [5] J. Gu, H. Zhao, Z. Lin, S. Li, J. Cai, and M. Ling, “Scene graph generation with external knowledge and image reconstruction,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 1969-1978, 2019. https://doi.org/10.1109/CVPR.2019.00207
- [6] M.-K. Wang, M. Meng, J. Liu, and J. Wu, “Learning adequate alignment and interaction for cross-modal retrieval,” Virtual Reality & Intelligent Hardware, Vol.5, No.6, pp. 509-522, 2023. https://doi.org/10.1016/j.vrih.2023.06.003
- [7] F. Faghri, D. J. Fleet, J. R. Kiros, and S. Fidler, “Vse++: Improving visual-semantic embeddings with hard negatives,” British Machine Vision Conf., 2017.
- [8] H. Chen, G. Ding, X. Liu, Z. Lin, J. Liu, and J. Han, “IMRAM: Iterative matching with recurrent attention memory for cross-modal image-text retrieval,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 12655-12663, 2020. https://doi.org/10.1109/CVPR42600.2020.01267
- [9] K.-H. Lee, X. Chen, G. Hua, H. Hu, and X. He, “Stacked cross attention for image-text matching,” Proc. of the European Conf. on Computer Vision (ECCV), pp. 201-216, 2018.
- [10] C. Liu, Z. Mao, T. Zhang, H. Xie, B. Wang, and Y. Zhang, “Graph structured network for image-text matching,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 10921-10930, 2020.
- [11] S. Wang, R. Wang, Z. Yao, S. Shan, and X. Chen, “Cross-modal scene graph matching for relationship-aware image-text retrieval,” Proc. of the IEEE/CVF Winter Conf. on Applications of Computer Vision, pp. 1508-1517, 2020.
- [12] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” 13th European Conf. on Computer Vision (ECCV 2014), pp. 740-755, 2014. https://doi.org/10.1007/978-3-319-10602-1_48
- [13] B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hockenmaier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” Proc. of the IEEE Int. Conf. on Computer Vision, pp. 2641-2649, 2015. https://doi.org/10.1109/ICCV.2015.303
- [14] K. Marino, R. Salakhutdinov, and A. Gupta, “The more you know: Using knowledge graphs for image classification,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 20-28, 2017.
- [15] J. Deng, N. Ding, Y. Jia, A. Frome, K. Murphy, S. Bengio, Y. Li, H. Neven, and H. Adam, “Large-scale object classification using label relation graphs,” 13th European Conf. on Computer Vision (ECCV 2014), pp. 48-64, 2014. https://doi.org/10.1007/978-3-319-10590-1_4
- [16] C.-W. Lee, W. Fang, C.-K. Yeh, and Y.-C. F. Wang, “Multi-label zero-shot learning with structured knowledge graphs,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 1576-1585, 2018.
- [17] H. Zhou, T. Young, M. Huang, H. Zhao, J. Xu, and X. Zhu, “Commonsense knowledge aware conversation generation with graph attention,” Proc. of the 27th Int. Joint Conf. on Artificial Intelligence (IJCAI 2018), pp. 4623-4629, 2018. https://doi.org/10.24963/ijcai.2018/643
- [18] B. Wang, L. Ma, W. Zhang, and W. Liu, “Reconstruction network for video captioning,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 7622-7631, 2018. https://doi.org/10.1109/CVPR.2018.00795
- [19] R. Kiros, R. Salakhutdinov, and R. S. Zemel, “Unifying visual-semantic embeddings with multimodal neural language models,” arXiv:1411.2539, 2014. https://doi.org/10.48550/arXiv.1411.2539
- [20] J. Mao, W. Xu, Y. Yang, J. Wang, Z. Huang, and A. Yuille, “Deep captioning with multimodal recurrent neural networks (m-rnn),” Int. Conf. on Learning Representations (ICLR), 2015.
- [21] A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” 2015 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 3128-3137, 2014. https://doi.org/10.1109/CVPR.2015.7298932
- [22] F. Shang, H. Zhang, J. Sun, L. Liu, and H. Zeng, “A cross-media retrieval algorithm based on consistency preserving of collaborative representation,” J. Adv. Comput. Intell. Intell. Inform., Vol.22, No.2, pp. 280-289, 2018. https://doi.org/10.20965/jaciii.2018.p0280
- [23] Y. Qi and H. Zhang, “Joint graph regularization in a homogeneous subspace for cross-media retrieval,” J. Adv. Comput. Intell. Intell. Inform., Vol.23, No.5, pp. 939-946, 2019. https://doi.org/10.20965/jaciii.2019.p0939
- [24] W. Li, S. Yang, Q. Li, X. Li, and A.-A. Liu, “Commonsense-guided semantic and relational consistencies for image-text retrieval,” IEEE Trans. on Multimedia, Vol.26, pp. 1867-1880, 2023. https://doi.org/10.1109/TMM.2023.3289753
- [25] J. Wehrmann, D. M. Souza, M. A. Lopes, and R. C. Barros, “Language-agnostic visual-semantic embeddings,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision, pp. 5804-5813, 2019. https://doi.org/10.1109/ICCV.2019.00590
- [26] Q. Zhang, Z. Lei, Z. Zhang, and S. Z. Li, “Context-aware attention network for image-text retrieval,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 3536-3545, 2020. https://doi.org/10.1109/CVPR42600.2020.00359
- [27] W. Li, Y. Wang, Y. Su, X. Li, A.-A. Liu, and Y. Zhang, “Multi-scale fine-grained alignments for image and sentence matching,” IEEE Trans. on Multimedia, Vol.25, pp. 543-556, 2021. https://doi.org/10.1109/TMM.2021.3128744
- [28] Z. Ji, K. Chen, and H. Wang, “Step-wise hierarchical alignment network for image-text matching,” Z. Zhou (Ed.), Proc. Int. Joint Conf. Artif. Intell., pp. 765-771, 2021. https://doi.org/10.24963/ijcai.2021/106
- [29] K. Li, Y. Zhang, K. Li, Y. Li, and Y. Fu, “Visual semantic reasoning for image-text matching,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision, pp. 4654-4662, 2019. https://doi.org/10.1109/ICCV.2019.00475
- [30] B. Shi, L. Ji, P. Lu, Z. Niu, and N. Duan, “Knowledge aware semantic concept expansion for image-text matching,” Proc. of the 28th Int. Joint Conf. on Artificial Intelligence (IJCAI-19), pp. 5182-5189, 2019. https://doi.org/10.24963/ijcai.2019/720
- [31] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE Trans. on Neural Networks and Learning Systems, Vol.32, No.1, pp. 4-24, 2020. https://doi.org/10.1109/TNNLS.2020.2978386
- [32] H. Wang, Y. Zhang, Z. Ji, Y. Pang, and L. Ma, “Consensus-aware visual-semantic embedding for image-text matching,” 16th European Conf. on Computer Vision (ECCV 2020), pp. 18-34, 2020. https://doi.org/10.1007/978-3-030-58586-0_2
- [33] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 6077-6086, 2018. https://doi.org/10.1109/CVPR.2018.00636
- [34] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.39, No.6, pp. 1137-1149, 2016. https://doi.org/10.1109/TPAMI.2016.2577031
- [35] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [36] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural networks,” IEEE Trans. on Signal Processing, Vol.45, No.11, pp. 2673-2681, 1997. https://doi.org/10.1109/78.650093
- [37] Y Huang, Q. Wu, C. Song, and L. Wang, “Learning semantic concepts and order for image and sentence matching,” 2018 IEEE/CVF Conf. on Computer Vision and Pattern Recognition, pp. 6163-6171, 2018. https://doi.org/10.1109/CVPR.2018.00645
- [38] J. Hou, X. Wu, W. Zhao, J. Luo, and Y. Jia, “Joint syntax representation learning and visual cue translation for video captioning,” 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 8917-8926, 2019. https://doi.org/10.1109/ICCV.2019.00901
- [39] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” Proc. of the 2014 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532-1543, 2014. https://dx.doi.org/10.3115/v1/d14-1162
- [40] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun, “Spectral networks and locally connected networks on graphs,” arXiv:1312.6203, 2013. https://doi.org/10.48550/arXiv.1312.6203
- [41] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” Int. Conf. on Learning Representations (ICLR), 2016.
- [42] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, Vol.60, Issue 6, pp. 84-90, 2012. https://doi.org/10.1145/3065386
- [43] Y. Cheng, X. Zhu, J. Qian, F. Wen, and P. Liu, “Cross-modal graph matching network for image-text retrieval,” ACM Trans. on Multimedia Computing, Communications, and Applications (TOMM), Vol.18, Issue 4, Article No.95, 2022. https://doi.org/10.1145/3499027
- [44] H. Nam, J.-W. Ha, and J. Kim, “Dual attention networks for multimodal reasoning and matching,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 2156-2164, 2017.
- [45] S. Wang, R. Wang, Z. Yao, S. Shan, and X. Chen, “Cross-modal scene graph matching for relationship-aware image-text retrieval,” 2020 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 1497-1506, 2020. https://doi.org/10.1109/WACV45572.2020.9093614
- [46] K. Li, Y. Zhang, K. Li, Y. Li, and Y. Fu, “Image-text embedding learning via visual and textual semantic reasoning,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.45, No.1, pp. 641-656, 2023. https://doi.org/10.1109/tpami.2022.3148470
- [47] T. Luong, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” arXiv:1508.04025v5, 2015. https://doi.org/10.48550/arXiv.1508.04025
- [48] A. Vaswani, N. M. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” Neural Information Processing Systems, 2017.
- [49] J. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv:1607.06450, 2016. https://doi.org/10.48550/arXiv.1607.06450
- [50] J. Wu, C. Wu, J. Lu, L. Wang, and X. Cui, “Region reinforcement network with topic constraint for image-text matching,” IEEE Trans. on Circuits and Systems for Video Technology, Vol.32, No.1, pp. 388-397, 2022. https://doi.org/10.1109/TCSVT.2021.3060713
- [51] Z. Wang, X. Liu, H. Li, L. Sheng, J. Yan, X. Wang, and J. Shao, “CAMP: Cross-modal adaptive message passing for text-image retrieval,” 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 5763-5772, 2019.
- [52] H. Sun, X. Qin, and X. Liu, “Flexible graph-based attention and pooling network for image-text retrieval,” Multimedia Tools and Applications, Vol.83, No.19, pp. 57895-57912, 2024. https://doi.org/10.1007/s11042-023-17798-1
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.