Research Paper:
Effective Action Learning Method Using Information Entropy for a Single Robot Under Multi-Agent Control
Yuma Uemura, Riku Narita, and Kentarou Kurashige

Muroran Institute Technology
27-1 Mizumoto-cho, Muroran, Hokkaido 050-8585, Japan

Robots that learn to perform actions using reinforcement learning to should be able to learn not only static environments, but also environmental changes. Heterogeneous multi-agent reinforcement learning (HMARL) was developed to perform an efficient search, with multiple agents mounted on a single robot to achieve tasks quickly. Responding to environmental changes using normal reinforcement learning can be challenging. However, HMARL does not consider the use of multiple agents to address environmental changes. In this study, we filtered the agents in HMARL using information entropy to realize a robot capable of maintaining high task achievement rates in response to environmental changes.
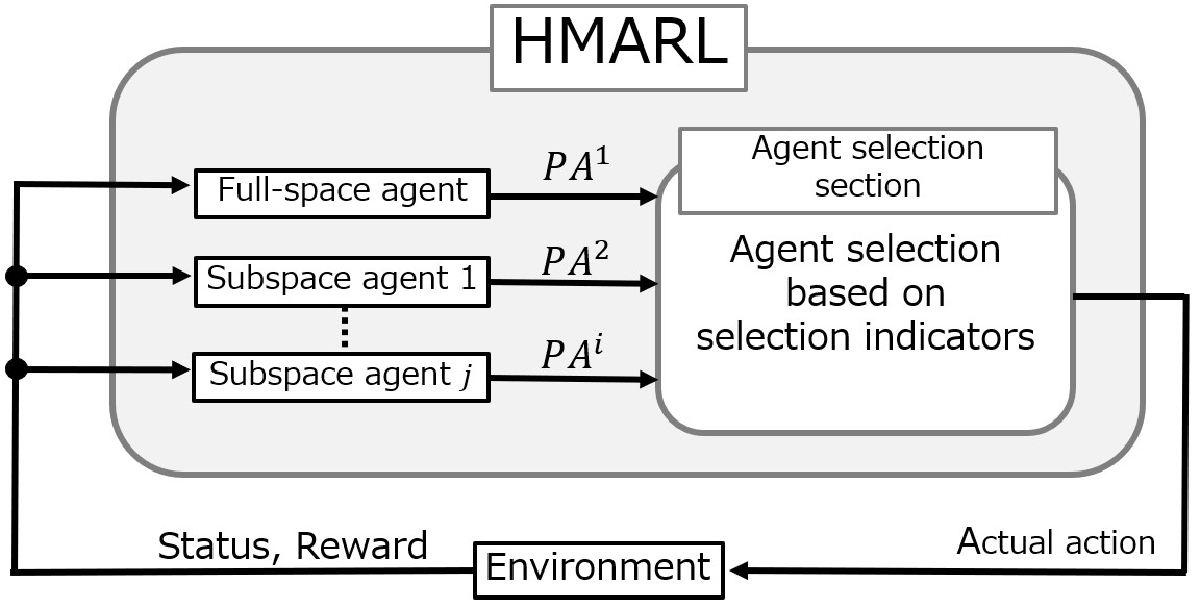
Conceptual diagram of HMARL
- [1] T. Hashimoto, X. Tao, T. Suzuki, T. Kurose, Y. Nishikawa, and Y. Kagawa, “Decision Making of Communication Robots Through Robot Ethics,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.4, pp. 467-477, 2021. https://doi.org/10.20965/jaciii.2021.p0467
- [2] Y. Yamazaki, M. Ishii, T. Ito, and T. Hashimoto, “Frailty Care Robot for Elderly and its Application for Physical and Psychological Support,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.6, pp. 944-952, 2021. https://doi.org/10.20965/jaciii.2021.p0944
- [3] H. Zhang, Y. Wang, J. Zheng, and J. Yu, “Path planning of industrial robot based on improved RRT algorithm in complex environments,” IEEE Access, Vol.6, pp. 53296-53306, 2018. https://doi.org/10.1109/ACCESS.2018.2871222
- [4] D. Kragic, J. Gustafson, H. Karaoguz, P. Jensfelt, and R. Krug, “Interactive, Collaborative Robots: Challenges and Opportunities,” Proc. of the 27th Int. Joint Conf. on Artificial Intelligence (IJCAI), pp. 18-25, 2018. https://doi.org/10.24963/ijcai.2018/3
- [5] K.N. McGuire, C. De Wagter, K. Tuyls, H. J. Kappen, and G. C. H. E. de Croon, “Minimal navigation solution for a swarm of tiny flying robots to explore an unknown environment,” Science Robotics, Vol.4, No.35, 2019. https://doi.org/10.1126/scirobotics.aaw9710
- [6] Y. Tsurumine, Y. Cui, E. Uchibe, and T. Matsubara, “Deep reinforcement learning with smooth policy update: Application to robotic cloth manipulation,” Robotics and Autonomous Systems, Vol.112, pp. 72-83, 2019. https://doi.org/10.1016/j.robot.2018.11.004
- [7] F. Niroui, K. Zhang, Z. Kashino, and G. Nejat, “Deep reinforcement learning robot for search and rescue applications: Exploration in unknown cluttered environments,” IEEE Robotics and Automation Letters, Vol.4, No.2, pp. 610-617, 2019. https://doi.org/10.1109/LRA.2019.2891991
- [8] K. Rao, C. Harris, A. Irpan, S. Levine, J. Ibarz, and M. Khansari, “RL-CycleGAN: Reinforcement learning aware simulation-to-real,” 2020 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 11154-11163, 2020. https://doi.org/10.1109/CVPR42600.2020.01117
- [9] H. X. Pham, H. M. La, D. Feil-Seifer, and L. Van Nguyen, “Reinforcement learning for autonomous UAV navigation using function approximation,” 2018 IEEE Int. Symp. on Safety, Security, and Rescue Robotics (SSRR), 2018. https://doi.org/10.1109/SSRR.2018.8468611
- [10] Y. Tang, M. Chen, C. Wang, L. Luo, J. Li, G. Lian, and X. Zou, “Recognition and localization methods for vision-based fruit picking robots: A review,” Frontiers in Plant Science, Vol.11, 2020. https://doi.org/10.3389/fpls.2020.00510
- [11] M. E. Taylor and P. Stone, “Transfer learning for reinforcement learning domains: A survey,” J. of Machine Learning Research, Vol.10, pp. 1633-1685, 2009.
- [12] F. Zhuang, Z. Qi, K. Duan, D. Xi, Y. Zhu, H. Zhu, H. Xiong, and Q. He, “A comprehensive survey on transfer learning,” Proc. of the IEEE, Vol.109, No.1, pp. 43-76, 2020. https://doi.org/10.1109/JPROC.2020.3004555
- [13] R. Narita, T. Matsushima, and K. Kurashige, “Efficient exploration by switching agents according to degree of convergence of learning on heterogeneous multi-agent reinforcement learning in single robot,” 2021 IEEE Symp. Series on Computational Intelligence (SSCI), 2021. https://doi.org/10.1109/SSCI50451.2021.9659982
- [14] S. Iqbal and F. Sha, “Actor-attention-critic for multi-agent reinforcement learning,” Proc. of the 36th Int. Conf. on Machine Learning (PMLR), Vol.97, pp. 2961-2970, 2019.
- [15] L. Liang, H. Ye, and Y. L. Geoffrey, “Spectrum sharing in vehicular networks based on multi-agent reinforcement learning,” IEEE J. on Selected Areas in Communications, Vol.37, No.10, pp. 2282-2292, 2019. https://doi.org/10.1109/JSAC.2019.2933962
- [16] Y. Rizk, M. Awad, and E. W. Tunstel, “Cooperative heterogeneous multi-robot systems: A survey,” ACM Computing Surveys, Vol.52, No.2, Article No.29, 2019. https://doi.org/10.1145/3303848
- [17] Y. Yang, H. Modares, D. C. Wunsch, and Y. Yin, “Leader–follower output synchronization of linear heterogeneous systems with active leader using reinforcement learning,” IEEE Trans. on Neural Networks and Learning Systems, Vol.29, No.6, pp. 2139-2153, 2018. https://doi.org/10.1109/TNNLS.2018.2803059
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.