Research Paper:
Layer Configurations of BERT for Multitask Learning and Data Augmentation
Niraj Pahari†
 and Kazutaka Shimada
and Kazutaka Shimada
Kyushu Institute of Technology
680-4 Kawazu, Iizuka, Fukuoka 820-8502, Japan
†Corresponding author

Multitask learning (MTL) and data augmentation are becoming increasingly popular in natural language processing (NLP). These techniques are particularly useful when data are scarce. In MTL, knowledge learned from one task is applied to another. To address data scarcity, data augmentation facilitates by providing additional synthetic data during model training. In NLP, the bidirectional encoder representations from transformers (BERT) model is the default candidate for various tasks. MTL and data augmentation using BERT have yielded promising results. However, a detailed study regarding the effect of using MTL in different layers of BERT and the benefit of data augmentation in these configurations has not been conducted. In this study, we investigate the use of MTL and data augmentation from generative models, specifically for category classification, sentiment classification, and aspect-opinion sequence-labeling using BERT. The layers of BERT are categorized into top, middle, and bottom layers, which are frozen, shared, or unshared. Experiments are conducted to identify the optimal layer configuration for improved performance compared with that of single-task learning. Generative models are used to generate augmented data, and experiments are performed to reveal their effectiveness. The results indicate the effectiveness of the MTL configuration compared with single-task learning as well as the effectiveness of data augmentation using generative models for classification tasks.
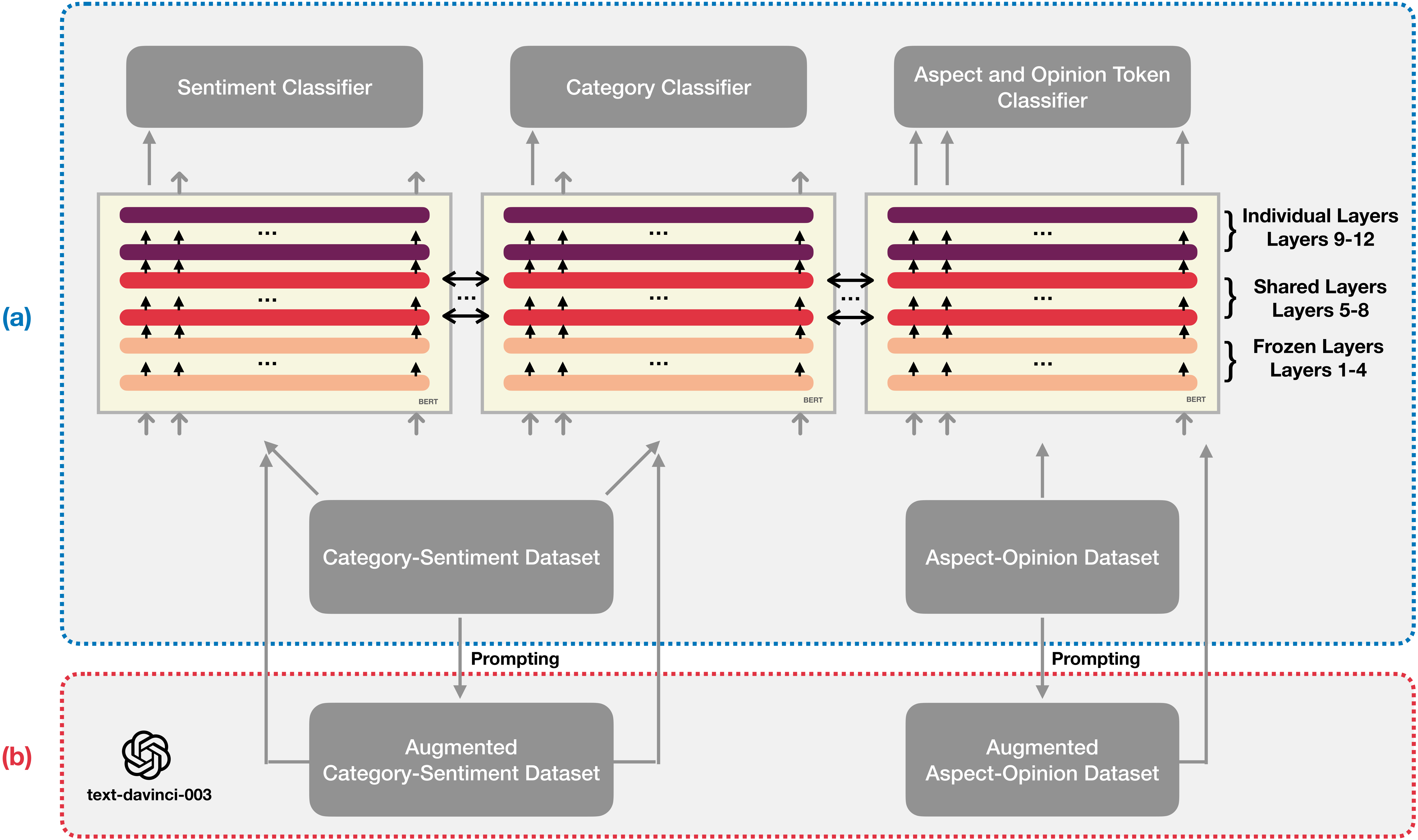
Proposed multitask learning model with augmented data
- [1] S. Vandenhende, S. Georgoulis, M. Proesmans, D. Dai, and L. Van Gool, “Revisiting multi-task learning in the deep learning era,” arXiv:2004.13379, 2020. https://doi.org/10.1109/tpami.2021.3054719
- [2] Y. Zhang and Q. Yang, “A survey on multi-task learning,” IEEE Trans. on Knowledge and Data Engineering, Vol.34, No.12, pp. 5586-5609, 2022. https://doi.org/10.1109/TKDE.2021.3070203
- [3] R. Caruana, “Multitask Learning,” Machine Learning, Vol.28, No.1, pp. 41-75, 1997. https://doi.org/10.1023/A:1007379606734
- [4] E. Choi, D. Hewlett, J. Uszkoreit, I. Polosukhin, A. Lacoste, and J. Berant, “Coarse-to-Fine Question Answering for Long Documents,” Proc. of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 209-220, 2017. https://doi.org/10.18653/v1/P17-1020
- [5] A. Wilson, A. Fern, S. Ray, and P. Tadepalli, “Multi-task reinforcement learning: A hierarchical Bayesian approach,” Proc. of the 24th Int. Conf. on Machine Learning, ser. ICML’07, pp. 1015-1022, 2007. https://doi.org/10.1145/1273496.1273624
- [6] Y. Zhang and Q. Yang, “An overview of multi-task learning,” National Science Review, Vol.5, No.1, pp. 30-43, 2018. https://doi.org/10.1093/nsr/nwx105
- [7] S. Ruder, “An Overview of Multi-Task Learning in Deep Neural Networks,” 2017. https://doi.org/10.48550/arXiv.1706.05098.
- [8] S. Changpinyo, H. Hu, and F. Sha, “Multi-Task Learning for Sequence Tagging: An Empirical Study,” Proc. of the 27th Int. Conf. on Computational Linguistics, pp. 2965-2977, 2018.
- [9] J. Xu, X. Ren, J. Lin, and X. Sun, “Diversity-Promoting GAN: A Cross-Entropy Based Generative Adversarial Network for Diversified Text Generation,” Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing, pp. 3940-3949, 2018. https://doi.org/10.18653/v1/D18-1428
- [10] R. Gupta, “Data Augmentation for Low Resource Sentiment Analysis Using Generative Adversarial Networks,” 2019 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), pp. 7380-7384, 2019. https://doi.org/10.1109/ICASSP.2019.8682544
- [11] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,” ACM Computing Surveys, Vol.55, No.9, Article No.195, 2023. https://doi.org/10.1145/3560815
- [12] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [13] R. Satapathy, S. R. Pardeshi, and E. Cambria, “Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding,” Future Internet, Vol.14, No.7, Article No.191, 2022. https://doi.org/10.3390/fi14070191
- [14] K. Clark, U. Khandelwal, O. Levy, and C. D. Manning, “What Does BERT Look at? An Analysis of BERT’s Attention,” Proc. of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 276-286, 2019. https://doi.org/10.18653/v1/W19-4828
- [15] W. Dai, T. Yu, Z. Liu, and P. Fung, “Kungfupanda at SemEval-2020 Task 12: BERT-Based Multi-Task Learning for Offensive Language Detection,” Proc. of the 14th Workshop on Semantic Evaluation, pp. 2060-2066, 2020. https://doi.org/10.18653/v1/2020.semeval-1.272
- [16] Q. Jia, J. Cui, Y. Xiao, C. Liu, M. P. Rashid, and D. Gehringer, “ALL-IN-ONE: Multi-Task Learning BERT models for Evaluating Peer Assessments,” arXiv:2110.03895, 2021. https://doi.org/10.48550/arXiv.2110.03895
- [17] C. Si, Z. Zhang, F. Qi, Z. Liu, Y. Wang, Q. Liu, and M. Sun, “Better Robustness by More Coverage: Adversarial and Mixup Data Augmentation for Robust Finetuning,” Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 1569-1576, 2021, https://doi.org/10.18653/v1/2021.findings-acl.137
- [18] R. Collobert and J. Weston, “A unified architecture for natural language processing: Deep neural networks with multitask learning,” Proc. of the 25th Int. Conf. on Machine Learning, ser. ICML’08, pp. 160-167, 2008. https://doi.org/10.1145/1390156.1390177
- [19] G. Balikas, S. Moura, and M.-R. Amini, “Multitask Learning for Fine-Grained Twitter Sentiment Analysis,” Proc. of the 40th Int. ACM SIGIR Conf. on Research and Development in Information Retrieval, ser. SIGIR’17, pp. 1005-1008, 2017. https://doi.org/10.1145/3077136.3080702
- [20] X. Liu, P. He, W. Chen, and J. Gao, “Multi-Task Deep Neural Networks for Natural Language Understanding,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4487-4496, 2019. https://doi.org/10.18653/v1/P19-1441
- [21] Y. Peng, Q. Chen, and Z. Lu, “An Empirical Study of Multi-Task Learning on BERT for Biomedical Text Mining,” Proc. of the 19th SIGBioMed Workshop on Biomedical Language Processing, pp. 205-214, 2020. https://doi.org/10.18653/v1/2020.bionlp-1.22
- [22] I. Tenney, D. Das, and E. Pavlick, “BERT Rediscovers the Classical NLP Pipeline,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4593-4601, 2019. https://doi.org/10.18653/v1/P19-1452
- [23] J. Vig and Y. Belinkov, “Analyzing the Structure of Attention in a Transformer Language Model,” Proc. of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 63-76, 2019. https://doi.org/10.18653/v1/W19-4808
- [24] B. Hoover, H. Strobelt, and S. Gehrmann, “exBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 187-196, 2020. https://doi.org/10.18653/v1/2020.acl-demos.22
- [25] S. Kobayashi, “Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations,” Proc. of the 2018 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pp. 452-457, 2018. https://doi.org/10.18653/v1/N18-2072
- [26] J. Wei and K. Zou, “EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks,” Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), pp. 6382-6388, 2019. https://doi.org/10.18653/v1/D19-1670
- [27] A. Anaby-Tavor, B. Carmeli, E. Goldbraich, A. Kantor, G. Kour, S. Shlomov, N. Tepper, and N. Zwerdling, “Do Not Have Enough Data? Deep Learning to the Rescue!” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.05, pp. 7383-7390, 2020. https://doi.org/10.1609/aaai.v34i05.6233
- [28] A. Radford and K. Narasimhan, “Improving Language Understanding by Generative Pre-Training,” Preprint, 2018.
- [29] A. Edwards, A. Ushio, J. Camacho-collados, H. Ribaupierre, and A. Preece, “Guiding Generative Language Models for Data Augmentation in Few-Shot Text Classification,” Proc. of the 4th Workshop on Data Science with Human-in-the-Loop (Language Advances), pp. 51-63, 2022.
- [30] H. Cai, R. Xia, and J. Yu, “Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions,” Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (Volume 1: Long Papers), pp. 340-350, 2021. https://doi.org/10.18653/v1/2021.acl-long.29
- [31] M. Pontiki, D. Galanis, H. Papageorgiou, I. Androutsopoulos, S. Manandhar, M. AL-Smadi, M. Al-Ayyoub, Y. Zhao, B. Qin, O. De Clercq, V. Hoste, M. Apidianaki, X. Tannier, N. Loukachevitch, E. Kotelnikov, N. Bel, S. M. Jiménez-Zafra, and G. Eryiğit, “SemEval-2016 Task 5: Aspect Based Sentiment Analysis,” Proc. of the 10th Int. Workshop on Semantic Evaluation (SemEval-2016), pp. 19-30, 2016. https://doi.org/10.18653/v1/S16-1002
- [32] Z. Fan, Z. Wu, X.-Y. Dai, S. Huang, and J. Chen, “Target-Oriented Opinion Words Extraction with Target-Fused Neural Sequence Labeling,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 2509-2518, 2019. https://doi.org/10.18653/v1/N19-1259
- [33] L. Xu, H. Li, W. Lu, and L. Bing, “Position-Aware Tagging for Aspect Sentiment Triplet Extraction,” Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), pp. 2339-2349, 2020. https://doi.org/10.18653/v1/2020.emnlp-main.183
- [34] N. Pahari and K. Shimada, “Multi-Task Learning Using BERT With Soft Parameter Sharing Between Layers,” 2022 Joint 12th Int. Conf. on Soft Computing and Intelligent Systems and 23rd Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2022. https://doi.org/10.1109/SCISISIS55246.2022.10001943
- [35] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is All You Need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [36] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language Models are Few-Shot Learners,” Advances in Neural Information Processing Systems, Vol.33, pp. 1877-1901, 2020.
- [37] T. Gao, “Prompting: Better Ways of Using Language Models for NLP Tasks.” https://thegradient.pub/prompting/ [Accessed April 23, 2023]
- [38] H. Dai, Z. Liu, W. Liao, X. Huang, Y. Cao, Z. Wu, L. Zhao, S. Xu, W. Liu, N. Liu, S. Li, D. Zhu, H. Cai, L. Sun, Q. Li, D. Shen, T. Liu, and X. Li, “Auggpt: Leveraging chatgpt for text data augmentation,” arXiv:2302.13007, 2023. https://doi.org/10.48550/arXiv.2302.13007
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.