Research Paper:
An Object Detection Method Using Probability Maps for Instance Segmentation to Mask Background
Shinji Uchinoura, Junichi Miyao, and Takio Kurita
Hiroshima University
1-4-1 Kagamiyama, Higashi-Hiroshima-shi, Hiroshima 739-8527, Japan

This paper proposes a two-step detector called segmented object detection, whose performance is improved by masking the background region. Previous single-stage object detection methods suffer from the problem of imbalance between foreground and background classes, where the background occupies more regions in the image than the foreground. Thus, the loss from the background is firmly incorporated into the training. RetinaNet addresses this problem with Focal Loss, which focuses on foreground loss. Therefore, we propose a method that generates probability maps using instance segmentation in the first step and feeds back the generated maps as background masks in the second step as prior knowledge to reduce the influence of the background and enhance foreground training. We confirm that the detector can improve the accuracy by adding instance segmentation information to both the input and output rather than only to the output results. On the Cityscapes dataset, our method outperforms the state-of-the-art methods.
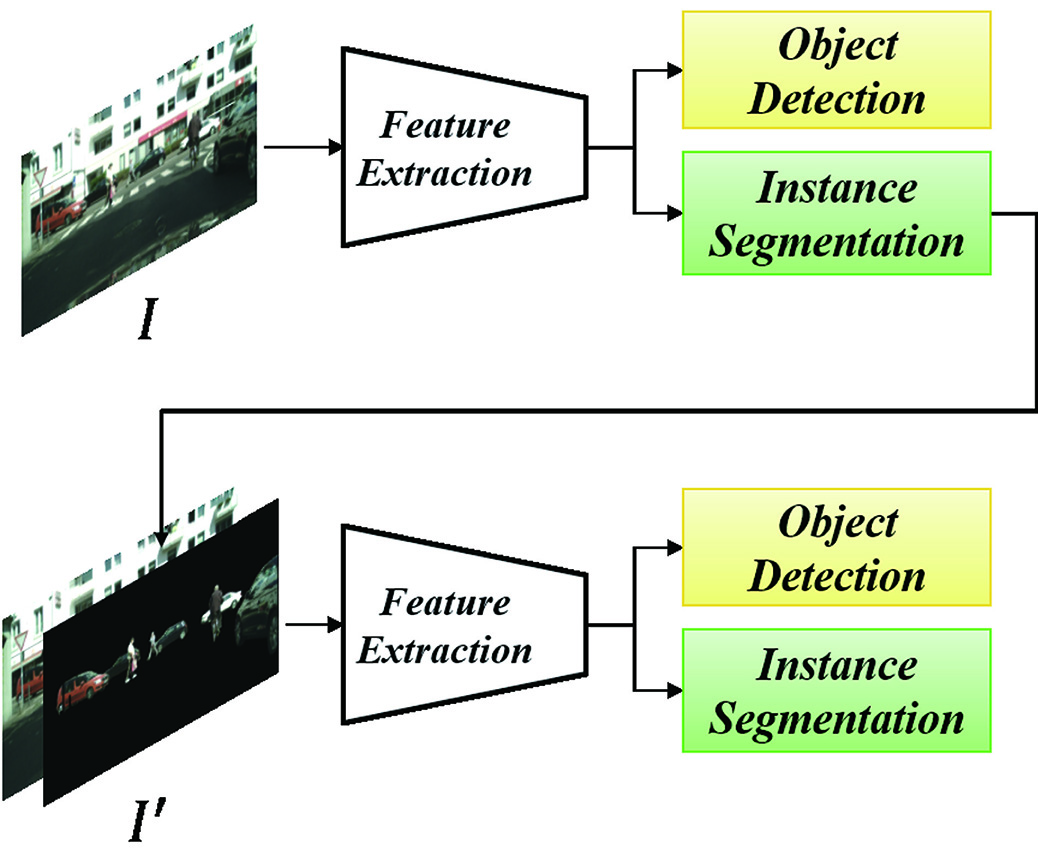
Overview of the proposed method
- [1] S. Ren, K. He, R. Girshick, and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.39, No.6, pp. 1137-1149, 2016. https://doi.org/10.1109/TPAMI.2016.2577031
- [2] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” Proc. of 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 779-788, 2016. https://doi.org/10.1109/CVPR.2016.91
- [3] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” European Conf. on Computer Vision (ECCV2016), pp. 21-37, 2016. https://doi.org/10.1007/978-3-319-46448-0_2
- [4] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” Proc. of 2014 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 580-587, 2014. https://doi.org/10.1109/CVPR.2014.81
- [5] R. Girshick, “Fast R-CNN,” Proc. of 2015 IEEE Int. Conf. on Computer Vision (ICCV), pp. 1440-1448, 2015. https://doi.org/10.1109/ICCV.2015.169
- [6] Z. Cai and N. Vasconcelos, “Cascade R-CNN: Delving into high quality object detection,” Proc. of 2018 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 6154-6162, 2018. https://doi.org/10.1109/CVPR.2018.00644
- [7] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” Proc. of 2017 IEEE Int. Conf. on Computer Vision (ICCV), pp. 2999-3007, 2017. https://doi.org/10.1109/ICCV.2017.324
- [8] Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one-stage object detection,” Proc. of 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 9626-9635, 2019. https://doi.org/10.1109/ICCV.2019.00972
- [9] X. Wang, T. Kong, C. Shen, Y. Jiang, and L. Li, “Solo: Segmenting objects by locations,” European Conf. on Computer Vision (ECCV2020), pp. 649-665, 2020. https://doi.org/10.1007/978-3-030-58523-5_38
- [10] Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” European Conf. on Computer Vision (ECCV2020), pp. 282-298, 2020. https://doi.org/10.1007/978-3-030-58452-8_17
- [11] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” Proc. of 2015 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 3431-3440, 2015. https://doi.org/10.1109/CVPR.2015.7298965
- [12] K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask R-CNN,” Proc. of 2017 IEEE Int. Conf. on Computer Vision (ICCV), pp. 2980-2988, 2017. https://doi.org/10.1109/ICCV.2017.322
- [13] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” Proc. of 2009 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 248-255, 2009. https://doi.org/10.1109/CVPR.2009.5206848
- [14] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: Common objects in context,” European Conf. on Computer Vision (ECCV2014), pp. 740-755, 2014. https://doi.org/10.1007/978-3-319-10602-1_48
- [15] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT: Real-time instance segmentation,” Proc. of 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 9156-9165, 2019. https://doi.org/10.1109/ICCV.2019.00925
- [16] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT++: Better real-time instance segmentation,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.44, No.2, pp. 1108-1121, 2020. https://doi.org/10.1109/TPAMI.2020.3014297
- [17] X. Wang, R. Zhang, T. Kong, L. Li, and C. Shen, “Solov2: Dynamic and fast instance segmentation,” Advances in Neural Information Processing Systems, Vol.33, pp. 17721-17732, 2020.
- [18] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” Proc. of 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 936-944, 2017. https://doi.org/10.1109/CVPR.2017.106
- [19] Y. Lee and J. Park, “CenterMask: Real-time anchor-free instance segmentation,” Proc. of 2020 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 13903-13912, 2020. https://doi.org/10.1109/CVPR42600.2020.01392
- [20] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” Proc. of the IEEE Int. Conf. on Computer Vision (ICCV), pp. 1026-1034, 2015. https://doi.org/10.1109/ICCV.2015.123
- [21] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” Proc. of 2019 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 658-666, 2019. https://doi.org/10.1109/CVPR.2019.00075
- [22] C. H. Sudre, W. Li, T. Vercauteren, S. Ourselin, and M. J. Cardoso, “Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations,” Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA ML-CDS 2017), pp. 240-248, 2017. https://doi.org/10.1007/978-3-319-67558-9_28
- [23] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene understanding,” Proc. of 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 3213-3223, 2016. https://doi.org/10.1109/CVPR.2016.350
- [24] K. Chen, J. Wang, J. Pang et al., “MMDetection: Open MMLab detection toolbox and benchmark,” arXiv:1906.07155, 2019. https://doi.org/10.48550/arXiv.1906.07155
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.