Research Paper:
Effectiveness of Pre-Trained Language Models for the Japanese Winograd Schema Challenge
Keigo Takahashi
 , Teruaki Oka, and Mamoru Komachi
, Teruaki Oka, and Mamoru Komachi
Graduate School of System Design, Tokyo Metropolitan University (TMU)
6-6 Asahigaoka, Hino, Tokyo 191-0065, Japan

This paper compares Japanese and multilingual language models (LMs) in a Japanese pronoun reference resolution task to determine the factors of LMs that contribute to Japanese pronoun resolution. Specifically, we tackle the Japanese Winograd schema challenge task (WSC task), which is a well-known pronoun reference resolution task. The Japanese WSC task requires inter-sentential analysis, which is more challenging to solve than intra-sentential analysis. A previous study evaluated pre-trained multilingual LMs in terms of training language on the target WSC task, including Japanese. However, the study did not perform pre-trained LM-wise evaluations, focusing on the training language-wise evaluations with a multilingual WSC task. Furthermore, it did not investigate the effectiveness of factors (e.g., model size, learning settings in the pre-training phase, or multilingualism) to improve the performance. In our study, we compare the performance of inter-sentential analysis on the Japanese WSC task for several pre-trained LMs, including multilingual ones. Our results confirm that XLM, a pre-trained LM on multiple languages, performs the best among all considered LMs, which we attribute to the amount of data in the pre-training phase.
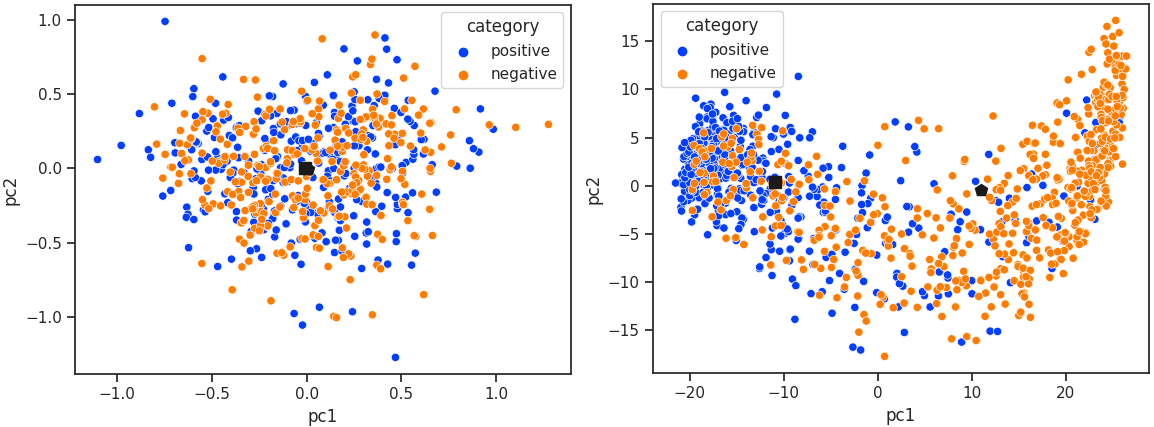
Transition before (left) and after (right) fine-tuning XLM
- [1] R. Iida et al., “Intra-Sentential Subject Zero Anaphora Resolution Using Multi-Column Convolutional Neural Network,” Proc. of the 2016 Conf. on Empirical Methods in Natural Language Processing, pp. 1244-1254, 2016. http://doi.org/10.18653/v1/D16-1132
- [2] R. Sasano and S. Kurohashi, “A Discriminative Approach to Japanese Zero Anaphora Resolution with Large-Scale Lexicalized Case Frames,” Proc. of 5th Int. Joint Conf. on Natural Language Processing, pp. 758-766, 2011.
- [3] H. J. Levesque et al., “The Winograd Schema Challenge,” Proc. of the 13th Int. Conf. on Principles of Knowledge Representation and Reasoning, pp. 552-561, 2012.
- [4] J. Devlin et al., “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 4171-4186, 2019.
- [5] Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv:1907.11692, 2020.
- [6] A. Radford et al., “Improving Language Understanding by Generative Pre-Training,” 2018.
- [7] A. Radford et al., “Language Models are Unsupervised Multitask Learners,” 2019.
- [8] C. Raffelet al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” J. of Machine Learning Research, Vol.21, No.1, pp. 5485-5551, 2020.
- [9] A. Conneau et al., “Unsupervised Cross-Lingual Representation Learning at Scale,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 8440-8451, 2019. http://doi.org/10.18653/v1/2020.acl-main.747
- [10] V. Kocijan et al., “A Surprisingly Robust Trick for the Winograd Schema Challenge,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4837-4842, 2019. http://doi.org/10.18653/v1/P19-1478
- [11] K. Sakaguchi et al., “WinoGrande: An Adversarial Winograd Schema Challenge at Scale,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.5, pp. 8732-8740, 2020. https://doi.org/10.1609/aaai.v34i05.6399
- [12] T. Klein and M. Nabi, “Contrastive Self-Supervised Learning for Commonsense Reasoning,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7517-7523, 2020. http://doi.org/10.18653/v1/2020.acl-main.671
- [13] T. Klein and M. Nabi, “Attention-Based Contrastive Learning for Winograd Schemas,” Findings of the Association for Computational Linguistics: EMNLP 2021, pp. 2428-2434, 2021. http://doi.org/10.18653/v1/2021.findings-emnlp.208
- [14] A. Emami et al., “The KnowRef Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution,” Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 3952-3961, 2019. http://doi.org/10.18653/v1/P19-1386
- [15] P. Trichelair et al., “How Reasonable Are Common-Sense Reasoning Tasks: A Case-Study on the Winograd Schema Challenge and SWAG,” Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), pp. 3382-3387, 2019. http://doi.org/10.18653/v1/D19-1335
- [16] M. Abdou et al., “The Sensitivity of Language Models and Humans to Winograd Schema Perturbations,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7590-7604, 2020. http://doi.org/10.18653/v1/2020.acl-main.679
- [17] H. Zhang et al., “WinoWhy: A Deep Diagnosis of Essential Commonsense Knowledge for Answering Winograd Schema Challenge,” Proc. of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 5736-5745, 2020. http://doi.org/10.18653/v1/2020.acl-main.508
- [18] Z. Yang et al., “XLNet: Generalized Autoregressive Pretraining for Language Understanding,” H. Wallach et al. (Eds.), Advances in Neural Information Processing Systems, Vol.32, Curran Associates, Inc., 2019.
- [19] A. Tikhonov and M. Ryabinin, “It’s All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning,” Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 3534-3546, 2021. http://doi.org/10.18653/v1/2021.findings-acl.310
- [20] A. Rahman and V. Ng, “Resolving Complex Cases of Definite Pronouns: The Winograd Schema Challenge,” Proc. of the 2012 Joint Conf. on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 777-789, 2012.
- [21] A. Wang et al., “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding,” Proc. of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353-355, 2018. http://doi.org/10.18653/v1/W18-5446
- [22] A. Wang et al., “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems,” H. Wallach et al. (Eds.), Advances in Neural Information Processing Systems, Vol.32, Curran Associates, Inc., 2019.
- [23] T. Shibata et al., “Nihongo Winograd Schema Challenge no kouchiku to bunseki,” Proc. of NLP, pp. 493-496, 2015 (in Japanese).
- [24] P. Amsili and O. Seminck, “A Google-Proof Collection of French Winograd Schemas,” Proc. of the 2nd Workshop on Coreference Resolution Beyond OntoNotes (CORBON 2017), pp. 24-29, 2017. http://doi.org/10.18653/v1/W17-1504
- [25] T. Shavrina et al., “RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark,” Proc. of the 2020 Conf. on EMNLP, pp. 4717-4726, 2020. http://doi.org/10.18653/v1/2020.emnlp-main.381
- [26] G. Melo et al., “Winograd Schemas in Portuguese,” Anais do XVI Encontro Nacional de Inteligência Artificial e Computacional, pp. 787-798, 2019. https://doi.org/10.5753/eniac.2019.9334
- [27] T. Bernard and T. Han, “Mandarinograd: A Chinese Collection of Winograd Schemas,” Proc. of the 12th Language Resources and Evaluation Conf., pp. 21-26, 2020.
- [28] J. Opitz and A. Frank, “Addressing the Winograd Schema Challenge as a Sequence Ranking Task,” Proc. of the 1st Int. Workshop on Language Cognition and Computational Models, pp. 41-52, 2018.
- [29] T. H. Trinh and Q. V. Le, “A Simple Method for Commonsense Reasoning,” arXiv:1806.02847, 2019.
- [30] T. Nakamura and D. Kawahara, “JFCKB: Japanese Feature Change Knowledge Base,” Proc. of the 11th Int. Conf. on Language Resources and Evaluation (LREC 2018), 2018.
- [31] O. Vinyals et al., “Pointer Networks,” C. Cortes et al. (Eds.), Advances in Neural Information Processing Systems, Vol.28, Curran Associates, Inc., 2015.
- [32] C. Park et al., “Fast End-to-End Coreference Resolution for Korean,” Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 2610-2624, 2020. http://doi.org/10.18653/v1/2020.findings-emnlp.237
- [33] J. Chung et al., “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling,” arXiv:1412.3555, 2014.
- [34] A. Vaswani et al., “Attention is All You Need,” I. Guyon et al. (Eds.), Advances in Neural Information Processing Systems, Vol.30, Curran Associates, Inc., 2017.
- [35] T. Wolf et al., “Transformers: State-of-the-Art Natural Language Processing,” Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 38-45, 2020. http://doi.org/10.18653/v1/2020.emnlp-demos.6
- [36] T. Kudo, “MeCab : Yet Another Part-of-Speech and Morphological Analyzer.” https://taku910.github.io/mecab/ [Accessed January 23, 2018]
- [37] T. Sato et al., “Implementation of a word segmentation dictionary called MeCab-IPAdic-NEologd and study on how to use it effectively for information retrieval,” Proc. of the 23rd Annual Meeting of the Association for Natural Language Processing, pp. NLP2017-B6-1, 2017 (in Japanese).
- [38] T. Kudo and J. Richardson, “SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing,” Proc. of the 2018 Conf. on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 66-71, 2018. http://doi.org/10.18653/v1/D18-2012
- [39] J. Kaplan et al., “Scaling Laws for Neural Language Models,” arXiv:2001.08361, 2020.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.