Research Paper:
Time Series Self-Attention Approach for Human Motion Forecasting: A Baseline 2D Pose Forecasting
Andi Prademon Yunus
 , Kento Morita, Nobu C. Shirai, and Tetsushi Wakabayashi
, Kento Morita, Nobu C. Shirai, and Tetsushi Wakabayashi
Mie University
1577 Kurimamachiya-cho, Tsu, Mie 514-0102, Japan

Human motion forecasting is a necessary variable to analyze human motion concerning the safety system of the autonomous system that could be used in many applications, such as in auto-driving vehicles, auto-pilot logistics delivery, and gait analysis in the medical field. At the same time, many types of research have been conducted on 3D human motion prediction for short-term and long-term goals. This paper proposes human motion forecasting in the 2D plane as a reliable alternative in motion capture of the RGB camera attached to the devices. We proposed a method, the time series self-attention approach to generate the next future human motion in the short-term of 400 milliseconds and long-term of 1,000 milliseconds, resulting that the model could predict human motion with a slight error of 23.51 pixels for short-term prediction and 10.3 pixels for long-term prediction on average compared to the ground truth in the quantitative and qualitative evaluation. Our method outperformed the LSTM and GRU models on the Human3.6M dataset based on the MPJPE and MPJVE metrics. The average loss of correct key points varied based on the tolerance value. Our method performed better within the 50 pixels tolerance. In addition, our method is tested by images without key point annotations using OpenPose as the pose estimation method. Resulting, our method could predict well the position of the human but could not predict well for the human body pose. This research is a new baseline for the 2D human motion prediction using the Human3.6M dataset.
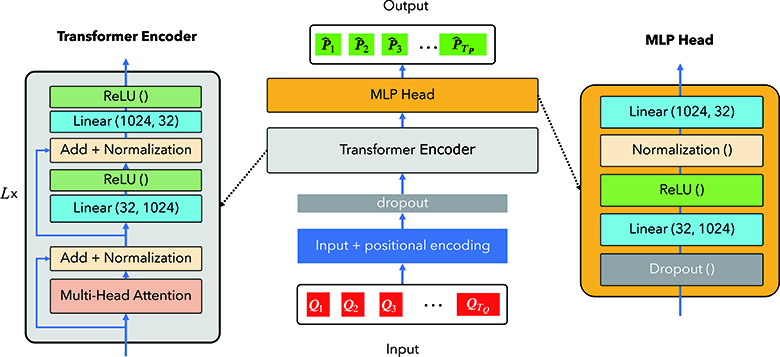
Time series self-attention network
- [1] S. Hu, L. Chen, P. Wu et al., “ST-P3: End-to-End Vision-Based Autonomous Driving via Spatial-Temporal Feature Learning,” S. Avidan, G. Brostow, M. Cissé et al. (Eds.), “Computer Vision – ECCV 2022,” pp. 533-549, Springer Cham, 2022. https://doi.org/10.1007/978-3-031-19839-7_31
- [2] G. Singh, S. Akrigg, M. D. Maio et al., “ROAD: The Road Event Awareness Dataset for Autonomous Driving,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.45, No.1, pp. 1036-1054, 2023. https://doi.org/10.1109/TPAMI.2022.3150906
- [3] C. A. Aubin, B. Gorissen, E. Milana et al., “Towards enduring autonomous robots via embodied energy,” Nature, Vol.602, pp. 393-402, 2022. https://doi.org/10.1038/s41586-021-04138-2
- [4] P. M. S. Ribeiro, A. C. Matos, P. H. Santos, and J. S. Cardoso, “Machine Learning Improvements to Human Motion Tracking with IMUs,” Sensors, Vol.20, No.21, Article No.6383, 2020. https://doi.org/10.3390/s20216383
- [5] X. Zhao, W. Zhang, T. Zhang, and Z. Zhang, “Cross-View Gait Recognition Based on Dual-Stream Network,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.5, pp. 671-678, 2021. https://doi.org/10.20965/jaciii.2021.p0671
- [6] A. Jain, A. R. Zamir, S. Savarese, and A. Saxena, “Structural-RNN: Deep Learning on Spatio-Temporal Graphs,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 5308-5317, 2016. https://doi.org/10.1109/CVPR.2016.573
- [7] J. Martinez, M. J. Black, and J. Romero, “On human motion prediction using recurrent neural networks,” arXiv:1705.02445, 2017.
- [8] H.-K. Chiu, E. Adeli, B. Wang et al., “Action-Agnostic Human Pose Forecasting,” 2019 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 1423-1432, 2019. https://doi.org/10.1109/WACV.2019.00156
- [9] W. Mao, M. Liu, M. Salzmann, and H. Li, “Learning Trajectory Dependencies for Human Motion Prediction,” Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), 2019. https://doi.org/10.1109/ICCV.2019.00958
- [10] C. Wang, Y. Wang, Z. Huang, and Z. Chen, “Simple Baseline for Single Human Motion Forecasting,” Proc. of the IEEE/CVF ICCV Workshops (ICCVW), pp. 2260-2265, 2021. https://doi.org/10.1109/ICCVW54120.2021.00255
- [11] A. Bouazizi, A. Holzbock, U. Kressel et al., “MotionMixer: MLP-Based 3D Human Body Pose Forecasting,” Proc. of the 31st Int. Joint Conf. on Artificial Intelligence (IJCAI-2022), pp. 791-798, 2022.
- [12] T. Sofianos, A. Sampieri, L. Franco, and F. Galasso, “Space-Time-Separable Graph Convolutional Network for Pose Forecasting,” Proc. of the IEEE/CVF ICCV, pp. 11209-11218, 2021.
- [13] I. Chalkidis, A. Jana, D. Hartung et al., “LexGLUE: A Benchmark Dataset for Legal Language Understanding in English,” arXiv:2110.00976, 2021.
- [14] A. Dosovitskiy, L. Beyer, A. Kolesnikov et al., “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” arXiv:2010.11929, 2020.
- [15] A. Vaswani, N. Shazeer, N. Parmar et al., “Attention is All You Need,” Advances in Neural Information Processing Systems, Vol.30, 2017.
- [16] N. Wu, B. Green, X. Ben, and S. O’Banion, “Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case,” arXiv:2001.08317, 2020.
- [17] Y. Xu, Q. Zhang, J. Zhang, and D. Tao, “Vitae: Vision transformer advanced by exploring intrinsic inductive bias,” Advances in Neural Information Processing Systems, Vol.34, 2021.
- [18] N. S. Samghabadi, P. Patwa, S. PYKL et al., “Aggression and Misogyny Detection Using BERT: A Multi-Task Approach,” Proc. of the 2nd Workshop on Trolling, Aggression and Cyberbullying, pp. 126-131, 2020.
- [19] S. Mehta and M. Rastegari, “MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer,” Int. Conf. on Learning Representations, 2022.
- [20] K. Fragkiadaki, S. Levine, P. Felsen, and J. Malik, “Recurrent network models for human dynamics,” arXiv:1508.00271, 2015.
- [21] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.36, No.7, pp. 1325-1339, 2014. https://doi.org/10.1109/TPAMI.2013.248
- [22] C. Ionescu, Fuxin Li, and C. Sminchisescu, “Latent Structured Models for Human Pose Estimation,” ICCV, 2011. https://doi.org/10.1109/ICCV.2011.6126500
- [23] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks,” Advances in Neural Information Processing Systems, Vol.27, 2014.
- [24] B. Wang, E. Adeli, H.-K. Chiu et al., “Imitation Learning for Human Pose Prediction,” Proc. of the IEEE/CVF ICCV, pp. 7124-7133, 2019.
- [25] N. Mahmood, N. Ghorbani, N. F. Troje et al., “AMASS: Archive of Motion Capture as Surface Shapes,” ICCV, pp. 5442-5451, 2019.
- [26] T. v. Marcard, R. Henschel, M. J. Black et al., “Recovering Accurate 3D Human Pose in the Wild Using IMUs and a Moving Camera,” Proc. of European Conf. on Computer Vision (ECCV), pp. 601-617, 2018.
- [27] M. Andriluka, U. Iqbal, A. Milan et al., “PoseTrack: A Benchmark for Human Pose Estimation and Tracking,” arXiv:1710.10000, 2017.
- [28] M. Mathieu, C. Couprie, and Y. LeCun, “Deep multi-scale video prediction beyond mean square error,” arXiv:1511.05440, 2015.
- [29] A. Zanfir, E. Marinoiu, and C. Sminchisescu, “Monocular 3D Pose and Shape Estimation of Multiple People in Natural Scenes - The Importance of Multiple Scene Constraints,” Proc. of the IEEE/CVF Conf. on CVPR, 2018. https://doi.org/10.1109/CVPR.2018.00229
- [30] K. Iskakov, E. Burkov, V. Lempitsky, and Y. Malkov, “Learnable Triangulation of Human Pose,” Proc. of the IEEE/CVF on ICCV, pp. 7718-7727 2019.
- [31] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields,” Proc. of the IEEE Conf. on CVPR, 2017. https://doi.org/10.1109/CVPR.2017.143
- [32] D. Mehta, O. Sotnychenko, F. Mueller et al., “XNect: Real-Time Multi-Person 3D Human Pose Estimation with a Single RGB Camera,” arXiv:1907.00837, 2019.
- [33] Q. Zhang, Y. Xu, J. Zhang, and D. Tao, “ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond,” arXiv:2202.10108, 2022.
- [34] L. Zhao, X. Peng, Y. Tian et al., “Semantic Graph Convolutional Networks for 3D Human Pose Regression,” Proc. of the IEEE/CVF Conf. on CVPR, pp. 3425-3435, 2019.
- [35] D. Pavllo, C. Feichtenhofer, D. Grangier, and M. Auli, “3D Human Pose Estimation in Video with Temporal Convolutions and Semi-Supervised Training,” Proc. of the IEEE/CVF Conf. on CVPR, pp. 7753-7762, 2019.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.