Research Paper:
Capsule Network Extension Based on Metric Learning
Nozomu Ohta
 , Shin Kawai
, and Hajime Nobuhara
, Shin Kawai
, and Hajime Nobuhara
Department of Intelligent Interaction Technologies, University of Tsukuba
1-1-1 Tenoudai, Tsukuba Science City, Ibaraki 305-8573, Japan

A capsule network (CapsNet) is a deep learning model for image classification that provides robustness to changes in the poses of objects in the images. A capsule is a vector whose direction represents the presence, position, size, and pose of an object. However, with CapsNet, the distribution of capsules is concentrated in a class, and the number of capsules increases with the number of classes. In addition, learning is computationally expensive for a CapsNet. We proposed a method to increase the diversity of capsule directions and decrease the computational cost of CapsNet training by allowing a single capsule to represent multiple object classes. To determine the distance between classes, we used an additive angular margin loss called ArcFace. To validate the proposed method, the distribution of the capsules was determined using principal component analysis to validate the proposed method. In addition, using the MNIST, fashion-MNIST, EMNIST, SVHN, and CIFAR-10 datasets, as well as the corresponding affine-transformed datasets, we determined the accuracy and training time of the proposed method and original CapsNet. The accuracy of the proposed method improved by 8.91% on the CIFAR-10 dataset, and the training time reduced by more than 19% for each dataset compared with those of the original CapsNets.
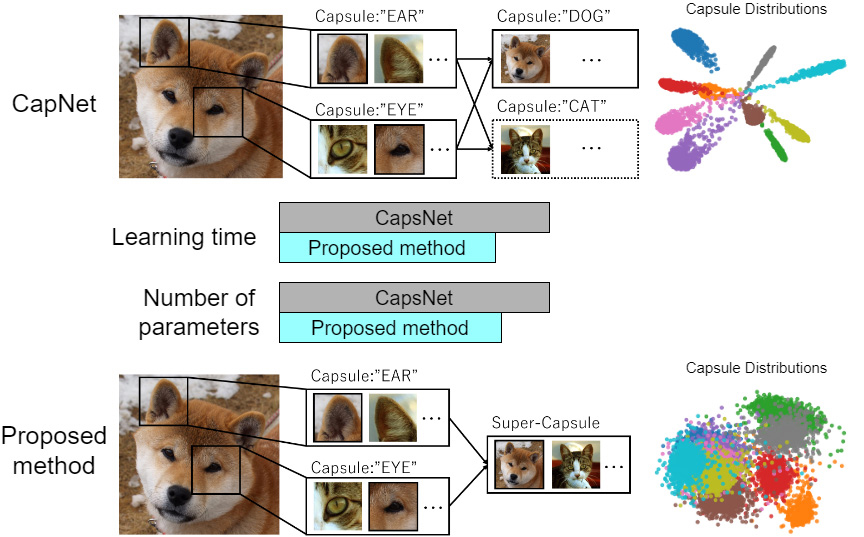
CapsNet and the proposed method
- [1] G. E. Hinton, A. Krizhevsky, and S. D. Wang, “Transforming auto-encoders,” Int. Conf. on Artificial Neural Networks and Machine Learning (ICANN 2011), pp. 44-51, 2011.
- [2] S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic routing between capsules,” Advances in Neural Information Processing Systems 30 (NIPS 2017), pp. 3856-3866, 2017.
- [3] K. Duarte, Y. S. Rawat, and M. Shah, “VideoCapsuleNet: A simplified network for action detection,” Proc. of the 32nd Int. Conf. on Neural Information Processing Systems (NIPS’18), pp. 7621-7630, 2018.
- [4] H. H. Nguyen, J. Yamagishi, and I. Echizen, “Capsule-forensics: Using capsule networks to detect forged images and videos,” 2019 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2019), pp. 2307-2311, 2019.
- [5] H. Ren and H. Lu, “Compositional coding capsule network with k-means routing for text classification,” Pattern Recognition Letters, Vol.160, pp. 1-8, 2022.
- [6] J.-W. Liu, F. Gao, R.-K. Lu, Y.-F. Lian, D.-Z. Wang, X.-L. Luo, and C.-R. Wang, “FSC-CapsNet: Fractionally-strided convolutional capsule network for complex data,” 2019 Int. Joint Conf. on Neural Networks (IJCNN), 2019. https://doi.org/10.1109/IJCNN.2019.8851924
- [7] J. Rajasegaran, V. Jayasundara, S. Jayasekara, H. Jayasekara, S. Seneviratne, and R. Rodrigo, “DeepCaps: Going deeper with capsule networks,” 2019 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2019. https://doi.org/10.1109/CVPR.2019.01098
- [8] N. Ohta, S. Kawai, and H. Nobuhara, “Analysis and learning of capsule networks robust for small image deformation,” 2020 IJCNN, 2020. https://doi.org/10.1109/IJCNN48605.2020.9206651
- [9] P. Afshar, A. Mohammadi, and K. N. Plataniotis, “Brain tumor type classification via capsule networks,” 2018 25th Int. Conf. on Image Processing (ICIP), pp. 3129-3133, 2018.
- [10] S. Chopra, R. Hadsell, and Y. LeCun, “Learning a similarity metric discriminatively, with application to face verification,” 2005 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (CVPR’05), Vol.1, pp. 539-546, 2005.
- [11] F. Schroff, D. Kalenichenko, and J. Philbin, “FaceNet: A unified embedding for face recognition and clustering,” 2015 IEEE Conf. on CVPR, pp. 815-823, 2015.
- [12] K. Sohn, “Improved deep metric learning with multi-class N-pair loss objective,” Proc. of the 30th Int. Conf. on Neural Information Processing Systems (NIPS’16), pp. 1857-1865, 2016.
- [13] W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song, “SphereFace: Deep hypersphere embedding for face recognition,” 2017 IEEE Conf. on CVPR, pp. 6738-6746, 2017.
- [14] H. Wang, Y. Wang, Z. Zhou, X. Ji, D. Gong, J. Zhou, Z. Li, and W. Liu, “CosFace: Large margin cosine loss for deep face recognition,” 2018 IEEE/CVF Conf. on CVPR, pp. 5265-5274, 2018.
- [15] J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “ArcFace: Additive angular margin loss for deep face recognition,” 2019 IEEE/CVF Conf. on CVPR, pp. 4685-4694, 2019.
- [16] Q. Meng, S. Zhao, Z. Huang, and F. Zhou, “MagFace: A universal representation for face Recognition and quality assessment,” 2021 IEEE/CVF Conf. on CVPR, pp. 14220-14229, 2021.
- [17] K. Pearson, “On lines and planes of closest fit to systems of points in space,” The London, Edinburgh, and Dublin Philosophical Magazine and J. of Science, Vol.2, No.11, pp. 559-572, 1901.
- [18] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proc. of the IEEE, Vol.86, No.11, pp. 2278-2324, 1998.
- [19] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Master’s Thesis, Department of Computer Science, University of Toronto, 2009.
- [20] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms,” ArXiv:1708.07747, 2017.
- [21] G. Cohen, S. Afshar, J. Tapson, and A. v. Schaik, “EMNIST: Extending MNIST to handwritten letters,” 2017 IJCNN, pp. 2921-2926, 2017.
- [22] Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y. Ng, “Reading digits in natural images with unsupervised feature learning,” NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- [23] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 3rd Int. Conf. for Learning Representations, 2015.
- [24] R. Pucci, C. Micheloni, G. L. Foresti, and N. Martinel, “Fixed simplex coordinates for angular margin loss in CapsNet,” 2020 25th Int. Conf. on Pattern Recognition (ICPR), pp. 3042-3049, 2021.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.