Paper:
Proposal of Decision-Making Method Under Multi-Task Based on Q-Value Weighted by Task Priority
Tomomi Hanagata and Kentarou Kurashige
Muroran Institute of Technology
27-1 Mizumoto-cho, Muroran, Hokkaido 050-8585, Japan

Robots make decisions in a variety of situations requiring multitasking. Therefore, in this work, a method is studied to address multiple tasks based on reinforcement learning. Our previous method selects an action when the q-values of the action for each task correspond to a priority value in the q-table. However, the decision-making would select an ineffective action in particular situations. In this study, an action value weighted by priority is defined (termed as action priority) to indicate that the selected action is effective in accomplishing the task. Subsequently a method is proposed for selecting actions using action priorities. It is demonstrated that the proposed method can accomplish tasks faster with fewer errors.
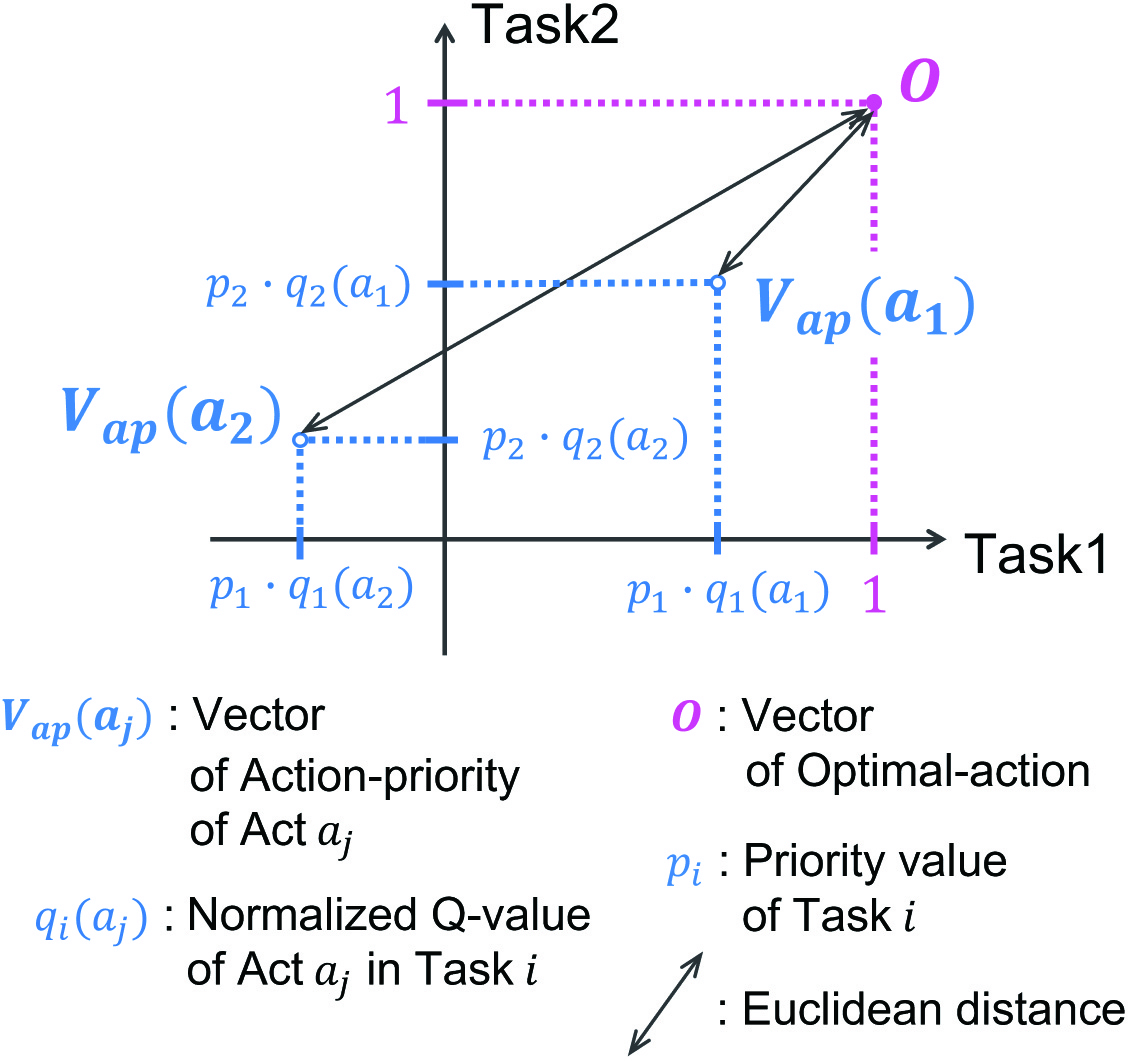
Euclidean distances for decision-making
- [1] Y. Yamazaki, M. Ishii, T. Ito, and T. Hashimoto, “Frailty Care Robot for Elderly and Its Application for Physical and Psychological Support,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.6, pp. 944-952, 2021.
- [2] Y. Fuse, H. Takenouchi, and M. Tokumaru, “A Robot in a Human–Robot Group Learns Group Norms and Makes Decisions Through Indirect Mutual Interaction with Humans,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.1, pp. 169-178, 2020.
- [3] T. Minato and M. Asada, “Environmental change adaptation for mobile robot navigation,” Proc. of 1998 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems: Innovations in Theory, Practice and Applications, Vol.3, pp. 1859-1864, 1998.
- [4] T. Hagiwara and M. Ishikawa, “Emergence of Behaviors by Reinforcement Learning Based on the Desire for Existence,” Brain-Inspired Information Technology, Vol.266, pp. 39-44, 2010.
- [5] N. Yoshida, “On reward function for survival,” Joint 8th Int. Conf. on Soft Computing and Intelligent Systems and 2016 17th Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2016.
- [6] H. Sasaki, T. Horiuchi, and S. Kato, “Experimental Study on Behavior Acquisition of Mobile Robot by Deep Q-Network,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.5, pp. 840-848, 2017.
- [7] R. S. Sutton, and A. G. Barto, “Reinforcement learning,” J. of Cognitive Neuroscience, Vol.11, No.1, pp. 126-134, 1999.
- [8] L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement learning: A survey,” J. of Artificial Intelligence Research, Vol.4, pp. 237-285, 1996.
- [9] S. Ultes, P. Budzianowski, I. Casanueva, N. Mrkšić, L. M. Rojas-Barahona, P.-H. Su, T.-H. Wen, M. Gašić, and S. Young, “Reward-Balancing for Statistical Spoken Dialogue Systems Using Multi-Objective Reinforcement Learning,” Proc. of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pp. 65-70, 2017.
- [10] Y. Shimoguchi and K. Kurashige, “Decision making on robot with multi-task using deep reinforcement learning for each task,” IEEE Int. Conf. on Systems, Man and Cybernetics (SMC), pp. 3460-3465, 2019.
- [11] C. J. c. H. Watkins and P. Dayan, “Q-learning,” Machine Learning, Vol.8, pp. 279-292, 1992.
- [12] A. B. Rodney, “Intelligence Without Representation,” Artificial Intelligence, Vol.47, Nos.1-3, pp. 139-159, 1991.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.