Paper:
Web-Questionnaire-Based Corpus Creation Under Assumption of Human as Speech Targets
Kazuaki Shima*, Jinhua She*,†, Yasunari Obuchi*, and Abdullah M. Iliyasu**
*Tokyo University of Technology
1404-1 Katakura, Hachioji, Tokyo 192-0982, Japan
**Department of Electrical Engineering, College of Engineering, Prince Sattam Bin Abdulaziz University
Al-Kharj 11942, Kingdom of Saudi Arabia
†Corresponding author

This paper presents a method that uses a web questionnaire to create a corpus containing spontaneous utterances of natural ideas, which may contain grammatical mistakes. In an experimental implementation of the method, the subjects were informed that they were receiving nursing care from a person, and they were required to answer a web-based questionnaire in which their responses were recorded as speech utterances. Compared to the Wizard of Oz approach and interview-based corpus-creation methods, the presented method simplifies the collection of utterances. Furthermore, we conducted a two-fold assessment to verify the effectiveness of the presented method. First, the approach exhibited a significant reduction in workload compared to interview-style utterance collection. Second, we compared the variety of expressions collected when subjects were informed that they were talking to a person with those collected when they were informed that they were communicating with a nursing robot. The results indicate that, although the number of utterances was larger for a robot than for a person, in terms of other metrics such as time efficiency index, the total number of morphemes, the average number of morphemes per utterance, the number of unique morphemes, and coefficient of variation, the utterances were larger for a human speech target than for a robot.
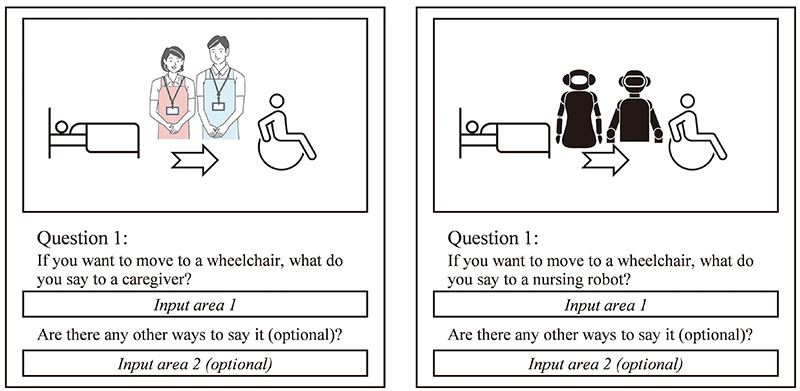
Image of this method (a) for proposal
- [1] Faurecia Clarion Electronics Co., Ltd., Intelligent VOICE (in Japanese), https://www.clarion.com/jp/ja/products-personal/service/IntelligentVoice/index.html [accessed December 9, 2021]
- [2] Panasonic Corporation, Drive P@ss (in Japanese), https://panasonic.jp/car/guide/voice_recognition/ [accessed December 9, 2021]
- [3] S. Yamamoto, J. Woo, W. H. Chin, K. Matsumura, and N. Kubota, “Interactive Information Support by Robot Partners Based on Informationally Structured Space,” J. Robot. Mechatron., Vol.32, No.1, pp. 236-243, 2020.
- [4] T. Homma, K. Shima, and T. Matsumoto, “Robust utterance classification using multiple classifiers in the presence of speech recognition errors,” Proc. of 2016 IEEE Spoken Language Technology Workshop (SLT), pp. 369-375, 2016.
- [5] T. Homma, Y. Obuchi, K. Shima, R. Ikeshita, H. Kokubo, and T. Matsumoto, “In-vehicle voice interface with improved utterance classification accuracy using off-the-shelf cloud speech recognizer,” IEICE Trans. Inf. & Syst., Vol.E101-D, Issue 12, pp. 3123-3137, 2018.
- [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” Proc. of the 17th Annual Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), pp. 4171-4186, 2019.
- [7] K. Itou, T. Akiba, O. Hasegawa, S. Hayamizu, and K. Tanaka, “A Japanese spontaneous speech corpus collected using automatically inferencing Wizard of OZ system,” J. of the Acoustical Society of Japan (E), Vol.20, Issue 3, pp. 207-214, 1999.
- [8] M. Okamoto and N. Yamanaka, “Wizard of Oz Method for Constructing Conversational Web Agents,” Trans. of the Japanese Society for Artificial Intelligence, Vol.17, No.3, pp. 293-300, 2002.
- [9] K. Shima, T. Homma, R. Ikeshita, H. Kokubo, Y. Obuchi, and J. She, “Interview-style-based method of collecting spontaneous speech corpus for car navigation systems,” IEICE Trans. Inf. & Syst., Vol.J101-D, No.2, pp. 446-455, 2018 (in Japanese).
- [10] M. Ahmed, C. Dixit, R. E. Mercer, A. Khan, M. R. Samee, and F. Urra, “Multilingual corpus creation for multilingual semantic similarity task,” Proc. of the 12th Language Resources and Evaluation Conf., pp. 4190-4196, 2020.
- [11] S. Mishra and A. Sharma, “Crawling Wikipedia Pages to Train Word Embeddings Model for Software Engineering Domain,” 14th Innovations in Software Engineering Conf. (India Software Engineering Conf.), Article No.18, 2021.
- [12] L. Liu, Q. Wang, and Y. Li, “Improved Chinese Sentence Semantic Similarity Calculation Method Based on Multi-Feature Fusion,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.4, pp. 442-449, 2021.
- [13] J. Le and H. Yamana, “Cross-Lingual Investigation of User Evaluations for Global Restaurants,” Information and Media Technologies, Vol.10, Issue 2, pp. 317-322, 2015.
- [14] A. Tsuya, Y. Sugawara, A. Tanaka, and H. Narimatsu, “Do cancer patients tweet? Examining the twitter use of cancer patients in Japan,” J. of Medical Internet Research, Vol.16, No.5, Article No.e137, 2014.
- [15] A. Uchida, “How Do Japanese People Talk About Politics on Twitter? Analysis of Emotional Expressions in Political Topics on Japanese Twitter,” Psychologia, Vol.61, Issue 2, pp. 124-157, 2018.
- [16] Y. Wang, J. Berant, and P. Liang, “Building a semantic parser overnight,” Proc. of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Int. Joint Conf. on Natural Language Processing, Vol.1, pp. 1332-1342, 2015.
- [17] T. Ogiso, “Today’s Japanese corpora,” The J. of Information Science and Technology Association, Vol.64, No.11, pp. 463-468, 2014.
- [18] N.-C. Luo, “Massive Data Mining Algorithm for Web Text Based on Clustering Algorithm,” J. Adv. Comput. Intell. Intell. Inform., Vol.23, No.2, pp. 362-365, 2019.
- [19] K. Shima, J. She, Y. Obuchi, and A. M. Iliyasu, “Web-Questionnaire-Based Method for Creating Corpus Containing a Large Number of Morphemes,” The 7th Int. Workshop on Advanced Computational Intelligence and Intelligent Informatics (IWACIII2021), Article No.T2-3-3, 2021.
- [20] K. Shima, T. Homma, M. Motohashi, R. Ikeshita, H. Kokubo, Y. Obuchi, and J. She, “Efficient Corpus Creation Method for NLU Using Interview with Probing Questions,” J. Adv. Comput. Intell. Intell. Inform., Vol.23, No.5, pp. 947-955, 2019.
- [21] K. Takeda, H. Fujimura, K. Itou, N. Kawaguchi, S. Matsubara, and F. Itakura, “Construction and evaluation of a large in-car speech corpus,” IEICE Trans. Inf. & Syst., Vol.E88-D, No.3, pp. 553-561, 2005.
- [22] T. Kudo, “MeCab: Yet another part-of-speech and morphological analyzer,” (in Japanese) http://taku910.github.io/mecab/ [accessed December 9, 2021]
- [23] K. Uchimoto, S. Sekine, and H. Isahara, “Morphological Analysis Based on A Maximum Entropy Model – An Approach to The Unknown Word Problem,” J. of Natural Language Processing, Vol.8, Issue 1, pp. 127-141, 2001 (in Japanese).
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.