Paper:
Multi-Faceted Decision Making Using Multiple Reinforcement Learning to Reducing Wasteful Actions
Riku Narita and Kentarou Kurashige
Muroran Institute of Technology
27-1 Mizumoto-cho, Muroran city, Hokkaido 050-8585, Japan

Reinforcement learning can lead to autonomous behavior depending on the environment. However, in complex and high-dimensional environments, such as real environments, a large number of trials are required for learning. In this paper, we propose a solution for the learning problem using local learning to select an action based on the surrounding environmental information. Simulation experiments were conducted using maze problems, pitfall problems, and environments with random agents. The actions that did not contribute to task accomplishment were compared between the proposed method and ordinary reinforcement learning method.
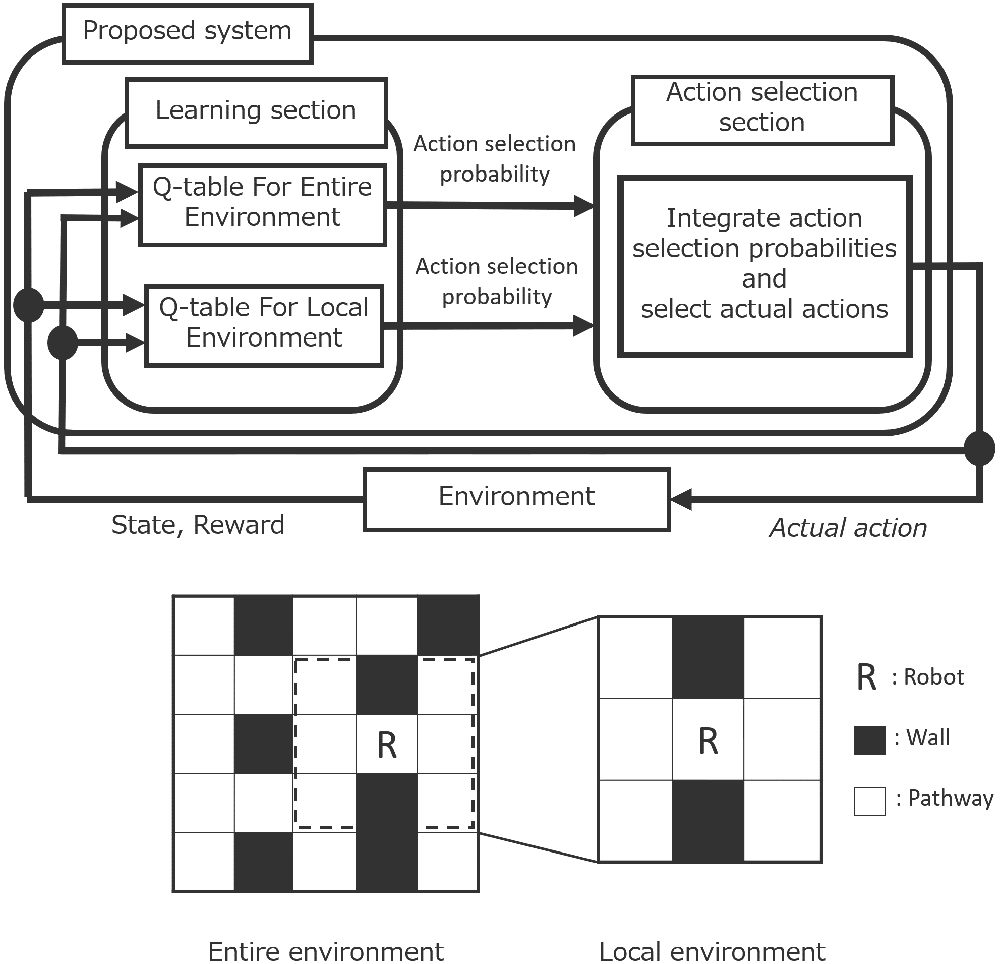
Outline of the proposed system
- [1] T. Hashimoto, X. Tao, T. Suzuki, T. Kurose, Y. Nishikawa, and Y. Kagawa, “Decision Making of Communication Robots Through Robot Ethics,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.4, pp. 467-477, 2021.
- [2] Y. Yamazaki, M. Ishii, T. Ito, and T. Hashimoto, “Frailty Care Robot for Elderly and its Application for Physical and Psychological Support,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.6, pp. 944-952, 2021.
- [3] J. H. Connell and S. Mahadevan, “Robot Learning,” Kluwer Academic Publishers, 1993.
- [4] N. T. Thinh, T. P. Tho, and N. D. X. Hai, “Adaptive Fuzzy Control for Autonomous Robot under Complex Environment,” Int. J. Mech. Eng. Robot. Res., Vol.10, No.5, pp. 216-223, 2021.
- [5] R. S. Sutton and A. G. Barto, “Reinforcement learning,” J. Cogn. Neurosci., Vol.11, No.1, pp. 126-134, 1999.
- [6] L. P. Kaelbling, M. L. Littman, and A. W. Moore, “Reinforcement Learning: A Survey,” J. Artif. Intell. Res., Vol.4, pp. 237-285, 1996.
- [7] J. Wang, K. Hirota, X. Wu, Y. Dai, and Z. Jia, “Hybrid Bidirectional Rapidly Exploring Random Tree Path Planning Algorithm with Reinforcement Learning,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.1, pp. 121-129, 2021.
- [8] D. Pathak, “Curiosity-driven exploration by self-supervised prediction,” Int. Conf. on Machine Learning, PMLR, Sydney, Australia, 2017.
- [9] N. Bougie and R. Ichise, “Fast and slow curiosity for high-level exploration in reinforcement learning,” Appl. Intell., Vol.51, No.2, pp. 1086-1107, 2021.
- [10] K. Miyazaki, “Exploitation-Oriented Learning with Deep Learning – Introducing Profit Sharing to a Deep Q-Network –,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.5, pp. 849-855, 2017.
- [11] A. Dorri, S. S. Kanhere, and R. Jurdak, “Multi-Agent Systems: A Survey,” IEEE Access, Vol.6, pp. 28573-28593, 2018.
- [12] Y. G. Kim et al., “Multi-agent system and reinforcement learning approach for distributed intelligence in a flexible smart manufacturing system,” J. Manuf. Syst., Vol.57, pp. 440-450, 2020.
- [13] F. L. Da Silva, R. Glatt, and A. H. R. Costa, “Simultaneously Learning and Advising in Multiagent Reinforcement Learning,” Proc. of Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS), pp. 1100-1108, 2017.
- [14] S. Kapoor, “Multi-agent reinforcement learning: A report on challenges and approaches,” arXiv preprint arXiv:1807.09427, 2018.
- [15] F. Uwano and K. Takadama, “Comparison Between Reinforcement Learning Methods with Different Goal Selections in Multi-Agent Cooperation,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.5, pp. 917-929, 2017.
- [16] H.-R. Lee and T. Lee, “Multi-agent reinforcement learning algorithm to solve a partially-observable multi-agent problem in disaster response,” Eur. J. Oper. Res., Vol.291, No.1, pp. 296-308, 2021.
- [17] D. R. Meneghetti and R. A. C. Bianchi, “Towards Heterogeneous Multi-Agent Reinforcement Learning with Graph Neural Networks,” 17th National Meeting on Artificial and Computational Intelligence, pp. 579-590, 2019.
- [18] C. Wakilpoor, “Heterogeneous multi-agent reinforcement learning for unknown environment mapping,” arXiv preprint arXiv:2010.02663, 2020.
- [19] R. Narita, T. Matsushima, and K. Kurashige, “Efficient exploration by switching agents according to degree of convergence of learning on Heterogeneous Multi-Agent Reinforcement Learning in Single Robot,” IEEE Symposium Series on Computational Intelligence, 2021.
- [20] Y. Hatcho, K. Hattori, and K. Takadama, “Time Horizon Generalization in Reinforcement Learning: Generalizing Multiple Q-Tables in Q-Learning Agents,” J. Adv. Comput. Intell. Intell. Inform., Vol.13, No.6, pp. 667-674, 2009.
- [21] J. Andreas, D. Klein, and S. Levine. “Modular multitask reinforcement learning with policy sketches,” Proc. of the 34th Int. Conf. on Machine Learning, PMLR, Vol.70, pp. 166-175, 2017.
- [22] K. Frans, J. Ho, X. Chen, P. Abbeel, and J. Schulman, “Meta learning shared hierarchies,” 6th Int. Conf. on Learning Representations, 2018.
- [23] H. Shteingart, and L. Yonatan, “Reinforcement learning and human behavior,” Curr. Opin. Neurobiol. Vol.25, pp. 93-98, 2014.
- [24] S. Collette, “Neural computations underlying inverse reinforcement learning in the human brain,” eLife, Vol.6, e29718, 2017.
- [25] E. Schulz and S. J. Gershman, “The algorithmic architecture of exploration in the human brain,” Curr. Opin. Neurobiol., Vol.55, pp. 7-14, 2019.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.