Paper:
Adaptive Synapse Arrangement in Cortical Learning Algorithm
Takeru Aoki, Keiki Takadama, and Hiroyuki Sato
Graduate School of Informatics and Engineering, The University of Electro-Communications
1-5-1 Chofugaoka, Chofu, Tokyo 182-8585, Japan

The cortical learning algorithm (CLA) is a time-series data prediction method that is designed based on the human neocortex. The CLA has multiple columns that are associated with the input data bits by synapses. The input data is then converted into an internal column representation based on the synapse relation. Because the synapse relation between the columns and input data bits is fixed during the entire prediction process in the conventional CLA, it cannot adapt to input data biases. Consequently, columns not used for internal representations arise, resulting in a low prediction accuracy in the conventional CLA. To improve the prediction accuracy of the CLA, we propose a CLA that self-adaptively arranges the column synapses according to the input data tendencies and verify its effectiveness with several artificial time-series data and real-world electricity load prediction data from New York City. Experimental results show that the proposed CLA achieves higher prediction accuracy than the conventional CLA and LSTMs with different network optimization algorithms by arranging column synapses according to the input data tendency.
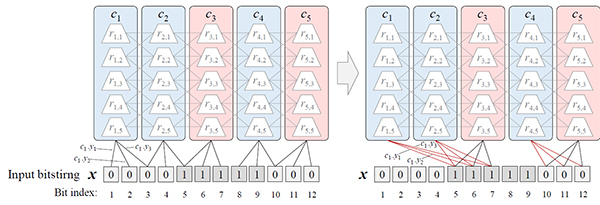
Proposed adaptive column synapse arrangement
- [1] J. Hawkins, A. Subutai, and D. Dubinsky, “Hierarchical temporal memory including HTM cortical learning algorithms,” Technical report, Numenta, Inc., 2010.
- [2] J. Hawkins and A. Subutai, “Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex,” Frontiers in Neural Circuits, Vol.10, pp. 1-13, 2016.
- [3] NuPIC, https://github.com/numenta/nupic [accessed February 27, 2020]
- [4] J. Hawkins and S. Blakeslee, “On Intelligence,” Times Books, 2004.
- [5] S. Ahmad and J. Hawkins, “Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory,” Numenta, pp. 1-18, 2015.
- [6] L. R. Rabiner and B. H. Juang, “An Introduction to Hidden Markov Models,” IEEE Acoustics, Speech & Signal Processing Magazine, Vol.3, No.1, pp. 4-16, 1986.
- [7] L. R. Rabiner, “A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition,” Proc. of the IEEE, Vol.77, No.2, pp. 257-285, 1989.
- [8] A. Gupta and B. Dhingra, “Stock Market Prediction Using Hidden Markov Models,” Proc. of Students Conf. on Engineering and Systems, pp. 1-4, 2012.
- [9] A. Krogh, B. Larsson, G. Von Heijne, and E. L. L. Sonnhammer, “Predicting Transmembrane Protein Topology with a Hidden Markov Model: Application to Complete Genomes,” J. of Molecular Biology, Vol.305, Issue 3, pp. 567-580, 2001.
- [10] P. Dagum, A. Galper, and E. Horvitz, “Dynamic Network Models for Forecasting,” Proc. of the 8th Int. Conf. on Uncertainty in Artificial Intelligence (UAI1992), pp. 41-48, 1992.
- [11] K. Murphy, “Dynamic Bayesian Networks: Representation, Inference and Learning,” Ph. D. thesis, University of California Berkeley, Computer Science Division, 2002.
- [12] A. Metallinou, S. Lee, and S. Narayanan, “Decision Level Combination of Multiple Modalities for Recognition and Analysis of Emotional Expression,” Proc. of the 2010 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2010), pp. 2462-2465, 2010.
- [13] Y. Zhang and Q. Ji, “Active and Dynamic Information Fusion for Facial Expression Understanding from Image Sequences,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.27, No.5, pp. 1-16, 2005.
- [14] M. Zou and S. D. Conzen, “A New Dynamic Bayesian Network (DBN) Approach for Identifying Gene Regulatory Networks from Time Course Microarray Data,” Bioinformatics, Vol.21, No.1, pp. 71-79, 2005.
- [15] J. Pearl, “Bayesian networks: A model of self-activated memory for evidential reasoning,” Technical Report, University of California, CSD-850021, R-43, 1985.
- [16] T. S. Furey, N. Cristianini, N. Duffy, D. W. Bednarski, M. Schummer, and D. Haussler, “Support Vector Machine Classification and Validation of Cancer Tissue Samples Using Microarray Expression Data,” Bioinformatics, Vol.16, Issue 10, pp. 906-914, 2000.
- [17] M. Wöllmer, F. Eyben, B. Schuller, E. D. -Cowie, and R. Cowie, “Data-Driven Clustering in Emotional Space for Affect Recognition Using Discriminatively Trained LSTM Networks,” Proc. of InterSpeech, pp. 1595-1598, 2009.
- [18] J. H. Min and Y.-C. Lee, “Bankruptcy Prediction Using Support Vector Machine With Optimal Choice of Kernel Function Parameters,” Expert Systems with Applications, Vol.28, Issue 4, pp. 603-614, 2005.
- [19] S. Hua and Z. Sun, “Support Vector Machine Approach for Protein Subcellular Localization Prediction,” Bioinformatics, Vol.17, No.8, pp. 721-728, 2001.
- [20] J. L. Elman, “Finding Structure in Time,” Cognitive Science, Vol.14, Issue 2, pp. 179-211, 1990.
- [21] J. T. Connor, R. D. Martin, and L. E. Atlas, “Recurrent Neural Networks and Robust Time Series Prediction,” IEEE Trans. on Neural Networks, Vol.5, No.2, pp. 240-254, 1994.
- [22] T. Mikolov, M. Karafiát, L. Burget, J. Černocký, and S. Khudanpur, “Recurrent Neural Network Based Language Model,” Proc. of InterSpeech, pp. 1045-1048, 2010.
- [23] C.-M. Kuan and T. Liu, “Forecasting Exchange Rates Using Feedforward and Recurrent Neural Networks,” J. of Applied Econometrics, Vol.10, Issue 4, pp. 347-364, 1995.
- [24] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, Vol.9, No.8, pp. 1735-1780, 1997.
- [25] B. A. Pearlmutter, “Learning State Space Trajectories in Recurrent Neural Networks,” Neural Computation, Vol.1, Issue 2, pp. 263-269, 1989.
- [26] R. J. Williams, “Complexity of Exact Gradient Computation Algorithms for Recurrent Neural Networks,” Technical Report, Boston: Northeastern University, College of Computer Science, 1989.
- [27] S. E. Fahlman, “The Recurrent Cascade-correlation Architecture,” Proc. of Advances in Neural Information Processing Systems 3 (NIPS 1990), pp. 190-196, 1991.
- [28] J. Schmidhuber, “A Fixed Size Storage O(n3) Time Complexity Learning Algorithm for Fully Recurrent Continually Running Networks,” Neural Computation, Vol.4, Issue 2, pp. 243-248, 1992.
- [29] B. A. Pearlmutter, “Gradient Calculations for Dynamic Recurrent Neural Networks: A Survey,” IEEE Trans. on Neural Networks, Vol.6, Issue 5, pp. 1212-1228, 1995.
- [30] K. J. Lang, A. H. Waibel, and G. E. Hinton, “A Time-delay Neural Network Architecture for Isolated Word Recognition,” Neural Network, Vol.3, Issue 1, pp. 23-43, 1990.
- [31] B. De Vries and J. C. Principe, “A Theory for Neural Networks With Time Delays,” Proc. of Advances in Neural Information Processing Systems 3 (NIPS 1990), pp. 162-168, 1991.
- [32] T. A. Plate, “Holographic Recurrent Networks,” Proc. on Advances in Neural Information Processing Systems 5 (NIPS 1992), pp. 34-41, 1993.
- [33] T. Lin, B. G. Horne, P. Tino, and C. L. Giles, “Learning Long-Term Dependencies in NARX Recurrent Neural Networks,” IEEE Trans. on Neural Networks, Vol.7, No.6, pp. 1329-1338, 1996.
- [34] Y. Fan, Y. Qian, F. Xie, and F. K. Soong, “TTS Synthesis with Bidirectional LSTM based Recurrent Neural Networks,” Proc. of InterSpeech, pp. 1964-1968, 2014.
- [35] M. Sundermeyer, R. Schlüter, and H. Ney, “LSTM Neural Networks for Language Modeling,” Proc. of InterSpeech, pp. 194-197, 2012.
- [36] A. Graves and J. Schmidhuber, “Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures,” Neural Network, Vol.18, Issue 5-6, pp. 602-610, 2005.
- [37] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Backpropagation Applied to Handwritten Zip Code Recognition,” Neural Computation, Vol.1, Issue 4, pp. 541-551, 1989.
- [38] J. Bradbury, S. Merity, C. Xiong, and R. Socher, “Quasi-Recurrent Neural Networks,” arXiv preprint, arXiv:1611.01576v2, 2016.
- [39] A. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A Generative Model for Raw Audio,” arXiv preprint, arXiv:1609.03499v2, 2016.
- [40] D. George, W. Lehrach, K. Kansky, M. L. -Gredilla, C. Laan, B. Marthi, X. Lou, Z. Meng, Y. Liu, H. Wang, A. Lavin, and D. S. Phoenix, “A Generative Vision Model That Trains With High Data Efficiency and Breaks Text-based CAPTCHAs,” Science, Vol.358, Issue 6368, 2017.
- [41] W. Lotter, G. Kreiman, and D. Cox, “Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning,” arXiv preprint, arXiv:1605.08104v5, 2016
- [42] R. P. N. Rao and D. H. Ballard, “Predictive Coding in the Visual Cortex: A Functional Interpretation of Some Extra-classical Receptive-field Effects,” Nature Neuroscience, Vol.2, No.1, pp. 79-87, 1999.
- [43] H. Jaeger, “The “Echo State” Approach to Analysing and Training Recurrent Neural Networks – With An Erratum Note,” Technical Report 154, German National Research Center for Information Technology, 2001.
- [44] W. Maass, T. Natschläger, and H. Markram, “Real-Time Computing Without Stable States: A New Framework for Neural Computation Based on Perturbations,” Neural Computation, Vol.14, Issue 11, pp. 2531-2560, 2002.
- [45] K. Fukushima, “Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position,” Biological Cybernetics, Vol.36, Issue 4, pp. 193-202, 1982.
- [46] Y. Ichisugi, “A Cerebral Cortex Model that Self-Organizes Conditional Probability Tables and Executes Belief Propagation,” 2007 Int. Joint Conf. on Neural Networks, pp. 178-183, 2007.
- [47] D. George, “How the Brain Might Work: A Hierarchical and Temporal Model for Learning and Recognition,” Ph.D. dissertation, Stanford University, 2008.
- [48] Y. Cui, S. Ahmad, and J. Hawkins, “Continuous Online Sequence Learning with an Unsupervised Neural Network Model,” Neural Computation, Vol.28, Issue 11, pp. 2474-2504, 2016.
- [49] New York ISO (Independent System Operator), http://mis.nyiso.com/public/ [accessed February 27, 2020]
- [50] A. M. Zyarah and D. Kudithipudi, “Neuromemrisitive Architecture of HTM with On-Device Learning and Neurogenesis,” ACM J. on Emerging Technologies in Computing Systems, Vol.15, No.3, Article 24, 2019.
- [51] D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” arXiv preprint, arXiv:1412.6980, 2014.
- [52] K. Hornik, “Approximation Capabilities of Multilayer Feedforward Networks,” Neural Network, Vol.4, No.2, pp. 251-257, 1991.
- [53] “Keras,” https://github.com/keras-team/keras [accessed February 27, 2020]
- [54] A. Filion, “Data Analytics with MATLAB Webinar Files,” MATLAB Central File Exchange, https://www.mathworks.com/matlabcentral/fileexchange/49063-data-analytics-with-matlab-webinar-files [accessed February 27, 2020]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.