Paper:
POI Classification Method Based on Feature Extension and Deep Learning
Chaoran Zhou, Hang Yang, Jianping Zhao†, and Xin Zhang
School of Computer Science and Technology, Changchun University of Science and Technology
No.7186 Weixing Road, Changchun, Jilin 130022, China
†Corresponding author

The automatic classification of point of interest (POI) function types based on POI name texts and intelligent computing can provide convenience in travel recommendations, map information queries, urban function divisions, and other services. However, POI name texts belong to short texts, which few characters and sparse features. Therefore, it is difficult to guarantee the feature learning ability and classification effect of the model when distinguishing the POI function types. This paper proposes a POI classification method based on feature extension and deep learning to establish a short-text classification model. We utilize an Internet search engine as an external knowledge base to introduce real-time, large-scale text feature information to the original POI text to solve the limitation of sparse POI name text features. The input text information is represented by the attention calculation matrix used to reduce the noise information of the extended text and the word-embedding matrix of the original text. We utilize a convolutional neural network with excellent local feature extraction ability to establish the classification model. Experimental results on a real-world dataset (obtained from Baidu) show the excellent performance of our model in POI classification tasks compared with other baseline models.
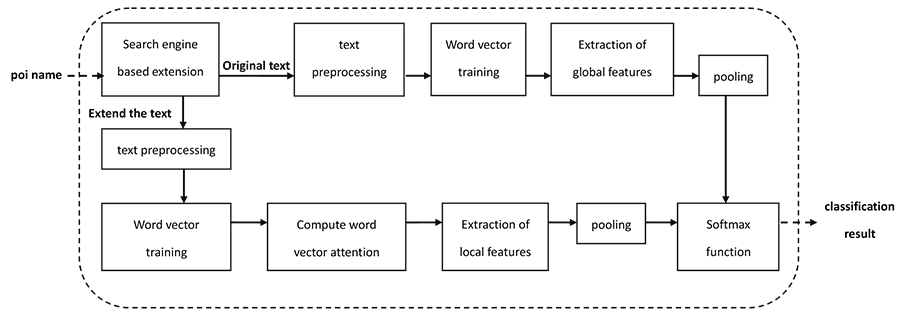
General framework of the method
- [1] M. Sahami and T. D. Heilman, “A web-based kernel function for measuring the similarity of short text snippets,” Proc. of the 15th Int. Conf. on World Wide Web, pp. 377-386, 2006.
- [2] J. Krösche and S. Boll, “The xPOI concept,” Int. Symp. on Location- and Context-Awareness, pp. 113-119, 2005.
- [3] D. Metzler, S. Dumais, and C. Meek, “Similarity measures for short segments of text,” European Conf. on Information Retrieval, pp. 16-27, 2007.
- [4] Z. Liu, W. Yu, W. Chen, S. Wang, and F. Wu, “Short text feature selection for micro-blog mining,” 2010 Int. Conf. on Computational Intelligence and Software Engineering, doi: 10.1109/CISE.2010.5677015, 2010.
- [5] Y. Yue, Y. Zhang, X. Hu, and P. Li, “Extremely Short Chinese Text Classification Method Based on Bidirectional Semantic Extension,” J. of Physics: Conf. Series, Vol.1437, doi: 10.1088/1742-6596/1437/1/012026, 2020.
- [6] W. Meng, L. Lanfen, W. Jing, Y. Penghua, L. Jiaolong, and X. Fei, “Improving short text classification using public search engines,” Int. Symp. on Integrated Uncertainty in Knowledge Modelling and Decision Making, pp. 157-166, 2013.
- [7] S. Mizzaro, M. Pavan, I. Scagnetto, and M. Valenti, “Short text categorization exploiting contextual enrichment and external knowledge,” Proc. of the 1st Int. Workshop on Social Media Retrieval and Analysis, pp. 57-62, 2014.
- [8] S. J. Choi, H. J. Song, S. B. Park, and S. J. Lee, “A POI Categorization by Composition of Onomastic and Contextual Information,” 2014 IEEE/WIC/ACM Int. Joint Conf. on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), doi: 10.1109/WI-IAT.2014.78, 2014.
- [9] D.-T. Vo and C.-Y. Ock, “Learning to classify short text from scientific documents using topic models with various types of knowledge,” Expert Systems with Applications, Vol.42, No.3, pp. 1684-1698, 2015.
- [10] X.-H. Phan, L.-M. Nguyen, and S. Horiguchi, “Learning to Classify Short and Sparse Text & Web with Hidden Topics from Large-Scale Data Collections,” Proc. of the 17th Int. Conf. on World Wide Web (WWW 2008), pp. 91-100, 2008.
- [11] C. Ma, Y. Jiang, and Y. Li, “Short text classification based on word vector similarity,” J. of Shandong University (Natural Science), Vol.49, No.12, pp. 18-22+35, 2014 (in Chinese and English abstract).
- [12] Y. Gao and B. Liu, “Headlines classification method based on ensemble learning,” Application Research of Computers, Vol.34, No.4, pp. 1004-1007, 2017 (in Chinese and English abstract).
- [13] Q. Le and T. Mikolov, “Distributed representations of sentences and documents,” Proc. of the 31st Int. Conf. on Machine Learning, pp. 1188-1196, 2014.
- [14] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint, arXiv:1301.3781, 2013.
- [15] N. Kalchbrenner, E. Grefenstette, and P. Blunsom, “A Convolutional Neural Network for Modelling Sentences,” Proc. of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 655-665, 2014.
- [16] Y. Kim, “Convolutional neural networks for sentence classification,” Proc. of the 2014 Conf. of Empirical Methods in Natural Language Processing (EMNLP), pp. 1746-1751, 2014.
- [17] W. Hu, Z. Gu, Y. Xie, L. Wang, and K. Tang, “Chinese Text Classification Based on Neural Networks and Word2vec,” 2019 IEEE 4th Int. Conf. on Data Science in Cyberspace (DSC), doi: 10.1109/DSC.2019.00050, 2019.
- [18] J. Nowak, A. Taspinar, and R. Scherer, “LSTM Recurrent Neural Networks for Short Text and Sentiment Classification,” Int. Conf. on Artificial Intelligence and Soft Computing (ICAISC 2017), pp. 553-562, 2017.
- [19] V. Mnih, N. Heess, A. Graves, and K. Kavukcuoglu, “Recurrent models of visual attention,” Proc. of the 27th Int. Conf. on Neural Information Processing Systems (NIPS 2014), pp. 2204-2212, 2014.
- [20] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint, arXiv:1409.0473, 2014.
- [21] S. Zhang and H. Cheng. ”Exploiting context graph attention for poi recommendation in location-based social networks,” Int. Conf. on Database Systems for Advanced Applications, pp. 83-99, 2018.
- [22] T. Liu, J. Liao, Z. Wu, Y. Wang, and J. Wang, “Exploiting geographical-temporal awareness attention for next point-of-interest recommendation,” Neurocomputing, Vol.400, pp. 227-237, 2020.
- [23] W. Yin, H. Schütze, B. Xiang, and B. Zhou, “ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs,” Tran. of the Association for Computational Linguistics, Vol.4, No.3, pp. 259-272, 2016.
- [24] S.-B. Kim, K.-S. Han, H.-C. Rim, and S. H. Myaeng, “Some Effective Techniques for Naive Bayes Text Classification,” IEEE Trans. on Knowledge & Data Engineering, Vol.18, pp. 1457-1466, 2006.
- [25] S. Jiang, G. Pang, M. Wu, and L. Kuang, “An improved K-nearest-neighbor algorithm for text categorization,” Expert Systems with Applications, Vol.39, pp. 1503-1509, 2012.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.