Paper:
Exploratory Causal Analysis of Open Data: Explanation Generation and Confounder Identification
Jing Song*, Satoshi Oyama*,**,***, and Masahito Kurihara*
*Graduate School of Information Science and Technology, Hokkaido University
Nishi 9, Kita 14, Kita-ku, Sapporo, Hokkaido 060-0814, Japan
**Global Institution for Collaborative Research and Education, Hokkaido University
Nishi 5, Kita 8, Kita-ku, Sapporo, Hokkaido 060-0808, Japan
***RIKEN Center for Advanced Intelligence Project
15th floor, Nihonbashi 1-chome Mitsui Building, 1-4-1 Nihonbashi, Chuo, Tokyo 103-0027, Japan

Open data are becoming increasingly available in various domains, and many organizations rely on making decisions according to data. Such decision making requires care to distinguish between correlations and causal relationships. Among data analysis tasks, causal relationship analysis is especially complex because of unobserved confounders. For example, to correctly analyze the causal relationship between two variables, the possible confounding effect of a third variable should be considered. In the open-data environment, however, it is difficult to consider all possible confounders in advance. In this paper, we propose a framework for exploratory causal analysis of open data, in which possible confounding variables are collected and incrementally tested from a large volume of open data. To the extent of the authors’ knowledge, no framework has been proposed to incorporate data for possible confounders in causal analysis process. This paper shows an original way to expand causal structures and generate reasonable causal relationships. The proposed framework accounts for the effect of possible confounding in causal analysis by first using a crowdsourcing platform to collect explanations of the correlation between variables. Keywords are then extracted using natural language processing methods. The framework searches the related open data according to the extracted keywords. Finally, the collected explanations are tested using several automated causal analysis methods. We conducted experiments using open data from the World Bank and the Japanese government. The experimental results confirmed that the proposed framework enables causal analysis while considering the effects of possible confounders.
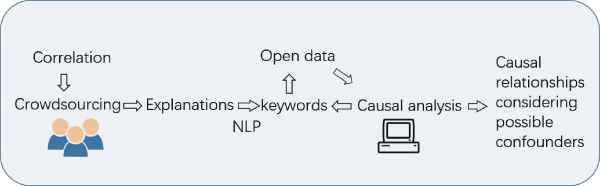
A framework for exploratory causal analysis of open data
- [1] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, and Z. Ives, “Dbpedia: A nucleus for a web of open data,” In The Semantic Web, pp. 722-735, Springer, 2007.
- [2] C. Bizer, T. Heath, and T. Berners-Lee, “Linked data – the story so far,” Int. J. on Semantic Web and Information Systems, Vol.5, No.3, pp. 1-22, 2009.
- [3] C. Hartung, A. Lerer, Y. Anokwa, C. Tseng, W. Brunette, and G. Borriello, “Open data kit: tools to build information services for developing regions,” Proc. of the 4th ACM/IEEE Int. Conf. on Information and Communication Technologies and Development, Article No.18, 2010.
- [4] C. B. Davis, “Making sense of open data: from raw data to actionable insight,” Ph.D. Thesis, Delft University of Technology, 2012.
- [5] B.-N. Huang, M. J. Hwang, and C. W. Yang, “Causal relationship between energy consumption and GDP growth revisited: a dynamic panel data approach,” Ecological Economics, Vol.67, No.1, pp. 41-54, 2008.
- [6] B. Schölkopf, D. Janzing, J. Peters, E. Sgouritsa, K. Zhang, and J. Mooij, “On causal and anticausal learning,” Proc. of the 29th Int. Conf. on Machine Learning, pp. 459-466, 2012.
- [7] J. Song, S. Oyama, and M. Kurihara, “A framework for crowd-based causal analysis of open data,” Proc. of 2018 IEEE Int. Conf. on Systems, Man, and Cybernetics, pp. 2188-2193, 2018.
- [8] J. Pearl, “Causality: models, reasoning and inference,” Springer, 2000.
- [9] S. Shimizu, P. O. Hoyer, A. Hyvärinen, and A. Kerminen, “A linear non-Gaussian acyclic model for causal discovery,” J. of Machine Learning Research, Vol.7, pp. 2003-2030, 2006.
- [10] A. Hyvärinen, K. Zhang, S. Shimizu, and P. O. Hoyer, “Estimation of a structural vector autoregression model using non-Gaussianity,” J. of Machine Learning Research, Vol.11, pp. 1709-1731, 2010.
- [11] P. O. Hoyer, S. Shimizu, A. J. Kerminen, and M. Palviainen, “Estimation of causal effects using linear non-Gaussian causal models with hidden variables,” Int. J. of Approximate Reasoning, Vol.49, No.2, pp. 362-378, 2008.
- [12] S. Shimizu, T. Inazumi, Y. Sogawa, A. Hyvärinen, Y. Kawahara, T. Washio, P. O. Hoyer, and K. Bollen, “DirectLiNGAM: A direct method for learning a linear non-Gaussian structural equation model,” J. of Machine Learning Research, Vol.12, pp. 1225-1248, 2011.
- [13] S. Shimizu and K. Bollen, “Bayesian estimation of causal direction in acyclic structural equation models with individual-specific confounder variables and non-Gaussian distributions,” J. of Machine Learning Research, Vol.15, No.1, pp. 2629-2652, 2014.
- [14] K. Zhang and L.-W. Chan, “Extensions of ICA for causality discovery in the Hong Kong stock market,” Int. Conf. on Neural Information Processing, pp. 400-409, 2006.
- [15] K. Zhang and A. Hyvärinen, “Distinguishing causes from effects using nonlinear acyclic causal models,” Proc. of the 2008 Int. Conf. on Causality: Objectives and Assessment, pp. 157-164, 2008.
- [16] K. Zhang and A. Hyvärinen, “On the identifiability of the post-nonlinear causal model,” Proc. of the 25th Conf. on Uncertainty in Artificial Intelligence, pp. 647-655, 2009.
- [17] K. Zhang, Z. Wang, and B. Schölkopf, “On estimation of functional causal models: post-nonlinear causal model as an example,” Proc. of IEEE 13th Int. Conf. on Data Mining Workshops, pp. 139-146, 2013.
- [18] D. Janzing, J. Mooij, K. Zhang, J. Lemeire, J. Zscheischler, P. Daniušis, B. Steudel, and B. Schölkopf, “Information-geometric approach to inferring causal directions,” Artificial Intelligence, Vol.182-183, pp. 1-31, 2012.
- [19] J. Song, S. Oyama, and M. Kurihara, “Tell cause from effect: models and evaluation,” Int. J. of Data Science and Analytics, Vol.4, No.2, pp. 99-112, 2017.
- [20] L. Duan, S. Oyama, H. Sato, and M. Kurihara, “Multi-emotion estimation in narratives from crowdsourced annotations,” Proc. of the 15th ACM/IEEE-CS Joint Conf. on Digital Libraries, pp. 91-100, 2015.
- [21] J. Wang, S. Oyama, M. Kurihara, and H. Kashima, “Learning an accurate entity resolution model from crowdsourced labels,” Proc. of the 8th Int. Conf. on Ubiquitous Information Management and Communication, Article No.103, 2014.
- [22] G. Demartini, B. Trushkowsky, T. Kraska, and M. J. Franklin, “CrowdQ: crowdsourced query understanding,” Proc. of the 6th Biennial Conf. on Innovative Data Systems Research, 2013.
- [23] S. Oyama, Y. Baba, I. Ohmukai, H. Dokoshi, and H. Kashima, “Crowdsourcing chart digitizer: task design and quality control for making legacy open data machine-readable,” Int. J. of Data Science and Analytics, Vol.2, No.1-2, pp. 45-60, 2016.
- [24] S. Egami, T. Kawamura, K. Kozaki, and A. Ohsuga, “Construction of linked urban problem data with causal relations using crowdsourcing,” Proc. of 2017 IIAI Int. Congress on Advanced Applied Informatics, pp. 814-819, 2017.
- [25] S. Egami, T. Kawamura, Y. Sei, Y. Tahara, and A. Ohsuga, “Schema Design of Illegally Parked Bicycles LOD,” Proc. of 2016 IIAI Int. Congress on Advanced Applied Informatics, pp. 692-697, 2016.
- [26] W. Willett, J. Heer, and M. Agrawala, “Strategies for crowdsourcing social data analysis,” Proc. of the SIGCHI Conf on Human Factors in Computing Systems, pp. 227-236, 2012.
- [27] J. C. Bongard, P. D. H. Hines, D. Conger, P. Hurd, and Z. Lu, “Crowdsourcing predictors of behavioral outcomes,” IEEE Trans. on Systems, Man, and Cybernetics: Systems, Vol.43, No.1, pp. 176-185, 2013.
- [28] K. E. Bevelander, K. Kaipainen, R. Swain, S. Dohle, J. C. Bongard, P. D. Hines, and B. Wansink, “Crowdsourcing novel childhood predictors of adult obesity,” PLoS One, Vol.9, No.2, e87756, 2014.
- [29] X. Liu, M. Lu, B. C. Ooi, Y. Shen, S. Wu, and M. Zhang, “CDAS: a crowdsourcing data analytics system,” Proc. of the VLDB Endowment, Vol.5, No.10, pp. 1040-1051, 2012.
- [30] A. Holzinger, “Human-Computer Interaction and Knowledge Discovery (HCI-KDD): What is the benefit of bringing those two fields to work together?,” Int. Conf. on Availability, Reliability, and Security, pp. 319-328, 2013.
- [31] A. Holzinger, “Interactive machine learning for health informatics: when do we need the human-in-the-loop?,” Brain Informatics, Vol.3, No.2, pp. 119-131, 2016.
- [32] T. Inui, K. Inui, and Y. Matsumoto, “Acquiring causal knowledge from text using the connective marker tame,” ACM Trans. on Asian Language Information Processing (TALIP), Vol.4, No.4, pp. 435-474, 2005.
- [33] M. Hoffman, F. R. Bach, and D. M. Blei, “Online learning for latent Dirichlet allocation,” Advances in Neural Information Processing Systems, pp. 856-864, 2010.
- [34] T. Kudo and Y. Matsumoto, “Japanese dependency analysis using cascaded chunking,” Proc. of the 6th Conf. on Natural Language Learning, Vol.20, pp. 1-7, 2002.
- [35] D. M. Blei and J. D. Lafferty, “Correlated topic models,” Proc. the 18th Int. Conf. on Neural Information Processing Systems, pp. 147-154, 2005.
- [36] J. Song, S. Oyama, and M. Kurihara, “Identification of possible common causes by intrinsic dimension estimation,” Proc. of the 6th IEEE Int. Conf. on Big Data and Smart Computing, 2019.
- [37] K. Zhang, J. Peters, D. Janzing, and B. Schölkopf, “Kernel-based conditional independence test and application in causal discovery,” Proc. of the 27th Conf. on Uncertainty in Artificial Intelligence, pp. 804-813, 2011.
- [38] S. A. Andersson, D. Madigan, and M. D. Perlman, “A characterization of Markov equivalence classes for acyclic digraphs,” The Annals of Statistics, Vol.25, No.2, pp. 505-541, 1997.
- [39] J. A. Lee and M. Verleysen, “Nonlinear dimensionality reduction,” Springer, 2007.
- [40] P. Grassberger and I. Procaccia, “Measuring the strangeness of strange attractors,” The Theory of Chaotic Attractors, pp. 170-189, Springer, 2004.
- [41] A. Kraskov, H. Stögbauer, and P. Grassberger, “Estimating mutual information,” Physical Review E, Vol.69, No.6, Article No.066138, 2004.
- [42] D. Coondoo and S. Dinda, “Causality between income and emission: a country group-specific econometric analysis,” Ecological Economics, Vol.40, No.3, pp. 351-367, 2002.
- [43] R. Guha, R. McCool, and E. Miller, “Semantic search,” Proc. of the 12th Int. Conf. on World Wide Web, pp. 700-709, 2003.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.