Short Paper:
Massive Data Mining Algorithm for Web Text Based on Clustering Algorithm
Nan-Chao Luo
School of Mathematics and Computer Science, Aba Teachers University
Wenchuan, Sichuan 623002, China

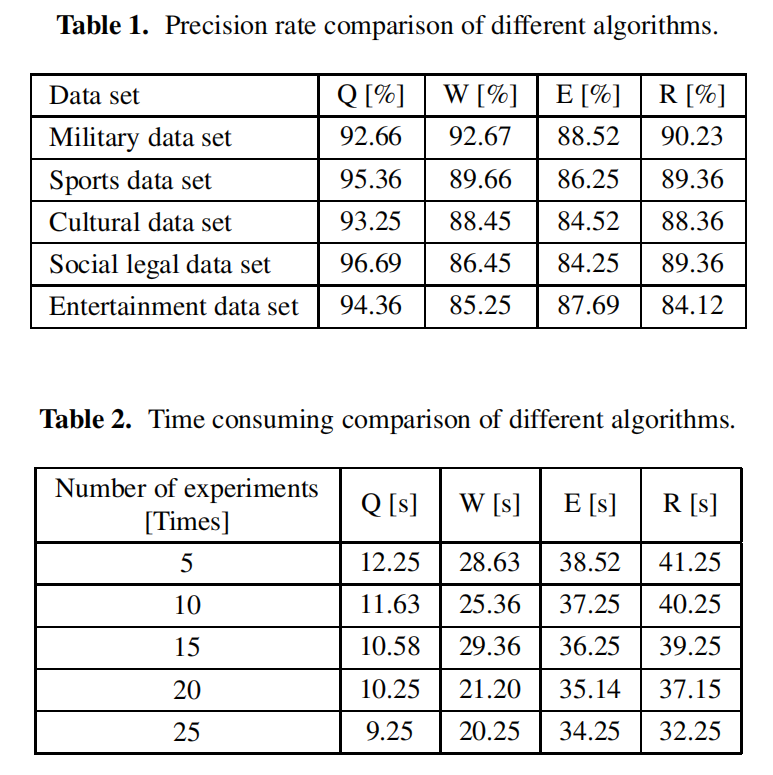
The massive data of Web text has the characteristics of high dimension and sparse spatial distribution, which makes the problems of low mining precision and long time consuming in the process of mining mass data of Web text by using the current data mining algorithms. To solve these problems, a massive data mining algorithm of Web text based on clustering algorithm is proposed. By using chi square test, the feature words of massive data are extracted and the set of characteristic words is gotten. Hierarchical clustering of feature sets is made, TF-IDF values of each word in clustering set are calculated, and vector space model is constructed. By introducing fair operation and clone operation on bee colony algorithm, the diversity of vector space models can be improved. For the result of the clustering center, K-means is introduced to extract the local centroid and improve the quality of data mining. Experimental results show that the proposed algorithm can effectively improve data mining accuracy and time consuming.
Clustering convergence is better
- [1] K.-W. Pang and H.-L. Chan, “Data mining-based algorithm for storage location assignment in a randomised warehouse,” Int. J. of Production Research, Vol.55, No.14, pp. 4035-4052, 2016.
- [2] E. R. Faria et al., “Minas: multiclass learning algorithm for novelty detection in data streams,” Data Mining and Knowledge Discovery, Vol.30, No.3, pp. 640-680, 2016.
- [3] G. Yang, Y. Zhang, J. Yang, et al., “Automated classification of brain images using wavelet-energy and biogeography-based optimization,” Multimedia Tools & Applications, Vol.75, No.23, pp. 15601-15617, 2016.
- [4] D.-S. Pan, “Research on Fuzzy Mining Algorithm for Massive Text Data Under Uncertain Noise,” Microelectronics & Computer, Vol.34, No.9, pp. 129-132, 2017.
- [5] K. Arasawa and S. Hattori, “Automatic Baseball Video Tagging Based on Voice Pattern Prioritization and Recursive Model Localization,” J. Adv. Comput. Intell. Intell. Inform., Vol.21, No.7, pp. 1262-1279, 2017.
- [6] Y. Liu, B. Liu, and F. Wang, “Optimization algorithm for big data mining based on parameter server framework,” J. of Shandong University (Engineering Science), Vol.47, No.4, pp. 1-6. 2017.
- [7] G. Yang, X. Deng, and C. Liu, “Facial expression recognition model based on deep spatiotemporal convolutional neural networks,” Zhongnan Daxue Xuebao (Ziran Kexue Ban) / J. of Central South University (Science and Technology), Vol.47, No.7, pp. 2311-2319, 2016.
- [8] X. Zhang, X. Meng, X. Yang et al. “Singular value decomp osition ghost imaging,” Optics Express, Vol.26, No.10, p. 12948, 2018.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.