Paper:
Long-Term Ensemble Learning for Cross-Season Visual Place Classification
Xiaoxiao Fei, Kanji Tanaka, Yichu Fang, and Akitaka Takayama
University of Fukui
3-9-1 Bunkyo, Fukui, Fukui 910-8507, Japan

This paper addresses the problem of cross-season visual place classification (VPC) from the novel perspective of long-term map learning. Our goal is to enable transfer learning efficiently from one season to the next, at a small constant cost, and without wasting the robot’s available long-term-memory by memorizing very large amounts of training data. To achieve a good tradeoff between generalization and specialization abilities, we employ an ensemble of deep convolutional neural network (DCN) classifiers and consider the task of scheduling (when and which classifiers to retrain), given a previous season’s DCN classifiers as the sole prior knowledge. We present a unified framework for retraining scheduling and we discuss practical implementation strategies. Furthermore, we address the task of partitioning a robot’s workspace into places to define place classes in an unsupervised manner, as opposed to using uniform partitioning, so as to maximize VPC performance. Experiments using the publicly available NCLT dataset revealed that retraining scheduling of a DCN classifier ensemble is crucial in achieving a good balance between generalization and specialization. Additionally, it was found that the performance is significantly improved when using planned scheduling.
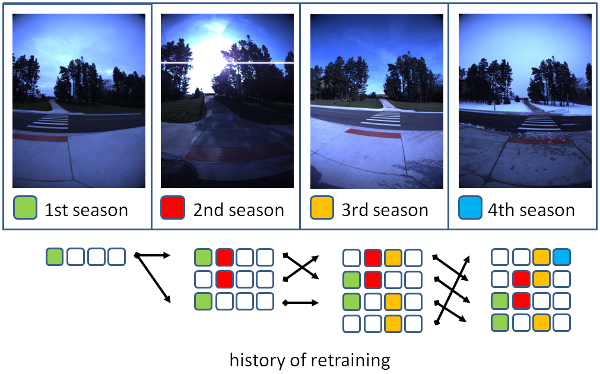
Long-term ensemble classifier learning
- [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems, pp. 1097-1105, 2012.
- [2] T. Naseer, L. Spinello, W. Burgard, and C. Stachniss, “Robust visual robot localization across seasons using network flows,” 28th AAAI Conf. on Artificial Intelligence, 2014.
- [3] S. Chopra, S. Balakrishnan, and R. Gopalan, “Dlid: Deep learning for domain adaptation by interpolating between domains,” ICML Workshop on Challenges in Representation Learning, Vol.2, 2013.
- [4] C. Elkan and K. Noto, “Learning classifiers from only positive and unlabeled data,” Proc. of the 14th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, pp. 213-220, 2008.
- [5] G. Fei, S. Wang, and B. Liu, “Learning Cumulatively to Become More Knowledgeable.,” Proc. of the 22nd ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, pp. 1565-1574, 2016.
- [6] I. Kuzborskij, F. Orabona, and B. Caputo, “Scalable greedy algorithms for transfer learning,” Computer Vision and Image Understanding, Vol.156, pp. 174-185, 2017.
- [7] M. Oquab, L. Bottou, I. Laptev, and J. Sivic, “Learning and transferring mid-level image representations using convolutional neural networks,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 1717-1724, 2014.
- [8] V. M. Patel, R. Gopalan, R. Li, and R. Chellappa, “Visual domain adaptation: A survey of recent advances,” IEEE Signal Processing Magazine, Vol.32, No.3, pp. 53-69, 2015.
- [9] K. Saenko, B. Kulis, M. Fritz, and T. Darrell, “Adapting visual category models to new domains,” Computer Vision-ECCV 2010, pp. 213-226, 2010.
- [10] S. Thrun, “Is learning the n-th thing any easier than learning the first?,” Advances in Neural Information Processing Systems, pp. 640-646, 1996.
- [11] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?,” Advances in Neural Information Processing Systems, pp. 3320-3328, 2014.
- [12] A. Masatoshi, C. Yuuto, T. Kanji, and Y. Kentaro, “Leveraging image-based prior in cross-season place recognition,” IEEE Int. Conf. on Robotics and Automation (ICRA 2015), pp. 5455-5461, 2015.
- [13] T. Kanji, “Self-localization from images with small overlap,” IEEE/RSJ Int. Conf. on, Intelligent Robots and Systems (IROS 2016), pp. 4497-4504, 2016.
- [14] X. Fei, T. Kanji, I. Kouya, and G. Hao, “Unsupervised place discovery for visual place classification,” 15th IAPR Int. Conf. on Machine Vision Applications (MVA 2017), pp. 109-112, 2017.
- [15] N. Carlevaris-Bianco, A. K. Ushani, and R. M. Eustice, “University of Michigan North Campus long-term vision and lidar dataset,” The Int. J. of Robotics Research, Vol.35, No.9, pp. 1023-1035, 2016.
- [16] A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” Proc. of the IEEE Int. Conf. on Computer Vision, pp. 2938-2946, 2015.
- [17] D. Massiceti, A. Krull, E. Brachmann, C. Rother, and P. H. Torr, “Random forests versus Neural Networks?What’s best for camera localization?,” IEEE Int. Conf. on Robotics and Automation (ICRA 2017), pp. 5118-5125, 2017.
- [18] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon, “Scene coordinate regression forests for camera relocalization in RGB-D images,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 2930-2937, 2013.
- [19] R. Arroyo, P. F. Alcantarilla, L. M. Bergasa, and E. Romera, “Are you ABLE to perform a life-long visual topological localization?,” Autonomous Robots, pp. 1-21, 2017.
- [20] E. Gavves, T. Mensink, T. Tommasi, C. G. Snoek, and T. Tuytelaars, “Active transfer learning with zero-shot priors: Reusing past datasets for future tasks,” Proc. of the IEEE Int. Conf. on Computer Vision, pp. 2731-2739, 2015.
- [21] R. Arroyo, P. F. Alcantarilla, L. M. Bergasa, and E. Romera, “Fusion and binarization of CNN features for robust topological localization across seasons,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS 2016), pp. 4656-4663, 2016.
- [22] G. Csurka, B. Chidlowskii, S. Clinchant, and S. Michel, “Unsupervised domain adaptation with regularized domain instance denoising,” Computer Vision-ECCV 2016 Workshops, pp. 458-466, 2016.
- [23] N. Srivastava and R. R. Salakhutdinov, “Discriminative transfer learning with tree-based priors,” Advances in Neural Information Processing Systems, pp. 2094-2102, 2013.
- [24] M. Mancini, S. R. Bulo, E. Ricci, and B. Caputo, “Learning Deep NBNN Representations for Robust Place Categorization,” IEEE Robotics and Automation Letters, 2017.
- [25] Z. Chen, F. Maffra, I. Sa, and M. Chli, “Only Look Once, Mining Distinctive Landmarks from ConvNet for Visual Place Recognition,” IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS 2017), 2017.
- [26] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [27] J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 4104-4113, 2016.
- [28] Y. Latif, C. Cadena, and J. Neira, “Robust loop closing over time for pose graph SLAM,” The Int. J. of Robotics Research, Vol.32, No.14, pp. 1611-1626, 2013.
- [29] A. Babenko, A. Slesarev, A. Chigorin, and V. Lempitsky, “Neural codes for image retrieval,” European Conf. on Computer Vision, pp. 584-599, 2014.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.