Paper:
Demand Forecasting for Petrol Products in Gas Stations Using Clustering and Decision Tree
Lijun Sun†, Xiuwu Xing, Yaxian Zhou, and Xiangpei Hu
Institute of Systems Engineering, Dalian University of Technology
No.2 Linggong Road, Ganjingzi District, Dalian City, Liaoning Province 116024, China
†Corresponding author

Demand forecasting for petrol products in gas stations is crucial to the planning of initiative distribution of petrol products, especially to the stability of product supply in petroleum companies. In this paper, a novel scheme of demand forecasting based on clustering and a decision tree is proposed, which uses a decision tree and integrates the results of clustering validity indices. First, the proposed scheme uses a k-means algorithm to divide the sales data into multiple disjointed clusters, evaluates the clustering result of the daily sales curve of a product according to seven validity indices and determines the optimal number of clustering. Next, the relationship between the sales pattern and the relevant influence factors is described using a decision tree, which can categorize a future day’s sales pattern with these factors into the most suitable cluster to predict the quantity of the demand and the peak demand time windows for each gas station. Finally, three months’ worth of sales data is collected from a gas station in Dalian city, China, to illustrate the proposed forecasting scheme. Experimental results demonstrate that the scheme is an effective alternative for the demand forecasting for petrol products because it outperforms three other selected methods.
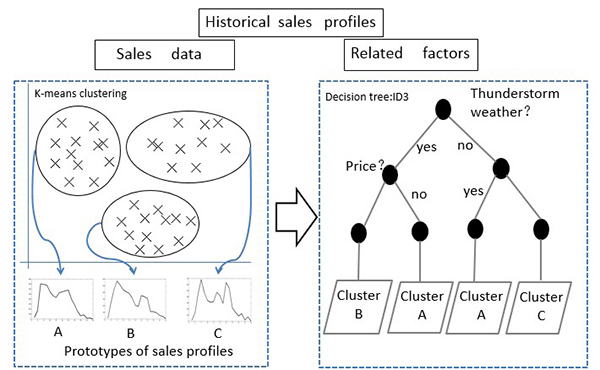
The proposed forecasting scheme based on clustering and the decision tree
- [1] K. L. López et al., “Training subset selection in hourly Ontario energy price forecasting using time series clustering-based stratification,” Neurocomputing, Vol.156, No.21, pp. 268-279, 2015.
- [2] C. Lu and L. Kao, “A clustering-based sales forecasting scheme by using extreme learning machine and ensembling linkage methods with applications to computer server,” Eng Appl of Artif Intel, Vol.55, pp. 231-238, 2016.
- [3] A. Prinzie and V. D. P. Dirk, “Incorporating sequential information into traditional classification models by using an element/position-sensitive SAM,” Decis Support Syst, Vol.42, No.2, pp. 508-562, 2006.
- [4] C. J. Lu and Y. W. Wang, “Combining independent component analysis and growing hierarchical self-organizing maps with support vector regression in product demand forecasting,” Int J. Prod. Econ, Vol.128, No.2, pp. 603-613, 2010.
- [5] F. E. H. Tay and L. J. Cao, “Improved financial time series forecasting by combining Support Vector Machines with self-organizing feature map,” Intell Data Ana, Vol.5, No.4, pp. 339-354, 2001.
- [6] K. Venkatesh et al., “Cash demand forecasting in ATMs by clustering and neural networks,” Eur J. Oper Res, Vol.232, No.2, pp. 383-392, 2014.
- [7] R. K. Lai et al., “Evolving and clustering fuzzy decision tree for financial time series data forecasting,” Expert Syst Appl, Vol.36, No.2, pp. 3761-3773, 2009.
- [8] S. B. Kotsiantis, “Supervised Machine Learning: A review of classification techniques,” Procs. of the Conf. on Emerging Artificial Intelligence Applications in Computer Engineering: Real Word AI Systems with Applications in eHealth, HCI, Information Retrieval and Pervasive Technologies, 2007, pp. 3-24 .
- [9] S. Aghabozorgi, A. S. Shirkhorshidi, and T. Y. Wah, “Time-series clustering- A decade review,” Inform Syst, Vol.53, pp. 16-38, 2015.
- [10] M. Galar et al., “A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches,” IEEE T Syst Man Cy C, Vol.42, No.4, pp. 463-484, 2012.
- [11] R. K. Shahzad and N. Lavesson, “Comparative analysis of voting schemes for ensemble-based malware detection,” JoWUA, Vol.4, pp. 98-117, 2013.
- [12] K. Yeon et al., “Model averaging via penalized regression for tracking concept drift,” J. Comput Graph Stat, Vol.19, No.2, pp. 457-473, 2010.
- [13] L. Lam and C. Y. Suen, “Application of majority voting to pattern recognition: an analysis of its behavior and performance,” IEEE T Syst Man Cy A, Vol.27, No.5, pp. 553-568, 1997.
- [14] O. Arbelaitz et al., “An extensive comparative study of cluster validity indices,” Pattern Recogn, Vol.46, No.1, pp. 243-256, 2013.
- [15] H. Niu et al., “Exploiting human mobility patterns for gas station site selection,” Procs. of the Int. Conf. on Database Systems for Advanced Applications, 2016, pp. 242-257.
- [16] T. Y. Chan, V. Padmanabhan, and P. B. Seetharaman, “An econometric model of location and pricing in the gasoline market,” J. Marketing Res, Vol.44, No.4, pp. 622-635, 2007.
- [17] F. Zhang et al., “Sensing the pulse of urban refueling behavior: a perspective from taxi mobility,” ACM Intell Syst & Tech, Vol.6, No.3, p. 37, 2015.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.