Paper:
Object-Oriented 3D Semantic Mapping Based on Instance Segmentation
Jinxin Chi, Hao Wu, and Guohui Tian
School of Control Science and Engineering, Shandong University
No.17923 Jingshi Road, Lixia District, Jinan, Shandong 250061, China

Service robots gain both geometric and semantic information about the environment with the help of semantic mapping, providing more intelligent services. However, a majority of studies for semantic mapping thus far require priori knowledge 3D object models or maps with a few object categories that neglect separate individual objects. In view of these problems, an object-oriented 3D semantic mapping method is proposed by combining state-of-the-art deep-learning-based instance segmentation and a visual simultaneous localization and mapping (SLAM) algorithm, which helps robots not only gain navigation-oriented geometric information about the surrounding environment, but also obtain individually-oriented attribute and location information about the objects. Meanwhile, an object recognition and target association algorithm applied to continuous image frames is proposed by combining visual SLAM, which uses visual consistency between image frames to promote the result of object matching and recognition over continuous image frames, and improve the object recognition accuracy. Finally, a 3D semantic mapping system is implemented based on Mask R-CNN and ORB-SLAM2 frameworks. A simulation experiment is carried out on the ICL-NUIM dataset and the experimental results show that the system can generally recognize all the types of objects in the scene and generate fine point cloud models of these objects, which verifies the effectiveness of our algorithm.
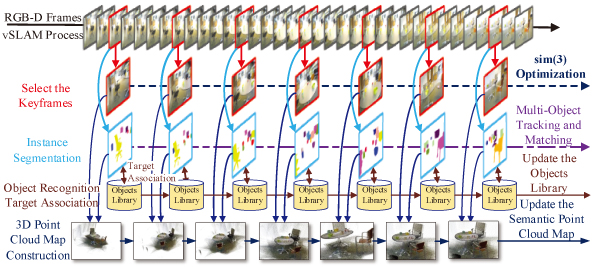
Object-oriented semantic mapping
- [1] K. He, G. Gkioxari, and P. Dollär, “Mask R-CNN,” IEEE Int. Conf. Computer Vision (ICCV 2017), pp. 2980-2988, 2017.
- [2] R. Mur-Artal and J. D. Tardós, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE Trans. on Robotics, Vol.33, No.5, pp. 1255-1262, 2017.
- [3] K. Tanaka, M. Ando, and Y. Inagaki, “Bag-of-Bounding-Boxes: An Unsupervised Approach for Object-Level View Image Retrieval,” J. Adv. Comput. Intell. Intell. Inform., Vol.18, No.5, pp. 784-791, 2014.
- [4] J. Woo and N. Kubota, “Recognition of indoor environment by robot partner using conversation,” J. Adv. Comput. Intell. Intell. Inform., Vol.17, No.5, pp. 753-760, 2013.
- [5] T. Saitoh and Y. Kuroda, “Self-Supervised Mapping for Road Shape Estimation Using Laser Remission in Urban Environments,” J. Robot. Mechatron., Vol.22, No.6, p. 726, 2010.
- [6] A. Sujiwo, T. Ando, E. Takeuchi et al., “Monocular vision-based localization using ORB-SLAM with LiDAR-aided mapping in real-world robot challenge,” J. Robot. Mechatron., Vol.28, No.4, pp. 479-490, 2016.
- [7] S. Y. Bao, M. Bagra, Y. W. Chao et al., “Semantic structure from motion with points, regions, and objects,” Computer Vision and Pattern Recognition (CVPR 2012), pp. 2703-2710, 2012.
- [8] C. Zhao, L. Sun, P. Purkait et al., “Dense RGB-D semantic mapping with Pixel-Voxel neural network,” arXiv preprint, arXiv:1710.00132, 2017.
- [9] J. McCormac, A. Handa, A. Davison et al., “SemanticFusion: Dense 3D semantic mapping with convolutional neural networks,” IEEE Int. Conf. on Robotics and Automation, Sands Expo and Convention Centre, pp. 4628-4635, 2017.
- [10] T. Whelan, R. F. Salas-Moreno, B. Glocker et al., “ElasticFusion: Real-time dense SLAM and light source estimation,” The Int. J. of Robotics Research, Vol.35, No.14, pp. 1697-1716, 2016.
- [11] X. Li and R. Belaroussi, “Semi-dense 3d semantic mapping from monocular SLAM,” arXiv preprint, arXiv:1611.04144, 2016.
- [12] J. Civera, D. Gálvez-López, L. Riazuelo et al., “Towards semantic SLAM using a monocular camera,” Intelligent Robots and Systems (IROS 2011), pp. 1277-1284, 2011.
- [13] D. Gálvez-López, M. Salas, J. D. Tardós et al., “Real-time monocular object SLAM,” Robotics & Autonomous Systems, Vol.75, pp. 435-449, 2016.
- [14] R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat et al., “SLAM++: Simultaneous localisation and mapping at the level of objects,” Computer Vision and Pattern Recognition (CVPR 2013), pp. 1352-1359, 2013.
- [15] S. Aoyagi, N. Hattori, A. Kohama et al., “Object Detection and Recognition Using Template Matching with SIFT Features Assisted by Invisible Floor Marks,” J. Robot. Mechatron. Vol.21, No.6, p. 689, 2009.
- [16] J. Dai, K. He, and J. Sun, “Instance-aware semantic segmentation via multi task network cascades,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 3150-3158, 2016.
- [17] Y. Li, H. Qi, J. Dai et al., “Fully convolutional instance-aware semantic segmentation,” IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 2017), pp. 2359-2367, 2017.
- [18] A. Handa, T. Whelan, J. McDonald et al., “A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM,” Robotics and Automation (ICRA 2014), pp. 1524-1531, 2014.
- [19] T. Y. Lin, M. Maire, S. Belongie et al., “Microsoft coco: Common objects in context,” European Conf. on Computer Vision, Springer, pp. 740-755, 2014.
- [20] S. Ren, K. He, R. Girshick et al., “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Trans. on Pattern Analysis & Machine Intelligence, Vol.39, No.6, pp. 1137-1149, 2017.
- [21] S. Pillai and J. Leonard, “Monocular SLAM Supported Object Recognition,” Computer Science, 2015.
- [22] J. Engel, T. Schöps, and D. Cremers, “LSD-SLAM: Large-Scale Direct Monocular SLAM,” European Conference on Computer Vision (ECCV 2014), Vol.8690, pp. 834-849, 2014.
- [23] K. Lai, L. Bo, X. Ren, and D. Fox, “A large-scale hierarchical multi view RGB-D object dataset,” Proc. IEEE Int. Conf. on Robotics and Automation (ICRA), 2011.
- [24] J. Sivic and A. Zisserman, “Video google: A text retrieval approach to object matching in videos,” Proc. Int. Conf. on Computer Vision (ICCV), 2003.
- [25] G. Tolias, R. Sicre, and H. Jégou, “Particular object retrieval with integral max-pooling of cnn activations,” Int. Conf. on Learning Representations (ICLR2016), 2016.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.