Research Paper:
Infrared and Visible Image Fusion with Overlapped Window Transformer
Xingwang Liu†, Bemnet Wondimagegnehu Mersha, Kaoru Hirota, and Yaping Dai
School of Automation, Beijing Institute of Technology
No.5 Zhongguancun South Street, Haidian District, Beijing 100081, China
†Corresponding author

An overlap window-based transformer is proposed for infrared and visible image fusion. A multi-head self-attention mechanism based on overlapping windows is designed. By introducing overlapping regions between windows, local features can interact across different windows, avoiding the discontinuity and information isolation issues caused by non-overlapping partitions. The proposed model is trained using an unsupervised loss function composed of three terms: pixel, gradient, and structural loss. With the end-to-end model and the unsupervised loss function, our method eliminates the need to manually design complex activity-level measurements and fusion strategies. Extensive experiments on the public TNO (grayscale) and RoadScene (RGB) datasets demonstrate that the proposed method achieves the expected long-distance dependency modeling capabilities when fusing infrared and visible images, as well as the positive results in both qualitative and quantitative evaluations.
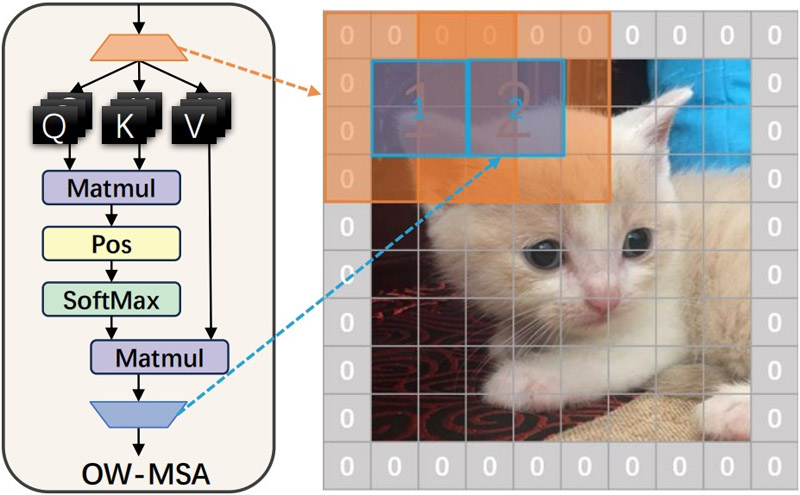
The proposed overlapped window-based multi-head self-attention
- [1] K. Meng, C. Chen, T. Wu, B. Xin, M. Liang, and F. Deng, “Evolutionary state estimation-based multi-strategy jellyfish search algorithm for multi-uav cooperative path planning,” IEEE Trans. on Intelligent Vehicles, pp. 1-19, 2024. https://doi.org/10.1109/tiv.2024.3378195
- [2] B. Meher, S. Agrawal, R. Panda, and A. Abraham, “A survey on region based image fusion methods,” Information Fusion, Vol.48, pp. 119-132, 2019. https://doi.org/10.1016/j.inffus.2018.07.010
- [3] J. Chen, X. Li, L. Luo, X. Mei, and J. Ma, “Infrared and visible image fusion based on target-enhanced multiscale transform decomposition,” Information Sciences, Vol.508, pp. 64-78, 2020. https://doi.org/10.1016/j.ins.2019.08.066
- [4] Y. Yang, Y. Zhang, S. Huang, Y. Zuo, and J. Sun, “Infrared and visible image fusion using visual saliency sparse representation and detail injection model,” IEEE Trans. on Instrumentation and Measurement, Vol.70, pp. 1-15, 2021. https://doi.org/10.1109/tim.2020.3011766
- [5] L. Li, M. Lv, Z. Jia, and H. Ma, “Sparse representation-based multi-focus image fusion method via local energy in shearlet domain,” Sensors, Vol.23, No.6, Article No.2888, 2023. https://doi.org/10.3390/s23062888
- [6] J. Ma, Z. Zhou, B. Wang, and H. Zong, “Infrared and visible image fusion based on visual saliency map and weighted least square optimization,” Infrared Physics and Technology, Vol.82, pp. 8-17, 2017. https://doi.org/10.1016/j.infrared.2017.02.005
- [7] W. Tang, F. He, Y. Liu, Y. Duan, and T. Si, “Datfuse: Infrared and visible image fusion via dual attention transformer,” IEEE Trans. on Circuits and Systems for Video Technology, Vol.33, No.7, pp. 3159-3172, 2023. https://doi.org/10.1109/tcsvt.2023.3234340
- [8] J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, and Y. Ma, “Swinfusion: Cross-domain long-range learning for general image fusion via swin transformer,” IEEE/CAA J. of Automatica Sinica, Vol.9, No.7, pp. 1200-1217, 2022. https://doi.org/10.1109/jas.2022.105686
- [9] F. Zuo, Y. Huang, Q. Li, and W. Su, “Infrared and visible image fusion using multi-scale pyramid network,” Int. J. of Wavelets, Multiresolution and Information Processing, Vol.20, No.05, 2022. https://doi.org/10.1142/s0219691322500199
- [10] H. Zhang, H. Xu, Y. Xiao, X. Guo, and J. Ma, “Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.07, pp. 12797-12804, 2020. https://doi.org/10.1609/aaai.v34i07.6975
- [11] J. Ma, L. Tang, M. Xu, H. Zhang, and G. Xiao, “Stdfusionnet: An infrared and visible image fusion network based on salient target detection,” IEEE Trans. on Instrumentation and Measurement, Vol.70, pp. 1-13, 2021. https://doi.org/10.1109/tim.2021.3075747
- [12] L. Tang, J. Yuan, and J. Ma, “Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network,” Information Fusion, Vol.82, pp. 28-42, 2022. https://doi.org/10.1016/j.inffus.2021.12.004
- [13] H. Li, Y. Cen, Y. Liu, X. Chen, and Z. Yu, “Different input resolutions and arbitrary output resolution: A meta learning-based deep framework for infrared and visible image fusion,” IEEE Trans. on Image Processing, Vol.30, pp. 4070-4083, 2021. https://doi.org/10.1109/tip.2021.3069339
- [14] H. Li and X.-J. Wu, “Densefuse: A fusion approach to infrared and visible images,” IEEE Trans. on Image Processing, Vol.28, No.5, pp. 2614-2623, 2019. https://doi.org/10.1109/tip.2018.2887342
- [15] H. Li, X.-J. Wu, and J. Kittler, “Rfn-nest: An end-to-end residual fusion network for infrared and visible images,” Information Fusion, Vol.73, pp. 72-86, 2021. https://doi.org/10.1016/j.inffus.2021.02.023
- [16] Z. Wang, Y. Chen, W. Shao, H. Li, and L. Zhang, “Swinfuse: A residual swin transformer fusion network for infrared and visible images,” IEEE Trans. on Instrumentation and Measurement, Vol.71, pp. 1-12, 2022. https://doi.org/10.1109/tim.2022.3191664
- [17] X. Wu, Z.-H. Cao, T.-Z. Huang, L.-J. Deng, J. Chanussot, and G. Vivone, “Fully-connected transformer for multi-source image fusion,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.47, No.3, pp. 2071-2088, 2025. https://doi.org/10.1109/tpami.2024.3523364
- [18] B. Yang, Z. Jiang, D. Pan, H. Yu, G. Gui, and W. Gui, “Lfdt-fusion: A latent feature-guided diffusion transformer model for general image fusion,” SSRN, 2024. https://doi.org/10.2139/ssrn.4768805
- [19] Y. Zhang, Y. Liu, P. Sun, H. Yan, X. Zhao, and L. Zhang, “Ifcnn: A general image fusion framework based on convolutional neural network,” Information Fusion, Vol.54, pp. 99-118, 2020. https://doi.org/10.1016/j.inffus.2019.07.011
- [20] H. Li and X.-J. Wu, “Crossfuse: A novel cross attention mechanism based infrared and visible image fusion approach,” Information Fusion, Vol.103, Article No.102147, 2024. https://doi.org/10.1016/j.inffus.2023.102147
- [21] X. Liu, K. Hirota, Z. Jia, and Y. Dai, “A multi-autoencoder fusion network guided by perceptual distillation,” Information Sciences, Vol.606, pp. 1-20, 2022. https://doi.org/10.1016/j.ins.2022.05.018
- [22] H. Xu, J. Ma, J. Jiang, X. Guo, and H. Ling, “U2fusion: A unified unsupervised image fusion network,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.44, No.1, pp. 502-518, 2022. https://doi.org/10.1109/tpami.2020.3012548
- [23] C. Cheng, T. Xu, and X.-J. Wu, “Mufusion: A general unsupervised image fusion network based on memory unit,” Information Fusion, Vol.92, pp. 80-92, 2023. https://doi.org/10.1016/j.inffus.2022.11.010
- [24] S. Li, X. Kang, and J. Hu, “Image fusion with guided filtering,” IEEE Trans. on Image Processing, Vol.22, No.7, pp. 2864-2875, 2013. https://doi.org/10.1109/tip.2013.2244222
- [25] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Trans. on Image Processing, Vol.13, No.4, pp. 600-612, 2004. https://doi.org/10.1109/tip.2003.819861
- [26] Y. Han, Y. Cai, Y. Cao, and X. Xu, “A new image fusion performance metric based on visual information fidelity,” Information Fusion, Vol.14, No.2, pp. 127-135, 2013. https://doi.org/10.1016/j.inffus.2011.08.002
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.