Research Paper:
Predictive Inference Models for Real-World Physical Environments
Eri Kuroda†
 and Ichiro Kobayashi
and Ichiro Kobayashi
Ochanomizu University
2-1-1 Ohtsuka, Bunkyo-ku, Tokyo 112-8610, Japan
†Corresponding author

In recent years, artificial intelligence has become increasingly important for understanding the real world and the innate human ability to process intuitive physics with computers. Most research on real-world detection and prediction has used methods that generate predictive images of the environment from changes in the pixels of an image, or that predict changes in objects in the environment from changes in the numerical values of a physical simulator. However, the actual method of predicting the environment in humans is believed to consist of both visual and physical information. Therefore, in this study, in order to recognize the motion of objects, the relationship of motion characteristics between objects is represented by a graph structure, which enables the extraction of anomalous points in response to changes in the environment. Then, based on both visual and physical information, we constructed a change point prediction model that can predict the motion of objects in the environment and capture the timing of collisions between objects. Moreover, to improve the accuracy, the basic prediction model was modified and the accuracy of the model was compared. The results showed that visual information and physical information were inferred independently, and the more physical information included the physical properties of the objects, the higher the accuracy. In the change point prediction model, as the prediction accuracy of the base prediction model increased, the change point extraction accuracy also increased.
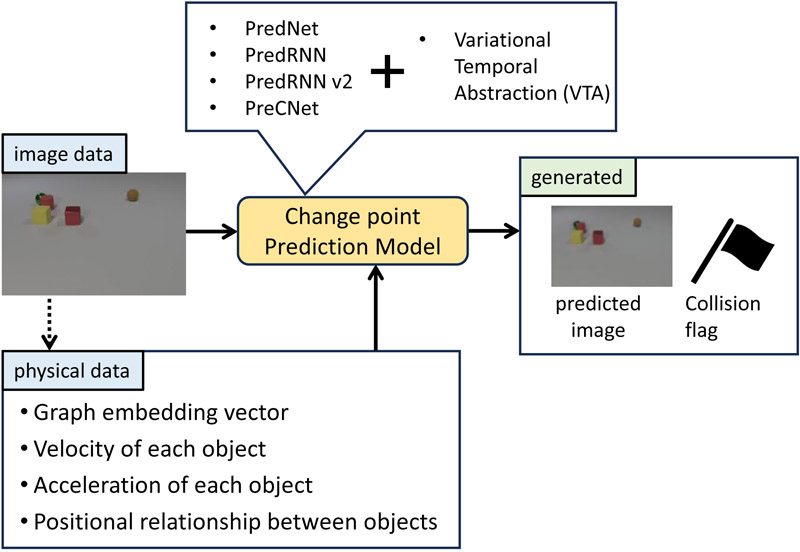
Overview of our research
- [1] D. Ha and J. Schmidhuber, “World models,” World Models, 2018. https://doi.org/10.5281/zenodo.1207631
- [2] Y. LeCun, “A path towards autonomous machine intelligence,” OpenReview.net, 2022.
- [3] X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.-C. Woo, “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” arXiv:1506.04214, 2015. https://doi.org/10.48550/arXiv.1506.04214
- [4] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger (Eds.), “Advances in Neural Information Processing Systems 25,” Curran Associates, Inc., pp. 1097-1105, 2012.
- [5] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, “Backpropagation applied to handwritten zip code recognition,” Neural Comput., Vol.1, No.4, pp. 541-551, 1989. https://doi.org/10.1162/neco.1989.1.4.541
- [6] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [7] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” 3rd Int. Conf. on Learning Representations (ICLR 2015), pp. 1-14. 2014.
- [8] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., Vol.9, No.8, pp. 1735-1780, 1997. https://doi.org/10.1162/neco.1997.9.8.1735
- [9] Y. Wang, M. Long, J. Wang, Z. Gao, and P. S. Yu, “PredRNN: Recurrent neural networks for predictive learning using spatiotemporal LSTMs,” Proc. of the 31st Int. Conf. on Neural Information Processing Systems, pp. 879-888, 2017. https://dl.acm.org/doi/10.5555/3294771.3294855
- [10] Y. Wang, Z. Gao, M. Long, J. Wang, and P. S. Yu, “PredRNN++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning,” Proc. of Machine Learning Research, pp. 5123-5132, 2018.
- [11] W. Lotter, G. Kreiman, and D. Cox, “Deep predictive coding networks for video prediction and unsupervised learning,” arXiv:1605.08104, 2016. https://doi.org/10.48550/arXiv.1605.08104
- [12] Z. Straka, T. Svoboda, and M. Hoffmann, “PreCNet: Next-Frame video prediction based on predictive coding,” IEEE Trans. Neural Networks and Learning Systems, Vol.35, No.8, pp. 10353-10367, 2023. https://doi.org/10.1109/TNNLS.2023.3240857
- [13] T. Kim, S. Ahn, and Y. Bengio, “Variational temporal abstraction,” Proc. of the 33rd Int. Conf. on Neural Information Processing Systems, pp. 11570-11579, 2019.
- [14] Y. Wang, H. Wu, J. Zhang, Z. Gao, J. Wang, P. S. Yu, and M. Long, “PredRNN: A recurrent neural network for spatiotemporal predictive learning,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.45, No.2, pp. 2208-2225, 2021. https://doi.org/10.1109/TPAMI.2022.3165153
- [15] Z. Chang, X. Zhang, S. Wang, S. Ma, and W. Gao, “STIP: A Spatio Temporal Information-Preserving and Perception-Augmented model for High-Resolution Video Prediction,” arXiv:2206.04381, 2022. https://doi.org/10.48550/arXiv.2206.04381
- [16] Z. Lin, M. Li, Z. Zheng, Y. Cheng, and C. Yuan, “Self-Attention ConvLSTM for spatiotemporal prediction,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.07, pp. 11531-11538, 2020. https://doi.org/10.1609/aaai.v34i07.6819
- [17] S. Lee, H. G. Kim, D. H. Choi, H.-I. Kim, and Y. M. Ro, “Video prediction recalling long-term motion context via memory alignment learning,” 2021 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 3053-3062, 2021. https://doi.org/10.1109/CVPR46437.2021.00307
- [18] M. Pan, X. Zhu, Y. Wang, and X. Yang, “Iso-Dream: Isolating and leveraging noncontrollable visual dynamics in world models,” Proc. of the 36th Int. Conf. on Neural Information Processing Systems, pp. 23178-23191, 2022. https://dl.acm.org/doi/10.5555/3600270.3601954
- [19] Z. Gao, C. Tan, L. Wu, and S. Z. Li, “SimVP: Simpler yet better video prediction,” 2022 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 3160-3170, 2022. https://doi.org/10.1109/CVPR52688.2022.00317
- [20] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv:2010.11929, 2020. https://doi.org/10.48550/arXiv.2010.11929
- [21] M. Ding, Z. Chen, T. Du, P. Luo, J. B. Tenenbaum, and C. Gan, “Dynamic visual reasoning by learning differentiable physics models from video and language,” Proc. of the 35th Int. Conf. on Neural Information Processing Systems, pp. 887-899, 2021. https://dl.acm.org/doi/10.5555/3540261.3540330
- [22] Z. Chen, K. Yi, Y. Li, M. Ding, A. Torralba, J. B. Tenenbaum, and C. Gan, “ComPhy: Compositional physical reasoning of objects and events from videos,” arXiv:2205.01089, 2022. https://doi.org/10.48550/arXiv.2205.01089
- [23] Q. Tang, X. Zhu, Z. Lei, and Z. Zhang, “Intrinsic physical concepts discovery with Object-Centric predictive models,” 2023 IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 23252-23261, 2023. https://doi.org/10.1109/CVPR52729.2023.02227
- [24] T. Ye, X. Wang, J. Davidson, and A. Gupta, “Interpretable intuitive physics model,” V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss (Eds.), “Computer Vision – ECCV 2018. Lecture Notes in Computer Science,” Vol.11216, Springer, 2018. https://doi.org/10.1007/978-3-030-01258-8_62018
- [25] L. S. Piloto, A. Weinstein, P. Battaglia, and M. Botvinick, “Intuitive physics learning in a deep-learning model inspired by developmental psychology,” Nat. Hum. Behav., Vol.6, No.9, pp. 1257-1267, 2022. https://doi.org/10.1038/s41562-022-01394-8
- [26] J. Johnson, B. Hariharan, L. van der Maaten, L. Fei-Fei, C. Lawrence Zitnick, and R. Girshick, “CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning,” 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 1988-1997, 2016. https://doi.org/10.1109/CVPR.2017.215
- [27] K. Yi, C. Gan, Y. Li, P. Kohli, J. Wu, A. Torralba, and J. B. Tenenbaum, “CLEVRER: CoLlision events for video REpresentation and reasoning,” arXiv:1910.01442, 2019. https://doi.org/10.48550/arXiv.1910.01442
- [28] J. Mao, X. Yang, X. Zhang, N. Goodman, and J. Wu, “CLEVRER-Humans: Describing physical and causal events the human way,” Proc. of the 36th Int. Conf. on Neural Information Processing Systems, pp. 7755-7768, 2022. https://dl.acm.org/doi/10.5555/3600270.3600833
- [29] J. Redmon and A. Farhadi, “YOLOv3: An incremental improvement,” arXiv:1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767
- [30] D. Bolya, C. Zhou, F. Xiao, and Y. J. Lee, “YOLACT: Real-time instance segmentation,” 2019 IEEE/CVF Int. Conf. on Computer Vision (ICCV), pp. 9156-9165, 2019. https://doi.org/10.1109/ICCV.2019.00925
- [31] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. Lawrence Zitnick, and P. Dollár, “Microsoft COCO: Common objects in context,” D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars (Eds.), “Computer Vision – ECCV 2014. Lecture Notes in Computer Science,” Vol.8693, Springer, pp. 740-755, 2014. https://doi.org/10.1007/978-3-319-10602-1_48
- [32] A. Mafla, S. Dey, A. F. Biten, L. Gomez, and D. Karatzas, “Multi-modal reasoning graph for scene-text based fine-grained image classification and retrieval,” 2021 IEEE Winter Conf. on Applications of Computer Vision (WACV), pp. 4023-4033, 2021. https://doi.org/10.1109/WACV48630.2021.00407
- [33] Y. Zhang, J. Gao, X. Yang, C. Liu, Y. Li, and C. Xu, “Find objects and focus on highlights: Mining object semantics for video highlight detection via graph neural networks,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.34, No.07, pp. 12902-12909, 2020. https://doi.org/10.1609/aaai.v34i07.6988
- [34] A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” Proc. of the 22nd ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, pp. 855-864, 2016. https://doi.org/10.1145/2939672.2939754
- [35] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv:1301.3781, 2013. https://doi.org/10.48550/arXiv.1301.3781
- [36] A. Narayanan, M. Chandramohan, R. Venkatesan, L. Chen, Y. Liu, and S. Jaiswal, “graph2vec: Learning distributed representations of graphs,” arXiv:1707.05005, 2017. https://doi.org/10.48550/arXiv.1707.05005
- [37] Q. V. Le and T. Mikolov, “Distributed representations of sentences and documents,” Proc. of the 31st Int. Conf. on Machine Learning, Vol.32, pp. II-1188-II-1196, 2014. https://dl.acm.org/doi/10.5555/3044805.3045025
- [38] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” Proc. of the 3rd Int. Conf. on Learning Representations (ICLR), 2017.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.