Paper:
Visual Navigation Based on Semantic Segmentation Using Only a Monocular Camera as an External Sensor
Ryusuke Miyamoto*, Miho Adachi**, Hiroki Ishida**, Takuto Watanabe**, Kouchi Matsutani**, Hayato Komatsuzaki**, Shogo Sakata**, Raimu Yokota**, and Shingo Kobayashi**
*Department of Computer Science, School of Science and Technology, Meiji University
1-1-1 Higashimita, Tama-ku, Kawasaki-shi, Kanagawa 214-8571, Japan
**Department of Computer Science, Graduate School of Science and Technology, Meiji University
1-1-1 Higashimita, Tama-ku, Kawasaki-shi, Kanagawa 214-8571, Japan

The most popular external sensor for robots capable of autonomous movement is 3D LiDAR. However, cameras are typically installed on robots that operate in environments where humans live their daily lives to obtain the same information that is presented to humans, even though autonomous movement itself can be performed using only 3D LiDAR. The number of studies on autonomous movement for robots using only visual sensors is relatively small, but this type of approach is effective at reducing the cost of sensing devices per robot. To reduce the number of external sensors required for autonomous movement, this paper proposes a novel visual navigation scheme using only a monocular camera as an external sensor. The key concept of the proposed scheme is to select a target point in an input image toward which a robot can move based on the results of semantic segmentation, where road following and obstacle avoidance are performed simultaneously. Additionally, a novel scheme called virtual LiDAR is proposed based on the results of semantic segmentation to estimate the orientation of a robot relative to the current path in a traversable area. Experiments conducted during the course of the Tsukuba Challenge 2019 demonstrated that a robot can operate in a real environment containing several obstacles, such as humans and other robots, if correct results of semantic segmentation are provided.
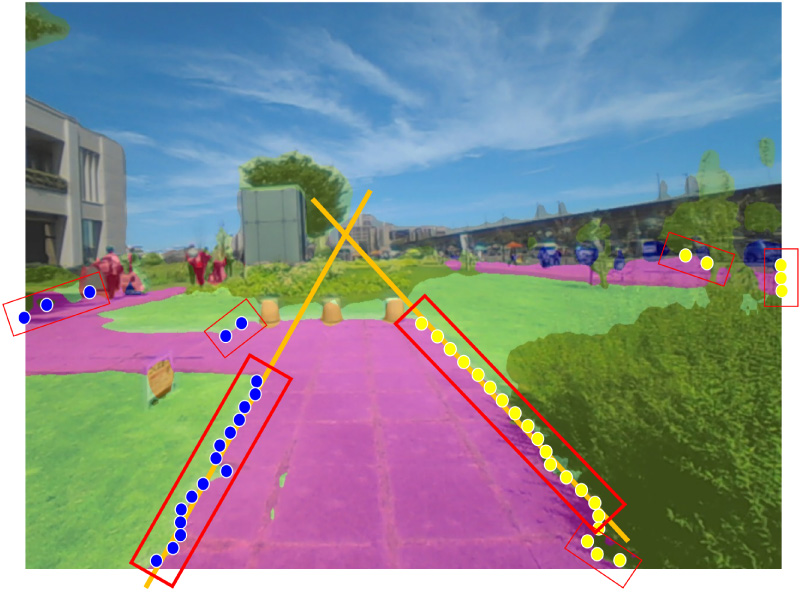
Road following with obstacle avoidance based on semantic segmentation
- [1] J. D. Crisman and C. E. Thorpe, “Color Vision For Road Following,” Proc. SPIE Conf. on Mobile Robots, Vol.1007, pp. 175-185, doi: 10.1117/12.949096, 1989.
- [2] T. Kanade, C. Thorpe, and W. Whittaker, “Autonomous Land Vehicle Project at CMU,” Proc. ACM Fourteenth Annual Conf. on Computer Science, pp. 71-80, doi: 10.1145/324634.325197, 1986.
- [3] R. Wallace, K. Matsuzaki, Y. Goto, J. Crisman, J. Webb, and T. Kanade, “Progress in robot road-following,” Proc. IEEE Int. Conf. on Robotics and Automation, Vol.3, pp. 1615-1621, doi: 10.1109/ROBOT.1986.1087503, 1986.
- [4] R. S. Wallace, A. Stentz, C. E. Thorpe, H. P. Moravec, W. Whittaker, and T. Kanade, “First results in robot road-following,” Proc. Int. Joint Conf. on Artificial Intelligence, pp. 1089-1095, 1985.
- [5] F. Beruny and J. R. d. Solar, “Topological Semantic Mapping and Localization in Urban Road Scenarios,” J. Intell. Robotics Syst., Vol.92, No.1, pp. 19-32, doi: 10.1007/s10846-017-0744-x, 2018.
- [6] J. H. Kim and M. J. Chung, “Absolute Stereo SFM without Stereo Correspondence for Vision Based SLAM,” Proc. IEEE Int. Conf. on Robotics and Automation, pp. 3360-3365, doi: 10.1109/ROBOT.2005.1570629, 2005.
- [7] D. Martins, K. Van Hecke, and G. De Croon, “Fusion of Stereo and Still Monocular Depth Estimates in a Self-Supervised Learning Context,” Proc. IEEE Int. Conf. on Robotics and Automation, pp. 849-856, doi: 10.1109/ICRA.2018.8461116, 2018.
- [8] O. Mendez, S. Hadfield, N. Pugeault, and R. Bowden, “SeDAR – Semantic Detection and Ranging: Humans can Localise without LiDAR, can Robots?,” Proc. IEEE Int. Conf. on Robotics and Automation, pp. 6053-6060, doi: 10.1109/ICRA.2018.8461074, 2018.
- [9] D. Murray and C. Jennings, “Stereo vision based mapping and navigation for mobile robots,” Proc. IEEE Int. Conf. on Robotics and Automation, Vol.2, pp. 1694-1699, doi: 10.1109/ROBOT.1997.614387, 1997.
- [10] T. Shioya, K. Kogure, T. Iwata, and N. Ohta, “Autonomous Mobile Robot Navigation Using Scene Matching with Local Features,” J. Robot. Mechatron., Vol.28, No.6, pp. 887-898, doi: 10.20965/jrm.2016.p0887, 2016.
- [11] A. Sujiwo, E. Takeuchi, L. Y. Morales, N. Akai, H. Darweesh, Y. Ninomiya, and M. Edahiro, “Robust and Accurate Monocular Vision-Based Localization in Outdoor Environments of Real-World Robot Challenge,” J. Robot. Mechatron., Vol.29, No.4, pp. 685-696, doi: 10.20965/jrm.2017.p0685, 2017.
- [12] R. Miyamoto, Y. Nakamura, M. Adachi, T. Nakajima, H. Ishida, K. Kojima, R. Aoki, T. Oki, and S. Kobayashi, “Vision-Based Road-Following Using Results of Semantic Segmentation for Autonomous Navigation,” Proc. Int. Conf. on Consumer Electronics in Berlin, pp. 194-199, doi: 10.1109/ICCE-Berlin47944.2019.8966198, 2019.
- [13] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs,” IEEE Trans. Pattern Anal. Mach. Intell., Vol.40, No.4, pp. 834-848, doi: 10.1109/TPAMI.2017.2699184, 2018.
- [14] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2881-2890, doi: 10.1109/CVPR.2017.660, 2017.
- [15] H. Zhao, Y. Zhang, S. Liu, J. Shi, C. Change Loy, D. Lin, and J. Jia, “PSANet: Point-wise spatial attention network for scene parsing,” Proc. European Conf. on Computer Vision, pp. 267-283, doi: 10.1007/978-3-030-01240-3_17, 2018.
- [16] H. Ishida, K. Matsutani, M. Adachi, S. Kobayashi, and R. Miyamoto, “Intersection Recognition Using Results of Semantic Segmentation for Visual Navigation,” Proc. Int. Conf. on Computer Vision Systems, pp. 153-163, doi: 10.1007/978-3-030-34995-0_15, 2019.
- [17] M. Adachi, S. Shatari, and R. Miyamoto, “Visual Navigation Using a Webcam Based on Semantic Segmentation for Indoor Robot,” Proc. Int. Conf. on Signal Image Technology and Internet Based Systems, pp. 15-21, doi: 10.1109/SITIS.2019.00015, 2019.
- [18] G. N. Desouza and A. C. Kak, “Vision for mobile robot navigation: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., Vol.24, No.2, pp. 237-267, doi: 10.1109/34.982903, 2002.
- [19] C. Thorpe, M. H. Hebert, T. Kanade, and S. A. Shafer, “Vision and navigation for the Carnegie-Mellon Navlab,” IEEE Trans. Pattern Anal. Mach. Intell., Vol.10, No.3, pp. 362-373, doi: 10.1109/34.3900, 1988.
- [20] C. Urmson et al., “Autonomous driving in urban environments: Boss and the Urban Challenge,” J. of Field Robotics, Vol.25, No.8, pp. 425-466, doi: 10.1002/rob.20255, 2008.
- [21] Y. Matsumoto, M. Inaba, and H. Inoue, “Visual navigation using view-sequenced route representation,” Proc. IEEE Int. Conf. on Robotics and Automation, Vol.1, pp. 83-88, 1996.
- [22] M. Meng and A. C. Kak, “Mobile robot navigation using neural networks and nonmetrical environmental models,” IEEE Control Systems Magazine, Vol.13, No.5, pp. 30-39, 1993.
- [23] M. Meng and A. C. Kak, “NEURO-NAV: a neural network based architecture for vision-guided mobile robot navigation using non-metrical models of the environment,” Proc. IEEE Int. Conf. on Robotics and Automation, Vol.2, pp. 750-757, 1993.
- [24] Y. Hosoda, R. Sawahashi, N. Machinaka, R. Yamazaki, Y. Sadakuni, K. Onda, R. Kusakari, M. Kimba, T. Oishi, and Y. Kuroda, “Robust Road-Following Navigation System with a Simple Map,” J. Robot. Mechatron., Vol.30, No.4, pp. 552-562, doi: 10.20965/jrm.2018.p0552, 2018.
- [25] K. Kazama, Y. Akagi, P. Raksincharoensak, and H. Mouri, “Fundamental Study on Road Detection Method Using Multi-Layered Distance Data with HOG and SVM,” J. Robot. Mechatron., Vol.28, No.6, pp. 870-877, doi: 10.20965/jrm.2016.p0870, 2016.
- [26] J. Crespo, R. Barber, and O. Mozos, “Relational Model for Robotic Semantic Navigation in Indoor Environments,” J. of Intelligent and Robotic Systems, Vol.86, pp. 617-639, doi: 10.1007/s10846-017-0469-x, 2017.
- [27] H. Dang and P. K. Allen, “Semantic grasping: Planning robotic grasps functionally suitable for an object manipulation task,” Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 1311-1317, doi: 10.1109/IROS.2012.6385563, 2012.
- [28] C. Galindo, J.-A. Fernández-Madrigal, J. González, and A. Saffiotti, “Robot task planning using semantic maps,” Robotics and Autonomous Systems, Vol.56, No.11, pp. 955-966, doi: 10.1016/j.robot.2008.08.007, 2008.
- [29] E. Jang, S. Vijayanarasimhan, P. Pastor, J. Ibarz, and S. Levine, “End-to-End Learning of Semantic Grasping,” Proc. Conf. on Robot Learning, pp. 119-132, 2017.
- [30] D. Lang, S. Friedmann, M. Häselich, and D. Paulus, “Definition of semantic maps for outdoor robotic tasks,” Proc. IEEE Int. Conf. on Robotics and Biomimetics, pp. 2547-2552, doi: 10.1109/ROBIO.2014.7090724, 2014.
- [31] L. P. Tchapmi, C. B. Choy, I. Armeni, J. Gwak, and S. Savarese, “SEGCloud: Semantic Segmentation of 3D Point Clouds,” Proc. Int. Conf. on 3D Vision, pp. 537-547, doi: 10.1109/3DV.2017.00067, 2017.
- [32] Y. Xie, J. Tian, and X. Zhu, “Linking Points With Labels in 3D: A Review of Point Cloud Semantic Segmentation,” IEEE Geoscience and Remote Sensing Magazine, doi: 10.1109/MGRS.2019.2937630, 2020.
- [33] K. Matsutani, T. Watanabe, T. Oki, and R. Miyamoto, “A Study on Intersection Detection and Recognition Using Only a Monocular Camera for Visual Navigation,” IEICE Technical Report, Vol.119, pp. 5-10, 2019.
- [34] H. Zhao, X. Qi, X. Shen, J. Shi, and J. Jia, “ICNet for Real-Time Semantic Segmentation on High-Resolution Images,” V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss (Eds.), Proc. European Conf. on Computer Vision, pp. 418-434, doi: 10.1007/978-3-030-01219-9_25, 2018.
- [35] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes Dataset for Semantic Urban Scene Understanding,” Proc. IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3213-3223, doi: 10.1109/CVPR.2016.350, 2016.
- [36] R. Miyamoto, M. Adachi, Y. Nakamura, T. Nakajima, H. Ishida, and S. Kobayashi, “Accuracy Improvement of Semantic Segmentation Using Appropriate Datasets for Robot Navigation,” Proc. Int. Conf. on Control, Decision and Information Technologies, pp. 1610-1615, doi: 10.1109/CoDIT.2019.8820616, 2019.
- [37] Z. Xiang, J. Yu, J. Li, and J. Su, “ViLiVO: Virtual LiDAR-Visual Odometry for an Autonomous Vehicle with a Multi-Camera System,” Proc. IEEE/RSJ Int. Conf. on Intelligent Robots and Systems, pp. 2486-2492, doi: 10.1109/IROS40897.2019.8968484, 2019.
- [38] R. Kusakari, K. Onda, S. Yamada, and Y. Kuroda, “Intersection detection based on recognition of drivable region using reflection light intensity,” Trans. of the JSME, Vol.85, No.875, 19-00064, doi: 10.1299/transjsme.19-00064, 2019.
- [39] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An Open Urban Driving Simulator,” S. Levine, V. Vanhoucke, and K. Goldberg (Eds.), Proc. Conf. on Robot Learning, Vol.78, pp. 1-16, 2017.
- [40] H. Komatsuzaki, R. Yokota, M. Adachi, S. Kobayashi, T. Oki, R. Aoki, and R. Miyamoto, “A Study about a Dataset Creation Using a 3D Scanner for Semantic Segmentation Aiming Visual Navigation,” IEICE Technical Report, Vol.119, pp. 65-70, 2019.
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.