Paper:
Multi-View Object Recognition and Pose Sequence Estimation Using HMMs
Lorena Núñez*1,*2
 , Jesús Savage*1, Miguel Moctezuma-Flores*3
, Luis Contreras*4
, Marco Negrete*1
, and Hiroyuki Okada*4
, Jesús Savage*1, Miguel Moctezuma-Flores*3
, Luis Contreras*4
, Marco Negrete*1
, and Hiroyuki Okada*4
*1BioRobotics Laboratory, School of Engineering, National Autonomous University of Mexico
Circuito Exterior S/N, Ciudad Universitaria, Coyoacán, Mexico City 04510, Mexico
*2Telecommunications Department, School of Electrical Engineering, Central University of Venezuela
Ciudad Universitaria de Caracas, Los Chaguaramos, Caracas 1051, Venezuela
*3Telecommunications Department, School of Engineering, National Autonomous University of Mexico
Circuito Exterior S/N, Ciudad Universitaria, Coyoacán, Mexico City 04510, Mexico
*4Advanced Intelligence & Robotics Research Center, Tamagawa University
2-7-1 Komatsugawa, Edogawa-ku, Tokyo 132-0034, Japan

This work proposes an integration of a vision system for a service robot when its gripper holds an object. Based on the particular conditions of the problem, the solution is modular and allows one to use various options to extract features and classify data. Since the robot can move the object and has information about its position, the proposed solution takes advantage of this by applying preprocessing techniques to improve the performance of classifiers that can be considered weak. In addition to being able to classify the object, it is possible to infer the sequence of movements that it carries out using hidden Markov models (HMMs). The system was tested using a public dataset, the COIL-100, as well as with a dataset of real objects using the human support robot (HSR). The results show that the proposed vision system is able to work with a low number of shots in each class. Two HMM architectures are tested. In order to enhance classification by adding information from multiple perspectives, various criteria were analyzed. A simple model is built to integrate information and infer object movements. The system also has an next best view algorithm where different parameters are tested in order to improve both accuracy in the classification of the object and its pose, especially in objects that may be similar in several of their views. The system was tested using COIL-100 dataset and with real objects in common use and a HSR robot to take the real dataset. In general, using relatively few shots of each class and a plain computer, consistent results were obtained, requiring only 8.192×10-3 MFLOPs for sequence processing using concatenated HMMs compared to 404.34 MFLOPs for CNN+LSTM.
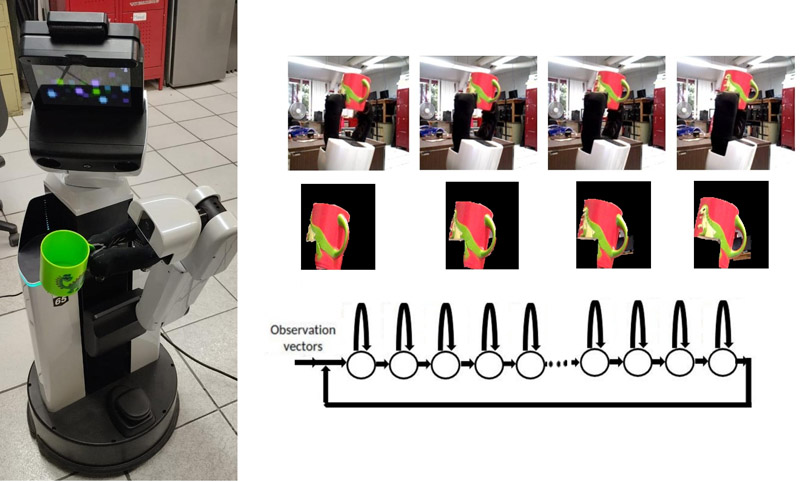
Different views of objects to detect and estimate pose sequences using HMMs
- [1] Y. Zuo, W. Qiu, L. Xie, F. Zhong, Y. Wang, and A. L. Yuille, “Craves: Controlling robotic arm with a vision-based economic system,” Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 4214-4223, 2019. https://doi.org/10.1109/CVPR.2019.00434
- [2] R. Rahmatizadeh, P. Abolghasemi, L. Bölöni, and S Levine, “Vision-based multi-task manipulation for inexpensive robots using end-to-end learning from demonstration,” 2018 IEEE Int. Conf. on Robotics and Automation (ICRA), pp. 3758-3765, 2018. https://doi.org/10.1109/ICRA.2018.8461076
- [3] Z. Zou, K. Chen, Z. Shi, Y. Guo, and J. Ye, “Object detection in 20 years: A survey,” Proc. of the IEEE, Vol.111, Issue 3, pp. 257-276, 2023. https://doi.org/10.1109/JPROC.2023.3238524
- [4] R. Yu, X. Xu, and Z. Wang, “Influence of object detection in deep learning,” J. Adv. Comput. Intell. Intell. Inform., Vol.22, No.5, pp. 683-688, 2018. https://doi.org/10.20965/jaciii.2018.p0683
- [5] J. P. Rogelio, E. P. Dadios, R. R. P. Vicerra, and A. A. Bandala, “Object detection and segmentation using deeplabv3 deep neural network for a portable x-ray source model,” J. Adv. Comput. Intell. Intell. Inform., Vol.26, No.5, pp. 842-850, 2022. https://doi.org/10.20965/jaciii.2022.p0842
- [6] H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, “Multi-view convolutional neural networks for 3D shape recognition,” Proc. of the IEEE Int. Conf. on Computer Vision (ICCV), pp. 945-953, 2015. https://doi.org/10.1109/ICCV.2015.114
- [7] A. Kanezaki, Y. Matsushita, and Y. Nishida, “RotationNet for joint object categorization and unsupervised pose estimation from multi-view images,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.43, No.1, pp. 269-283, 2021. https://doi.org/10.1109/TPAMI.2019.2922640
- [8] Y. Xu, C. Zheng, R. Xu, and Y. Quan, “Deeply exploiting long-term view dependency for 3D shape recognition,” IEEE Access, Vol.7, pp. 111678-111691, 2019. https://doi.org/10.1109/ACCESS.2019.2934650
- [9] T. Diwan, G. Anirudh, and J. V. Tembhurne, “Object detection using YOLO: Challenges, architectural successors, datasets and applications,” Multimedia Tools and Applications, Vol.82, No.6, pp. 9243-9275, 2023. https://doi.org/10.1007/s11042-022-13644-y
- [10] T. Yamamoto, T. Nishino, H. Kajima, M. Ohta, and K. Ikeda, “Human Support Robot (HSR),” ACM SIGGRAPH 2018 Emerging Technologies, Article No.11, 2018. https://doi.org/10.1145/3214907.3233972
- [11] L. Núñez, M. Negrete, J. Savage, L. Contreras, and M. Moctezuma, “Multiview object and view sequence recognition using hidden Markov models,” 2022 IEEE 18th Int. Conf. on Automation Science and Engineering (CASE), pp. 589-594, 2022. https://doi.org/10.1109/CASE49997.2022.9926680
- [12] S. A. Nene, S. K. Nayar, and H. Murase, “Columbia Object Image Library (COIL-100),” Department of Computer Science, Columbia University, Technical Report No.CUCS-006-96, 1996.
- [13] M. Panzner and P. Cimiano, “Comparing hidden Markov models and long short term memory neural networks for learning action representations,” Machine Learning, Optimization, and Big Data: Second Int. Workshop (MOD 2016), pp. 94-105, 2016. https://doi.org/10.1007/978-3-319-51469-7_8
- [14] H. Sakaino, Y. Yanagisawa, and T. Satoh, “Tool operation recognition based on robust optical flow and HMM from short-time sequential image data,” J. Adv. Comput. Intell. Intell. Inform., Vol.8, No.2, pp. 156-167, 2004. https://doi.org/10.20965/jaciii.2004.p0156
- [15] Y. Maeda and T. Ushioda, “Hidden Markov Modeling of Human Pivoting,” J. Robot. Mechatron., Vol.19, No.4, pp. 444-447, 2007. https://doi.org/10.20965/jrm.2007.p0444
- [16] J. Inthiam, A. Mowshowitz, and E. Hayashi, “Mood perception model for social robot based on facial and bodily expression using a hidden Markov model,” J. Robot. Mechatron., Vol.31, No.4, pp. 629-638, 2019. https://doi.org/10.20965/jrm.2019.p0629
- [17] J. Peng and Y. Su, “An improved algorithm for detection and pose estimation of texture-less objects,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.2, pp. 204-212, 2021. https://doi.org/10.20965/jaciii.2021.p0204
- [18] S. Chen, Y. Li, and N. M. Kwok, “Active vision in robotic systems: A survey of recent developments,” The Int. J. of Robotics Research, Vol.30, Issue 11, pp. 1343-1377, 2011. https://doi.org/10.1177/0278364911410755
- [19] R. Bajcsy, Y. Aloimonos, and J. K. Tsotsos, “Revisiting active perception,” Autonomous Robots, Vol.42, No.2, pp. 177-196, 2018. https://doi.org/10.1007/s10514-017-9615-3
- [20] C. Ma, Y. Guo, J. Yang, and W. An, “Learning multi-view representation with LSTM for 3-D shape recognition and retrieval,” IEEE Trans. on Multimedia, Vol.21, Issue 5, pp. 1169-1182, 2018. https://doi.org/10.1109/TMM.2018.2875512
- [21] G. Dai, J. Xie, and Y. Fang, “Siamese CNN-BiLSTM Architecture for 3D Shape Representation Learning,” Proc. of the 27th Int. Joint Conf. on Artificial Intelligence (IJCAI), pp. 670-676, 2018. https://doi.org/10.24963/ijcai.2018/93
- [22] W. Wei, H. Yu, H. Zhang, W. Xu, and Y. Wu, “Metaview: Few-shot active object recognition,” arXiv preprint, arXiv:2103.04242, 2021. https://doi.org/10.48550/arXiv.2103.04242
- [23] R. B. Roy, A. H. Roy, A. Konar, and A. Nagar, “Design of a computationally economical image classifier using generic features,” 2019 IEEE Congress on Evolutionary Computation (CEC), pp. 2402-2409, 2019. https://doi.org/10.1109/CEC.2019.8790365
- [24] C. M. Bhuma and R. Kongara, “A Novel Technique for Image Retrieval Based on Concatenated Features Extracted from Big Dataset Pre-Trained CNNs,” Int. J. of Image, Graphics and Signal Processing, Vol.15, No.2, Article No.1, 2023. https://doi.org/10.5815/ijigsp.2023.02.01
- [25] C. Sarmiento and J. Savage, “Comparison of two objects classification techniques using hidden Markov models and convolutional neural networks,” Informatics and Automation, Vol.19, No.6, pp. 1222-1254, 2020. https://doi.org/10.15622/ia.2020.19.6.4
- [26] A. M. Nagy, M. Rashad, and L. Czúni, “Active multiview recognition with hidden Markov temporal support,” Signal, Image and Video Processing, Vol.15, pp. 315-322, 2020. https://doi.org/10.1007/s11760-020-01743-y
- [27] S. Ivaldi, S. M. Nguyen, N. Lyubova, A. Droniou, V. Padois, D. Filliat, P.-Y. Oudeyer, and O. Sigaud, “Object learning through active exploration,” IEEE Trans. on Autonomous Mental Development, Vol.6, Issue 1, pp. 56-72, 2014. https://doi.org/10.1109/TAMD.2013.2280614
- [28] B. Browatzki, V. Tikhanoff, G. Metta, H. H. Bülthoff, and C. Wallraven, “Active in-hand object recognition on a humanoid robot,” IEEE Trans. on Robotics, Vol.30, Issue 5, pp. 1260-1269, 2014. https://doi.org/10.1109/TRO.2014.2328779
- [29] G. Mir, M. Kerzel, E. Strahl, and S. Wermter, “A humanoid robot learning audiovisual classification by active exploration,” 2021 IEEE Int. Conf. on Development and Learning (ICDL), 2021. https://doi.org/10.1109/ICDL49984.2021.9515598
- [30] Z. Ghahramani, “An introduction to hidden Markov models and Bayesian networks,” Int. J. Pattern Recognit. Artif. Intell., Vol.15, No.1, pp. 9-42, 2001. https://doi.org/10.1142/S0218001401000836
- [31] A. O’Neill et al., “Open X-Embodiment: Robotic Learning Datasets and RT-X Models,” arXiv preprint, arXiv:2310.08864, 2023. https://doi.org/10.48550/arXiv.2310.08864
- [32] B. Calli, A. Singh, J. Bruce, A. Walsman, K. Konolige, S. Srinivasa, P. Abbeel, and A. M. Dollar, “Yale-CMU-Berkeley dataset for robotic manipulation research,” Int. J. of Robotics Research, Vol.36, Issue 3, pp. 261-268, 2017. https://doi.org/10.1177/0278364917700714
- [33] Y. Ishida and H. Tamukoh, “Semi-automatic dataset generation for object detection and recognition and its evaluation on domestic service robots,” J. Robot. Mechatron., Vol.32, No.1, pp. 245-253, 2020. https://doi.org/10.20965/jrm.2020.p0245
- [34] M. Tang, L. Gorelick, O. Veksler, and Y. Boykov, “GrabCut in One Cut,” Proc. of the IEEE Int. Conf. on Computer Vision, pp. 1769-1776, 2013. https://doi.org/10.1109/ICCV.2013.222
- [35] P. Hoseini, S. K. Paul, M. Nicolescu, and M. Nicolescu, “A surface and appearance-based next best view system for active object recognition,” Proc. of the 16th Int. Joint Conf. on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), Vol.5, pp. 841-851, 2021. https://doi.org/10.5220/0010173708410851
- [36] S. Chen, Y. F. Li, J. Zhang, and W. Wang, “Information entropy based planning,” S. Chen, Y. F. Li, J. Zhang, and W. Wang (Eds.), Active Sensor Planning for Multiview Vision Tasks, pp. 147-176, Springer, 2008. https://doi.org/10.1007/978-3-540-77072-5_8
- [37] J. Daudelin and M. Campbell, “An adaptable, probabilistic, next-best view algorithm for reconstruction of unknown 3-D objects,” IEEE Robotics and Automation Letters, Vol.2, Issue 3, pp. 1540-1547, 2017. https://doi.org/10.1109/LRA.2017.2660769
- [38] S. A. Kay, S. Julier, and V. M. Pawar, “Semantically informed next best view planning for autonomous aerial 3D reconstruction,” 2021 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 3125-3130, 2021. https://doi.org/10.1109/IROS51168.2021.9636352
- [39] S. A. Khayam, “The Discrete Cosine Transform (DCT): Theory and Application,” Michigan State University, Vol.114, No.1, Article No.31, 2003.
- [40] L. R. Rabiner, “A tutorial on hidden Markov models and selected applications in speech recognition,” Proc. of the IEEE, Vol.77, Issue 2, pp. 257-286, 1989. https://doi.org/10.1109/5.18626
- [41] S. Pang, T. H. G. Thio, F. L. Siaw, M. Chen, and Y. Xia, “Research on improved image segmentation algorithm based on GrabCut,” Electronics, Vol.13, Issue 20, Article No.4068, 2024. https://doi.org/10.3390/electronics13204068
- [42] M. Sato, H. Aomori, and T. Otake, “Automation and acceleration of graph cut based image segmentation utilizing U-net,” Nonlinear Theory and Its Applications, IEICE, Vol.15, No.1, pp. 54-71, 2024. https://doi.org/10.1587/nolta.15.54
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.