Paper:
Packaging Design for Product Recognition Using Deep Learning
Souma Kawanishi, Kazuyoshi Wada
 , and Yuki Kikutake
, and Yuki Kikutake
Graduate School of Systems Design, Tokyo Metropolitan University
6-6 Asahigaoka, Hino, Tokyo 191-0065, Japan

The convenience store industry is experiencing a growing labor shortage, and the need to automate tasks is increasing. Product display is a labor-intensive task, and product recognition is an important issue. Existing recognition methods using deep learning require relearning every time a new product is introduced, which is time-consuming. In this study, a packaging design was developed that streamlines the learning process by embedding prelearned patterns and markers into the product packaging. The proposed design consists of patterns for product identification and markers for estimating product position and orientation. These are “typographic patterns” that change the characters and their minimum unit composition, as well as the manner in which the minimum units are arranged among themselves, and can create more than 400,000 different types of any products. This paper describes the creation of the proposed patterns and marks. The proposed design was then applied to a sandwich package, and identification experiments were conducted for 23 basic placement patterns. The identification rate was over 97%.
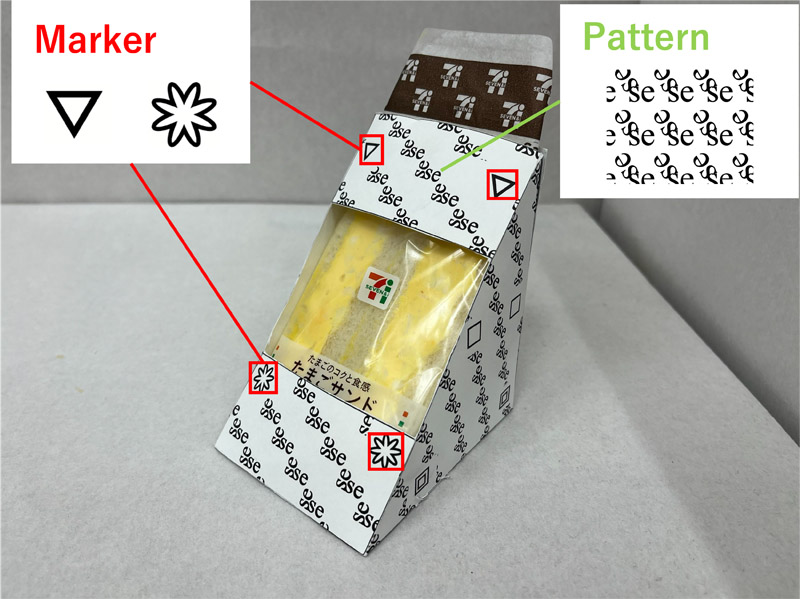
Package design for deep learning
- [1] N. Muramatsu and H. Akiyama, “Japan: Super-Aging Society Preparing for the Future,” The Gerontologist, Vol.51, No.4, pp. 425-432, 2011. https://doi.org/10.1093/geront/gnr067
- [2] K. Miwa, “Study of operations and staff scheduling in retail store,” J. of Nagoya Gakuin University, Vol.51, No.4, pp. 143-158, 2015.
- [3] R. Tomikawa, Y. Ibuki, K. Kobayashi, K. Matsumoto, H. Suito, Y. Takemura, M. Suzuki, T. Tasaki, and K. Ohara, “Development of display and disposal work system for convenience stores using dual-arm robot,” Advanced Robotics, Vol.36, No.23, pp. 1273-1290, 2022. https://doi.org/10.1080/01691864.2022.2136503
- [4] G. A. G. Ricardez, S. Okada, N. Koganti, A. Yasuda, P. M. U. Eljuri, T. Sano, P.-C. Yang, L. E. Hafi, M. Yamamoto, J. Takamatsu, and T. Ogasawara, “Restock and straightening system for retail automation using compliant and mobile manipulation,” Advanced Robotics, Vol.34, Nos.3-4, pp. 235-249, 2020. https://doi.org/10.1080/01691864.2019.1698460
- [5] M. Seki, K. Wada, Y. Kitajima, M. Hashimoto, and T. Tomizawa, “Development of xyz stage-type display robot system for stock and disposal tasks in convenience stores,” Advanced Robotics, Vol.36, No.23, pp. 1252-1272, 2022. https://doi.org/10.1080/01691864.2022.2134736
- [6] M. Hashimoto, Y. Domae, and S. Kaneko, “Current status and future trends on robot vision technology,” J. Robot. Mechatron., Vol.29, No.2, pp. 275-286, 2017. https://doi.org/10.20965/jrm.2017.p0275
- [7] K. Fujita and T. Tasaki, “Pynet: Poseclass and yaw angle output network for object pose estimation,” J. Robot. Mechatron., Vol.35, No.1, pp. 8-17, 2023. https://doi.org/10.20965/jrm.2023.p0008
- [8] T. Takubo, T. Nakamura, R. Sugiyama, and A. Ueno, “Multifunctional shelf and magnetic marker for stock and disposal tasks in convenience stores,” J. Robot. Mechatron., Vol.35, No.1, pp. 18-29, 2023. https://doi.org/10.20965/jrm.2023.p0018
- [9] T. Parisotto, S. Mukherjee, and H. Kasaei, “More: simultaneous multi-view 3d object recognition and pose estimation,” Intelligent Service Robotics, Vol.16, pp. 497-508, 2023. https://doi.org/10.1007/s11370-023-00468-4
- [10] S. Kawanishi and K. Wada, “Experimental study of product recognition method by package design,” 2024 IEEE/SICE Int. Symp. on System Integration (SII), pp. 1296-1301, 2024. https://doi.org/10.1109/SII58957.2024.10417315
- [11] D. Held, S. Thrun, and S. Savarse, “Deep learning for single-view instance recognition,” arXiv:1507.08286, 2015.
- [12] K. Kang, G. Pang, X. Zhao, J. Wang, and Y. Li, “A new benchmark for instance-level image classification,” IEEE Access, Vol.8, pp. 70306-70315, 2020. https://doi.org/10.1109/ACCESS.2020.2986771
- [13] Y. Wei, S. Tran, S. Xu, B. Kang, and M. Springer, “Deep learning for retail product recognition: Challenges and techniques,” Computational Intelligence and Neuroscience, Vol.2020, Article No.8875910, 2020. https://doi.org/10.1155/2020/8875910
- [14] L. Chen and M. Murata, “Enhancing network modularity to mitigate catastrophic forgetting,” Applied Network Science, Vol.5, Article No.94, 2020.
- [15] S. Mondesire and R. P. Wiegand, “Mitigating catastrophic forgetting with complementary layered learning,” Electronics, Vol.12, No.43, Article No.706, 2023. https://doi.org/10.3390/electronics12030706
- [16] K. O. Ellefsen, J.-B. Mouret, and J. Clune, “Neural modularity helps organisms evolve to learn new skills without forgetting old skills,” PLoS Computational Biology, Vol.11, No.4, Article No.e1004128, 2015.
- [17] A. Franco, D. Maltoni, and S. Papi, “Grocery product detection and recognition,” Expert Systems with Applications, Vol.81, pp. 163-176, 2017. https://doi.org/10.1016/j.eswa.2017.02.050
- [18] A. Tonioni and L. D. Stefano, “Domain invariant hierarchical embedding for grocery products recognition,” Computer Vision and Image Understanding, Vol.182, pp. 81-92, 2019. https://doi.org/10.1016/j.cviu.2019.03.005
- [19] R. C. Bolles, P. Horaud, and M. J. Hannah, “3DPO: A Three-Dimensional Part Orientation System,” M. A. Fischler and O. Firschein (Eds.), Morgan Kaufmann, 1987. https://doi.org/10.1016/B978-0-08-051581-6.50039-8
- [20] Y. Sumi and F. Tomita, “Three-dimensional object recognition using stereo vision,” IEICE Trans. on Information and Systems, Vol.28, pp. 19-26, 1997. https://doi.org/10.1002/(SICI)1520-684X(19971130)28:13<19::AID-SCJ3>3.0.CO;2-K
- [21] Z. Jiang, J. Chen, Y. Jing, X. Huang, and H. Li, “6d pose annotation and pose estimation method for weak-corner objects under low-light conditions,” Science China Technological Sciences, Vol.66, pp. 630-640, 2023. https://doi.org/10.1007/s11431-021-2087-8
- [22] D. Maturanaand and S. Scherer, “Voxnet: A 3d convolutional neural network for real-time object recognition,” 2015 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), pp. 922-928, 2015. https://doi.org/10.1109/IROS.2015.7353481
- [23] T. Furuya and R. Ohbuchi, “Deep aggregation of local 3d geometric features for 3d model retrieval,” British Machine Vision Conf., 2016. https://doi.org/10.5244/C.30.121
- [24] M. Sundermeyer, Z.-C. Marton, M. Durner, M. Brucker, and R. Triebel, “Implicit 3d orientation learning for 6d object detection from rgb images,” European Conf. on Computer Vision, 2018. https://doi.org/10.48550/arXiv.1902.01275
- [25] Z. Zhao, G. Peng, H. Wang, H. Fang, C. Li, and C. Lu, “Estimating 6d pose from localizing designated surface keypoints,” arXiv 1812.01387, 2018. https://doi.org/10.48550/arXiv.1812.01387
- [26] P. Wu, H. Tseng, M. Yang, and S. Chien, “Direct pose estimation for planar objects,” Computer Vision and Image Understanding, Vol.172, pp. 50-66, 2018. https://doi.org/10.1016/j.cviu.2018.03.006
- [27] X. Yang, K. Li, J. Wang, and X. Fan, “Er-pose: Learning edge representation for 6d pose estimation of texture-less objects,” Neurocomputing, Vol.515, pp. 13-25, 2023. https://doi.org/10.1016/j.neucom.2022.09.151
- [28] S. K. Huang, C. C. Hsu, W. Y. Wang, and C. H. Lin, “Iterative pose refinement for object pose estimation based on rgbd data,” Sensors, Vol.20, No.15, Article No.4114, 2020. https://www.mdpi.com/1424-8220/20/15/4114
- [29] Y. Higano, K. Kato, C. Tsukui, S. Ota, K. Hirota, R. Yanagita, R. Kanou, Y. Kikutake, and K. Wada, “Development of package design suitable for deep learning to identify product types,” Bulletin of JSSD, pp. 356-357, 2016.
- [30] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?,” Advances in Neural Information Processing Systems, Vol.27, 2014.
- [31] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pp. 770-778, 2016. https://doi.org/10.1109/CVPR.2016.90
- [32] R. Hartley and A. Zisserman, “Multiple view geometry in computer vision,” Cambridge University Press, 2003.
- [33] C.-P. Lu, G. Hager, and E. Mjolsness, “Fast and globally convergent pose estimation from video images,” IEEE Trans. on Pattern Analysis and Machine Intelligence, Vol.22, No.6, pp. 610-622, 2000. https://doi.org/10.1109/34.862199
- [34] J. A. Hesch and S. I. Roumeliotis, “A direct least-squares (dls) method for pnp,” 2011 Int. Conf. on Computer Vision, pp. 383-390, 2011. https://doi.org/htttps://doi.org/10.1109/ICCV.2011.6126266
- [35] Y. Zheng, Y. Kuang, S. Sugimoto, K. Åström, and M. Okutomi, “Revisiting the pnp problem: A fast, general and optimal solution,” Proc. of the IEEE Int. Conf. on Computer Vision, pp. 2344-2351, 2013. https://doi.org/htttps://doi.org/10.1109/ICCV.2013.291
- [36] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, pp. 779-788, 2016. https://doi.org/10.48550/arXiv.1506.02640
- [37] B. Alexey, W. C. Yao, and L. H. Y. Mark, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint, arXiv:2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.