Research Paper:
Enhancing Deep Reinforcement Learning in Spiking Neural Networks via a Burn-In Strategy
Takahiro Iwata*,†, Seankein Yoshioka*, Hiroto Takigasaki*, and Daisuke Miki**

*Graduate School of Computer Science, Chiba Institute of Technology
2-17-1 Tsudanuma, Narashino, Chiba 275-0016, Japan
†Corresponding author
**Department of Computer Science, Chiba Institute of Technology
2-17-1 Tsudanuma, Narashino, Chiba 275-0016, Japan

Recently, deep reinforcement learning has demonstrated notable success across various tasks. This success is largely attributable to its high expressive power. However, operating large-scale neural networks requires substantial power consumption. This is particularly a challenge for applications with limited power budgets, such as robotic control, in which energy efficiency is paramount. By contrast, spiking neural networks (SNNs) have garnered considerable attention owing to their high energy efficiency, particularly when implemented on dedicated neuromorphic hardware. Despite these advantages, conventional methods for integrating SNNs into deep reinforcement learning frameworks frequently struggle with training stability. To address this issue, this study introduces a novel algorithm that incorporates SNNs within the actor networks of a twin-delayed deep deterministic policy gradient architecture. To further enhance the performance, a burn-in strategy inspired by recurrent experience replay in distributed reinforcement learning was implemented. This study introduces a burn-in strategy that stabilizes learning and reduces variance by addressing the issue of stale membrane potentials stored in the replay buffer. In this strategy, membrane potentials computed using outdated network parameters are passed through the current network to align them with the updated parameters, to improve the accuracy of action value estimations and strengthen training stability. Furthermore, loss-adjusted prioritization was incorporated to improve the learning efficiency and stability. Experimental evaluations conducted in OpenAI Gym environments demonstrated that the proposed method yielded superior rewards compared with conventional approaches.
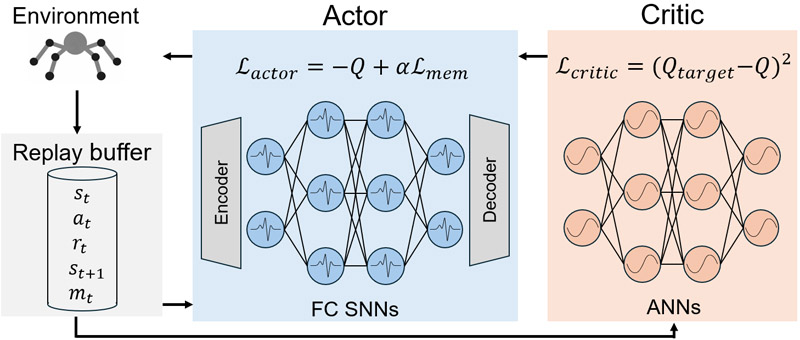
SNN-based actor-critic framework for RL
- [1] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. A. Riedmiller, “Playing atari with deep reinforcement learning,” arXiv:1312.5602, 2013. https://doi.org/10.48550/arXiv.1312.5602
- [2] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton et al., “Mastering the game of go without human knowledge,” Nature, Vol.550, No.7676, pp. 354-359, 2017. https://doi.org/10.1038/nature24270
- [3] T. Haarnoja, S. Ha, A. Zhou, J. Tan, G. Tucker, and S. Levine, “Learning to walk via deep reinforcement learning,” Robotics: Science and Systems XV, 2019. https://doi.org/10.15607/RSS.2019.XV.011
- [4] S. Fujimoto, H. van Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” Proc. of the 35th Int. Conf. on Machine Learning, 2018.
- [5] M. Horowitz, “1.1 computing’ energy problem (and what we can do about it),” 2014 IEEE Int. Solid-State Circuits Conf. Digest of Technical Papers (ISSCC), pp. 10-14, 2014. https://doi.org/10.1109/ISSCC.2014.6757323
- [6] Intel Corporation, “Neuromorphic Computing and Engineering, Next Wave of AI Capabilities.” https://www.intel.com/content/www/us/en/research/neuromorphic-computing.html [Accessed April 1, 2025]
- [7] G. Tang, N. Kumar, R. Yoo, and K. Michmizos, “Deep reinforcement learning with population-coded spiking neural network for continuous control,” Proc. of the 2020 Conf. on Robot Learning, Vol.155, pp. 2016-2029, 2021.
- [8] K. Naya, K. Kutsuzawa, D. Owaki, and M. Hayashibe, “Spiking neural network discovers energy-efficient hexapod motion in deep reinforcement learning,” IEEE Access, Vol.9, pp. 150345-150354, 2021. https://doi.org/10.1109/ACCESS.2021.3126311
- [9] T. Iwata, S. Yoshioka, and D. Miki, “Applying burn-in strategy to deep reinforcement learning with spiking neural networks,” 2024 Joint 13th Int. Conf. on Soft Computing and Intelligent Systems and 25th Int. Symp. on Advanced Intelligent Systems (SCIS&ISIS), 2024. https://doi.org/10.1109/SCISISIS61014.2024.10760159
- [10] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” arXiv:1509.02971, 2019. https://doi.org/10.48550/arXiv.1509.02971
- [11] S. Fujimoto, D. Meger, and D. Precup, “An equivalence between loss functions and non-uniform sampling in experience replay,” Proc. of the 34th Int. Conf. on Neural Information Processing Systems (NIPS ’20), 2020.
- [12] S. Kapturowski, G. Ostrovski, W. Dabney, J. Quan, and R. Munos, “Recurrent experience replay in distributed reinforcement learning,” Int. Conf. on Learning Representations, 2019.
- [13] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, Vol.9, No.8, pp. 1735-1780, 1997. https://doi.org/10.1162/neco.1997.9.8.1735
- [14] D. Horgan, J. Quan, D. Budden, G. Barth-Maron, M. Hessel, H. van Hasselt, and D. Silver, “Distributed prioritized experience replay,” Int. Conf. on Learning Representations, 2018.
- [15] “OpenAI Gym.” https://gymnasium.farama.org/environments/mujoco/ [Accessed April 1, 2025]
- [16] PyTorch Foundation, “Pytorch.” https://pytorch.org/ [Accessed April 1, 2025]
- [17] J. K. Eshraghian, “snntorch.” https://snntorch.readthedocs.io/en/latest/snntorch.html [Accessed April 1, 2025]
- [18] PyTorch Foundation, “Adam.” https://pytorch.org/docs/stable/generated/torch.optim.Adam.html [Accessed April 1, 2025]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.