Research Paper:
Semantically Aligned Soundscape from Text: A Keyword-Guided Lightweight Generation Framework and Applicability in Reading Scenarios
Shan Xue† and Hajime Nobuhara

University of Tsukuba
1-1-1 Tennodai, Tsukuba, Ibaraki 305-8577, Japan
†Corresponding author

Text-to-audio (TTA) generation often suffers from inconsistencies between audio output and textual input due to insufficient representation of textual details. In this paper, we present a lightweight keyword-guided generation framework for soundscape synthesis that explicitly maps spatiotemporal cues in text to the corresponding sound effects. Based on this framework, we developed two generative systems and validated their flexibility and effectiveness. System I leverages the large language model (LLM) to enhance semantic representation by introducing a structured mapping mechanism. We constructed a small-scale dataset based on this system and fine-tuned a state-of-the-art TTA model. System II employs traditional semantic analysis and generates soundscape using a predefined base dataset and an effect-mapping set. A subjective evaluation involving 24 participants demonstrated that the soundscape generated using the proposed approach yielded higher semantic consistency compared with traditional TTA generation. In addition, the reading experiments showed that the generated soundscape significantly improved the immersion experience during both silent and aloud reading. These results highlight the importance of fine-grained textual cues in cross-modal generation and support the use of structured rule-based mapping to improve the semantic alignment of TTA systems.
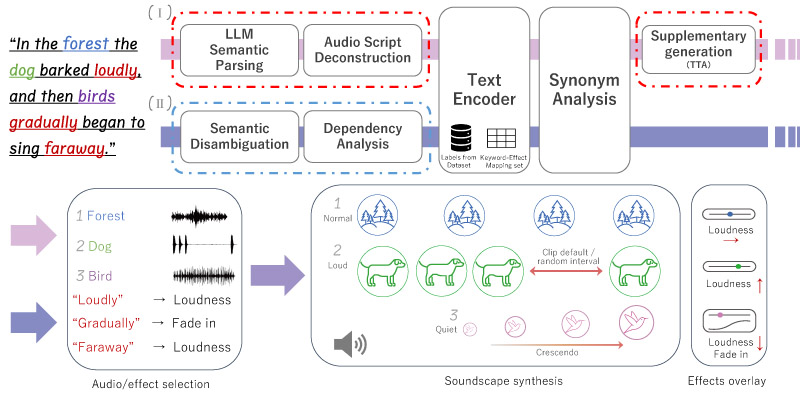
Overview of the proposed soundscape generation framework
- [1] B. Elizalde et al., “CLAP Learning Audio Concepts from Natural Language Supervision,” 2023 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2023), 2023. https://doi.org/10.1109/ICASSP49357.2023.10095889
- [2] R. Huang et al., “AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head,” Proc. of the AAAI Conf. on Artificial Intelligence, Vol.38, No.21, pp. 23802-23804, 2024. https://doi.org/10.1609/aaai.v38i21.30570
- [3] H.-H. Wu et al., “Audio-Text Models Do Not Yet Leverage Natural Language,” 2023 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2023), 2023. https://doi.org/10.1109/ICASSP49357.2023.10097117
- [4] B. C. Pijanowski et al., “Soundscape Ecology: The Science of Sound in the Landscape,” BioScience, Vol.61, Issue 3, pp. 203-216, 2011. https://doi.org/10.1525/bio.2011.61.3.6
- [5] J. Chen and X. Lehto, “The impact of sound design with AI synthetic voices on the listening experience in audio tour guides,” Information Technology & Tourism, Vol.27, pp. 1081-1109, 2025. https://doi.org/10.1007/s40558-025-00332-4
- [6] A. Hurst et al., “GPT-4o System Card,” arXiv preprint, arXiv:2410.21276, 2024. https://doi.org/10.48550/arXiv.2410.21276
- [7] J. Huang et al., “Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation,” arXiv preprint, arXiv:2305.18474, 2023. https://doi.org/10.48550/arXiv.2305.18474
- [8] H. Liu et al., “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models,” arXiv preprint, arXiv:2301.12503, 2023. https://doi.org/10.48550/arXiv.2301.12503
- [9] J. Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 4171-4186, 2019. https://doi.org/10.18653/v1/N19-1423
- [10] R. Huang et al., “Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,” Proc. of the 40th Int. Conf. on Machine Learning, Article No.565, 2023.
- [11] R. Lindholm et al., “Aggregation Strategies for Efficient Annotation of Bioacoustic Sound Events Using Active Learning,” arXiv preprint, arXiv:2503.02422, 2025. https://doi.org/10.48550/arXiv.2503.02422
- [12] I. Martín-Morató, M. Harju, and A. Mesaros, “Crowdsourcing Strong Labels for Sound Event Detection,” 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pp. 246-250, 2021. https://doi.org/10.1109/WASPAA52581.2021.9632761
- [13] J. Salamon et al., “Scaper: A library for soundscape synthesis and augmentation,” 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), pp. 344-348, 2017. https://doi.org/10.1109/WASPAA.2017.8170052
- [14] X. Xu et al., “Text-to-Audio Grounding: Building Correspondence Between Captions and Sound Events,” 2021 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2021), pp. 606-610, 2021. https://doi.org/10.1109/ICASSP39728.2021.9414834
- [15] F. Ronchini, L. Comanducci, and F. Antonacci, “Synthetic training set generation using text-to-audio models for environmental sound classification,” arXiv preprint, arXiv:2403.17864, 2024. https://doi.org/10.48550/arXiv.2403.17864
- [16] A. Gunduz et al., “An Automated End-to-End Open-Source Software for High-Quality Text-to-Speech Dataset Generation,” arXiv preprint, arXiv:2402.16380, 2024. https://doi.org/10.48550/arXiv.2402.16380
- [17] A. Agostinelli et al., “MusicLM: Generating Music from Text,” arXiv preprint, arXiv:2301.1132, 2023. https://doi.org/10.48550/arXiv.2301.11325
- [18] Z. Borsos et al., “SoundStorm: Efficient Parallel Audio Generation,” arXiv preprint, arXiv:2305.09636, 2023. https://doi.org/10.48550/arXiv.2305.09636
- [19] F. Kreuk et al., “AudioGen: Textually Guided Audio Generation,” arXiv preprint, arXiv:2209.15352, 2022. https://doi.org/10.48550/arXiv.2209.15352
- [20] L. Huang et al., “A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions,” ACM Trans. on Information Systems, Vol.43, Issue 2, Article No.42, 2025. https://doi.org/10.1145/3703155
- [21] K. Drossos, S. Lipping, and T. Virtanen, “Clotho: An Audio Captioning Dataset,” 2020 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP 2020), pp. 736-740, 2020. https://doi.org/10.1109/ICASSP40776.2020.9052990
- [22] C. D. Kim et al., “AudioCaps: Generating Captions for Audios in The Wild,” Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol.1 (Long and Short Papers), pp. 119-132, 2019. https://doi.org/10.18653/v1/N19-1011
- [23] S. Mpouli, C. Largeron, and M. Beigbeder, “Identifying sound descriptions in Written Documents,” 2019 13th Int. Conf. on Research Challenges in Information Science (RCIS), 2019. https://doi.org/10.1109/RCIS.2019.8876975
- [24] T. Bänziger and K. R. Scherer, “The role of intonation in emotional expressions,” Speech Communication, Vol.46, Issues 3-4, pp. 252-267, 2005. https://doi.org/10.1016/j.specom.2005.02.016
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.