Research Paper:
Speech-Section Extraction Using Lip Movement and Voice Information in Japanese
Etsuro Nakamura*, Yoichi Kageyama*,†, and Satoshi Hirose**
*Graduate School of Engineering Science, Akita University
1-1 Tegata Gakuen-Machi, Akita 010-8502, Japan
**Japan Business Systems, Inc.
1-23-1 Toranomon, Minato-ku, Tokyo 105-6316, Japan
†Corresponding author

In recent years, several Japanese companies have attempted to improve the efficiency of their meetings, which has been a significant challenge. For instance, voice recognition technology is used to considerably improve meeting minutes creation. In an automatic minutes-creating system, identifying the speaker to add speaker information to the text would substantially improve the overall efficiency of the process. Therefore, a few companies and research groups have proposed speaker estimation methods; however, it includes challenges, such as requiring advance preparation, special equipment, and multiple microphones. These problems can be solved by using speech sections that are extracted from lip movements and voice information. When a person speaks, voice and lip movements occur simultaneously. Therefore, the speaker’s speech section can be extracted from videos by using lip movement and voice information. However, when this speech section contains only voice information, the voiceprint information of each meeting participant is required for speaker identification. When using lip movements, the speech section and speaker position can be extracted without the voiceprint information. Therefore, in this study, we propose a speech-section extraction method that uses image and voice information in Japanese for speaker identification. The proposed method consists of three processes: i) the extraction of speech frames using lip movements, ii) the extraction of speech frames using voices, and iii) the classification of speech sections using these extraction results. We used video data to evaluate the functionality of the method. Further, the proposed method was compared with state-of-the-art techniques. The average F-measure of the proposed method is determined to be higher than that of the conventional methods that are based on state-of-the-art techniques. The evaluation results showed that the proposed method achieves state-of-the-art performance using a simpler process compared to the conventional method.
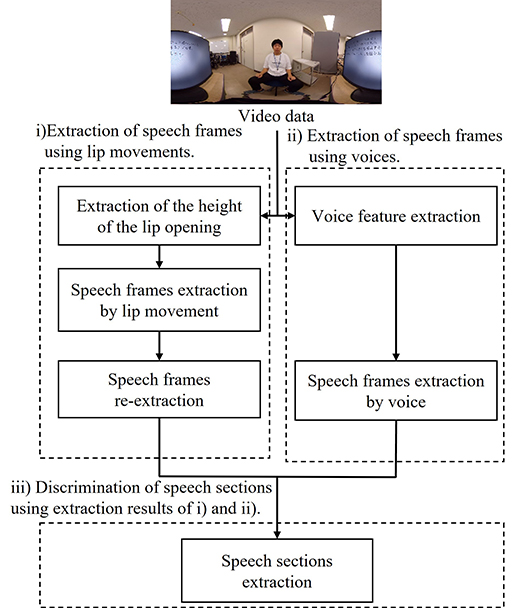
The speech-section extraction method
- [1] S. Han, Z. Yang, Q. Li, and Y. Chen, “Deformed landmark fitting for sequential faces,” J. Vis. Commun. Image Represent., Vol.62, pp. 381-393, 2019.
- [2] Z. Meng, M. U. B. Altaf, and B.-H. Juang, “Active voice authentication,” Digit. Signal Process., Vol.101, Article No.102672, 2020.
- [3] Y. Shi, Z. Zhang, H. Kaining, W. Ma, and S. Tu, “Human-computer interaction based on face feature localization,” J. Vis. Commun. Image Represent., Vol.70, Article No.102740, 2020.
- [4] R. Kharghanian, A. Peiravi, F. Moradi, and A. Iosifidis, “Pain detection using batch normalized discriminant restricted Boltzmann machine layers,” J. Vis. Commun. Image Represent., Vol.76, Article No.103062, 2021.
- [5] A. Othmani, A. R. Taleb, H. Abdelkawy, and A. Hadid, “Age estimation from faces using deep learning: A comparative analysis,” Comput. Vis. Image Underst., Vol.196, Article No.102961, 2020.
- [6] M. Bonomi, C. Pasquini, and G. Boato, “Dynamic texture analysis for detecting fake faces in video sequences,” J. Vis. Commun. Image Represent., Vol.79, Article No.103239, 2021.
- [7] R. A. Virrey, C. D. S. Liyanage, M. I. b. P. H. Petra, and P. E. Abas, “Visual data of facial expressions for automatic pain detection,” J. Vis. Commun. Image Represent., Vol.61, pp. 209-217, 2019.
- [8] D. T. Long, “A Facial Expressions Recognition Method Using Residual Network Architecture for Online Learning Evaluation,” J. Adv. Comput. Intell. Intell. Inform., Vol.25, No.6, pp. 953-962, 2021.
- [9] C. Liu, K. Hirota, B. Wang, Y. Dai, and Z. Jia, “Two-Channel Feature Extraction Convolutional Neural Network for Facial Expression Recognition,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.6, pp. 792-801, 2020.
- [10] D. N. Anh, “Interestingness Improvement of Face Images by Learning Visual Saliency,” J. Adv. Comput. Intell. Intell. Inform., Vol.24, No.5, pp. 630-637, 2020.
- [11] Keidanren Japan Business Federation, “Survey on working hours in 2019 Aggregate results,” (in Japanese) http://www.keidanren.or.jp/policy/2019/076.pdf [Accessed November 6, 2021]
- [12] NEC Solution Innovators, Ltd., “Voice recognition and minutes creation support, solution VoiceGraphy,” https://www.nec-solutioninnovators.co.jp/ss/smartwork/products/voicegraphy/ [Accessed November 6, 2021]
- [13] Microsoft, “Speaker Recognition,” https://azure.microsoft.com/ja-jp/services/cognitive-services/speaker-recognition/ [Accessed November 6, 2021]
- [14] X. Wang, F. Xue, W. Wang, and A. Liu, “A network model of speaker identification with new feature extraction methods and asymmetric BLSTM,” Neurocomputing, Vol.403, pp. 167-181, 2020.
- [15] R. Peri, M. Pal, A. Jati, K. Somandepalli, and S. Narayanan, “Robust Speaker Recognition Using Unsupervised Adversarial Invariance,” Proc. ICASSP IEEE Int. Conf. Acoust. Speech Signal Process., pp. 6614-6618, 2020.
- [16] F. Grondin and F. Michaud, “Lightweight and optimized sound source localization and tracking methods for open and closed microphone array configurations,” Rob. Auton. Syst., Vol.113, pp. 63-80, 2019.
- [17] C. Sagonas, E. Antonakos, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 Faces In-The-Wild Challenge: Database and Results,” Image Vis. Comput., Vol.47, pp. 3-18, 2016.
- [18] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “A Semi-Automatic Methodology for Facial Landmark Annotation,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 5th Workshop on Analysis and Modeling of Faces and Gestures (AMFG), pp. 896-903, 2013.
- [19] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 Faces in-the-Wild Challenge: The First Facial Landmark Localization Challenge,” Proc. IEEE Int. Conf. Comput. Vis. Workshops, pp. 397-403, 2013.
- [20] E. Nakamura, T. Takahashi, Y. Kageyama, M. Ishii, and M. Nishida, “Automatic Extraction of Lip Shape Using Feedforward Neural Network,” IEEJ Trans. Electron. Inf. Syst., Vol.138, No.12, pp. 1604-1612, 2018 (in Japanese).
- [21] E. Nakamura, T. Takahashi, Y. Kageyama, M. Ishii, M. Nishida, and M. Shirasu, “Shadow Removing Method for Lip Shape Extraction Using Feedforward Neural Network,” IEEE 1st Glob. Conf. Life Sci. Technol. (LifeTech), pp. 87-88, 2019.
- [22] J. S. Chung and A. Zisserman, “Out of time: automated lip sync in the wild,” Asian Conf. on Computer Vision, pp. 251-263, 2016.
- [23] J. S. Chung and A. Zisserman, “Learning to lip read words by watching videos,” Comput. Vis. Image Underst., Vol.173, pp. 76-85, 2018.
- [24] D. Doukhan, E. Lechapt, M. Evrard, and J. Carrive, “Ina’s Mirex 2018 Music and Speech Detection System,” Conf. Music Information Retrieval Evaluation eXchange, https://www.music-ir.org/mirex/abstracts/2018/DD1.pdf, 2018.
- [25] A. Lee and T. Kawahara, “Recent Development of Open-Source Speech Recognition Engine Julius,” Procs. Asia-Pacific Signal and Information Processing Association Annual Summit and Conf. (APSIPA ASC), pp. 131-137, 2009.
- [26] E. Nakamura, Y. Kageyama, and S. Hirose, “Speech Section Extraction Method Using Image and Voice Information,” Proc. of the 9th IIAE Int. Conf. on Industrial Application Engineering (ICIAE), pp. 30-34, 2021.
- [27] E. Nakamura, Y. Kageyama, and S. Hirose, “LSTM-Based Japanese Speaker Identification Using an Omnidirectional Camera and Voice Information,” IEEJ Trans. Electr. Electron. Eng., Vol.17, No.5, pp. 674-684, 2022.
- [28] Ricoh Co., Ltd., “RICOH THETA lineup comparison,” https://theta360.com/ja/about/theta/v.html [Accessed November 6, 2021]
- [29] Ricoh Co., Ltd., “3D microphone TA-1,” https://ricohimagingstore.com/3d-mic-ta-1-s0910754.html [Accessed November 6, 2021]
- [30] Davis E. King “Dlib C++ Library,” http://dlib.net/ [Accessed November 6, 2021]
- [31] S. Hurui, “Digital sound processing,” Tokai University Press, 2001 (in Japanese).
- [32] K. Shinoda, “Voice recognition,” Kodansha, 2017 (in Japanese).
- [33] T. Harada, “Image recognition,” Kodansha, 2018 (in Japanese).
- [34] David Doukhan, “inaSpeechSegmenter,” https://github.com/ina-foss/inaSpeechSegmenter [Accessed April 16, 2022]
This article is published under a Creative Commons Attribution-NoDerivatives 4.0 Internationa License.